Attention Patterns in Large Language Models: How Syntax, Semantics, and Long-Range Dependencies Shape AI Language
 Feb, 21 2026
Feb, 21 2026
When you ask a large language model like ChatGPT to finish the sentence "The best thing about ChatGPT is its ability to," it doesn’t just guess the next word randomly. It looks back at everything you’ve typed, weighs each word’s importance, and figures out what makes sense-not just grammatically, but meaningfully. This isn’t magic. It’s attention. And understanding how attention works inside these models reveals why they can write essays, answer complex questions, and even follow multi-step instructions across thousands of words.
How Attention Works in Transformers
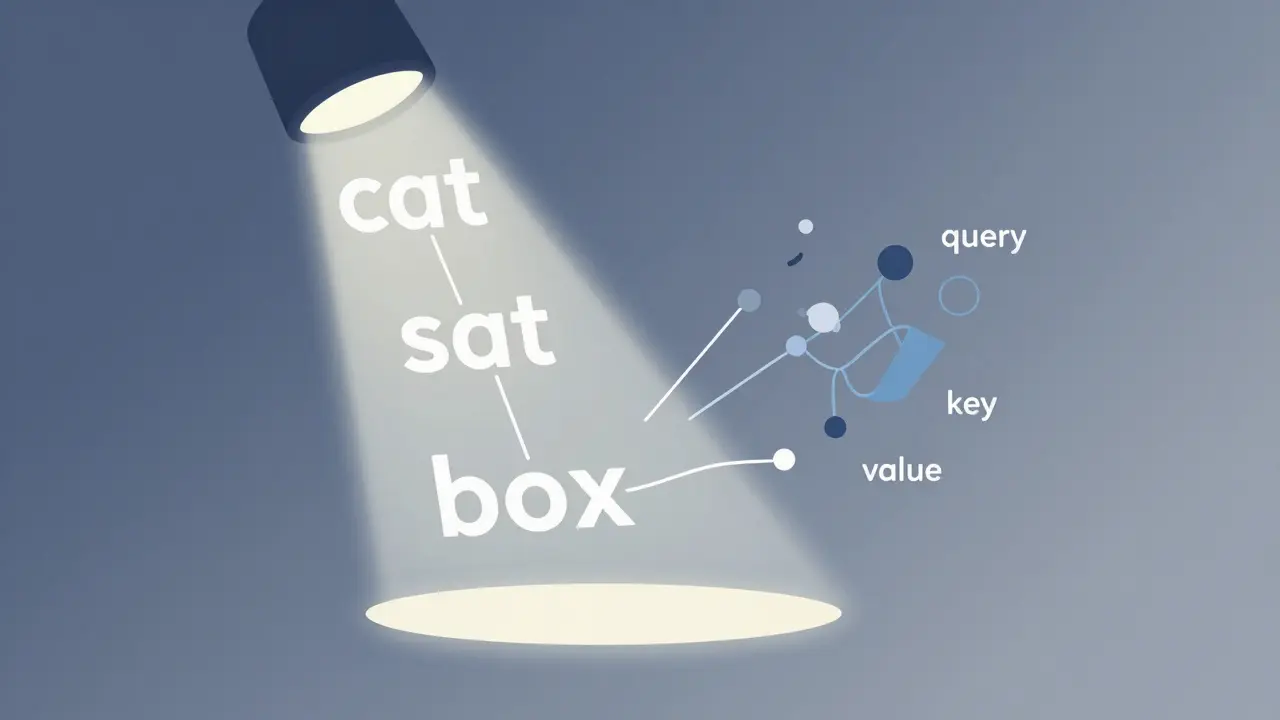
Large language models are built on transformer architecture, and at the heart of every transformer is the attention mechanism. Think of attention like a spotlight that shifts across a sentence, highlighting the most relevant words for the task at hand. When the model processes a sentence like "The cat sat on the box, which was too heavy for the dog to move," it doesn’t just see the words one after another. It calculates how each word relates to every other word-nearby or far away.
This happens through three key components: queries, keys, and values. Each word is turned into a vector-a list of numbers representing its meaning. The model then asks: "How does this word connect to others?" The query asks about the current word, the key tells it what other words are available, and the value holds the actual meaning. By multiplying query and key, the model gets an attention score: a number that says how much focus to give to each word.
Unlike older models like LSTMs, which process words one at a time, transformers handle everything in parallel. That’s why they’re faster and better at handling long texts. But here’s the catch: attention alone doesn’t know where words are. It sees relationships, but not order. A model might understand that "cat" and "sat" are connected, but without extra help, it wouldn’t know if the cat sat before or after the box appeared.
Breaking Down Syntax and Semantics
Syntax is the grammar of language-the rules for how words fit together. "She runs fast" works. "Runs she fast" doesn’t. Large language models learn syntax by scanning billions of sentences. They don’t memorize grammar rules. Instead, they notice patterns: verbs usually follow subjects, adjectives usually come before nouns. Over time, they build a statistical sense of what sounds right.
But syntax isn’t enough. Semantics is about meaning. If I say "The table drank the coffee," the grammar is fine, but the meaning is nonsense. Humans know coffee can’t be drunk by tables because we have a mental model of the world. Do LLMs have that? Not really. They don’t understand coffee or tables. But they’ve seen enough examples of what people say about drinks and furniture to guess that "the coffee was drunk by the woman" is far more likely than the table version.
Attention helps here too. When a model sees "The chef seasoned the steak with salt," it doesn’t just match words. It links "seasoned" to "steak" and "salt" based on how often those relationships appear in training data. The attention mechanism lets it connect the verb to its object and its instrument-even if they’re separated by other words.
The Problem with Long-Range Dependencies
Long-range dependencies are the hardest part of language. Imagine reading a 10,000-word legal contract. The first paragraph mentions "Party A," and halfway through, it says "Party A must submit the report by Friday." The model needs to remember who Party A is-even though dozens of other names and clauses appeared in between.
Standard transformers struggle here. They use positional encodings-fixed numbers added to word vectors to indicate position. Think of it like tagging each word with a number: word 1, word 2, word 3, and so on. But this system is rigid. If a sentence is rearranged, or if the context shifts, the model doesn’t adapt. It treats position as geometry, not meaning.
This is why models sometimes forget the subject of a sentence after 500 words. Or why they mix up pronouns in long stories. The attention mechanism sees all words at once, but without a way to track how meaning evolves over distance, it loses track.

PaTH Attention: A New Way to Track Meaning
In December 2025, researchers at MIT and the MIT-IBM Watson AI Lab introduced a breakthrough called PaTH Attention. Instead of using fixed position numbers, PaTH treats the sequence of words like a path. Each step along the path adjusts how the model interprets what comes next.
Here’s how it works: Each word doesn’t just get a position number. It gets a transformation-a small, data-dependent change that depends on the meaning of the word and what came before it. These transformations use a mathematical operation called a Householder reflection, which acts like a mirror. The mirror doesn’t reflect everything the same way. It adjusts based on the content. So if the previous word was "he" and the next is "ran", the transformation helps the model remember that the subject is still "he." If the next word is "she," the mirror flips again.
This isn’t just about distance. It’s about contextual flow. The model doesn’t just know that word 3,000 is far from word 1. It knows that the meaning changed between them. In a story where "John bought a car," then "He sold it," PaTH Attention remembers that "He" still refers to John, even after 50 intervening sentences.
Testing showed PaTH Attention outperformed older methods like RoPE (Rotary Position Embedding) on tasks that required tracking entities, following instructions, and recalling details over tens of thousands of tokens. In one test, models had to remember which command was last given after 100 confusing steps. Standard models failed. PaTH models got it right 87% of the time.
PaTH-FoX: Forgetting What Doesn’t Matter
PaTH Attention alone is powerful, but researchers didn’t stop there. They combined it with another idea called Forgetting Transformer (FoX). The idea? Not all information is equally important. Humans don’t remember every detail of a conversation. We forget the irrelevant bits.
FoX lets the model learn to down-weight older or less relevant information. If a document mentions "the meeting on Monday" and then talks about "the project deadline" for 50 paragraphs, FoX gently fades the Monday reference. But if later it says "As planned on Monday," FoX revives it. This isn’t memory. It’s intelligent relevance.
Together, PaTH-FoX creates a system that doesn’t just track meaning-it filters it. This is closer to how humans think. We don’t store every word. We store patterns, shifts, and priorities. PaTH-FoX starts to mimic that.
Why This Matters Beyond Text
These advances aren’t just about writing better chatbots. They’re about building AI that can handle real-world complexity. Imagine an AI reading a medical record: patient history, drug interactions, lab results over years. Or analyzing a legal contract with hundreds of amendments. Or tracking variables in a 20,000-line codebase.
Current models can’t reliably do this. They hallucinate, forget, or mislink entities. PaTH Attention changes that. It gives models a sense of temporal awareness-not just where words are, but how meaning moves through them.
Researchers are already testing PaTH in biology, looking at protein sequences and DNA patterns. If a gene’s function changes after a mutation, can the model track that shift? Traditional attention can’t. PaTH might.
The Bigger Picture
Attention isn’t just a technical detail. It’s the bridge between raw text and real understanding. Syntax tells us what structure looks like. Semantics tells us what it means. Long-range dependencies tell us how meaning unfolds over time. And PaTH Attention? It’s the first mechanism that starts to handle all three together.
Large language models still don’t think like humans. But with PaTH, they’re getting closer to how we process language-not by memorizing rules, but by adapting to context, remembering what matters, and letting go of what doesn’t.
This isn’t the end of the journey. But it’s the clearest sign yet that attention mechanisms are evolving-from static, position-based tools into dynamic, meaning-aware systems. And that change will shape the next generation of AI.
How do attention mechanisms differ from traditional models like LSTMs?
LSTMs process text one word at a time, in sequence, which makes them slow and poor at capturing long-range relationships. Attention mechanisms, especially in transformers, look at all words in a sentence simultaneously. This lets them weigh the importance of any word relative to any other word, no matter how far apart they are. That’s why transformers handle long documents and complex dependencies much better.
Why can’t standard attention mechanisms track word order properly?
Standard attention doesn’t inherently know where words are in a sequence. It only sees relationships between words, not their positions. To fix this, models add fixed positional encodings-like numbering each word. But these numbers don’t change based on context. If a sentence is reordered or meaning shifts, the model can’t adapt. That’s why models often mix up pronouns or lose track of subjects over long texts.
What is PaTH Attention, and how is it different from RoPE?
RoPE (Rotary Position Embedding) assigns each word a fixed rotation based on its distance from the start. It’s better than simple numbering, but still static. PaTH Attention treats word positions as a dynamic path. Each word transforms how the model interprets the next one, using context-aware adjustments called Householder reflections. This lets the model track how meaning evolves-not just how far apart words are.
Can PaTH Attention improve how AI understands code or scientific data?
Yes. Researchers are already testing PaTH in domains like biology and programming. In code, variable names change meaning across functions. In DNA sequences, a mutation’s effect depends on surrounding context. PaTH’s ability to adaptively track how meaning shifts over distance makes it far better suited than older methods for these structured, long-range tasks.
Does PaTH Attention mean LLMs now understand language like humans?
No. LLMs still don’t have consciousness, intent, or real-world experience. But PaTH Attention gives them a more human-like way of processing language: they adapt, remember what matters, and let go of what doesn’t. It’s not understanding-it’s better pattern tracking. And that’s a huge leap forward.
Sara Escanciano
February 22, 2026 AT 04:13Let's be real-this 'PaTH Attention' nonsense is just academic theater. Companies have been deploying attention mechanisms in production for years, and none of this 'Householder reflection' garbage was needed. The real problem isn't attention-it's data quality. If your model forgets 'Party A' after 500 words, you didn't train it right. Stop inventing math to cover up lazy engineering.
Also, calling this 'closer to human processing'? Humans don't use matrix transformations to remember who drank the coffee. We use context, experience, and common sense. This isn't progress. It's obfuscation dressed up as innovation.
Kelley Nelson
February 22, 2026 AT 04:54One must, with the utmost intellectual rigor, acknowledge the profound epistemological implications of the PaTH-FoX architecture. The introduction of context-aware, dynamically adaptive transformations-particularly through the application of Householder reflections-represents not merely an incremental improvement, but a paradigmatic shift in the ontological framing of sequential token processing.
Whereas conventional positional encodings posit a static, Euclidean metric upon which syntactic dependencies are superimposed, PaTH introduces a non-Euclidean manifold of semantic trajectory, wherein meaning is not merely tracked but co-constituted through recursive, context-sensitive transformations. The elegance of this formulation lies in its rejection of Cartesian linearity in favor of a hermeneutic continuum-wherein the past is not remembered, but re-actualized in the present moment of inference.
Aryan Gupta
February 23, 2026 AT 13:27Oh wow, another 'breakthrough' from MIT that's just a fancy way of saying 'we added more layers and called it math'.
Let me guess-this 'PaTH' thing is secretly funded by the same people who brought you GPT-4 Turbo. You think we don't know that 'Householder reflections' are just a distraction? Real AI doesn't need 100,000-token memory. It needs to stop hallucinating that 'the cat sat on the box' means the box is alive.
And don't even get me started on FoX. 'Intelligent forgetting'? That's just what happens when you delete your training data after 3 months and call it 'privacy compliance'.
Also, who approved this paper? I'm 90% sure the lead author is a grad student who just learned linear algebra last semester. The math looks right, but the intuition? Pure fiction.
Fredda Freyer
February 23, 2026 AT 17:46This is actually one of the most thoughtful advances in transformer architecture I've seen in years.
Traditional attention is like reading a book with a highlighter-you mark everything equally. PaTH is like having a librarian who remembers not just where you were, but why you cared about that passage. The Householder reflection isn't just a math trick-it's a metaphor for how humans update mental models.
Think about it: when you hear 'he' in a novel, you don't just count words back to the last name. You reconstruct the narrative thread: Who was last acting? What were their goals? What changed since last mention?
FoX is even more brilliant. Humans don't remember everything. We remember what matters. If a character says 'I'll call you tomorrow' and then disappears for 200 pages, we don't keep that thread alive unless it's relevant. FoX does the same. It's not forgetting-it's prioritizing.
This isn't about scale. It's about coherence. And that's what makes language meaningful. We don't need more tokens-we need better tracking.
I'm excited to see this applied to medical records. Imagine an AI that doesn't just list symptoms, but understands how a patient's condition evolved over time. That's not prediction. That's narrative comprehension.
And yes, this still isn't consciousness. But it's the closest we've come to building a machine that doesn't just repeat, but responds.
Zelda Breach
February 24, 2026 AT 12:06Oh please. 'PaTH Attention'? More like 'Pathetic Attention'. You people are so desperate to sound smart you're inventing buzzwords to describe what's basically a glorified state machine.
Let me break it down for you: if your model forgets 'Party A' after 500 words, that's not a flaw in attention-it's a flaw in training. You trained it on garbage data and now you want to fix it with math? No. You need better data, better filters, better curation. Not more layers.
And 'FoX'? 'Intelligent forgetting'? That's just what happens when you delete your training data and say 'it's privacy'.
Also, who let a bunch of MIT grads publish this without peer review from someone who's actually built a real system? This reads like a grant proposal with extra equations.
Real engineers don't need Householder reflections. They need better datasets. And maybe a reality check.
Alan Crierie
February 25, 2026 AT 08:03Just wanted to say-this is beautiful. 🌟
PaTH Attention feels like the first time an AI model truly *listened* instead of just parsing. The idea that meaning evolves, and that the model should adapt its internal compass based on context-not just position-is so deeply human. It reminds me of how we recall conversations: not by counting words, but by feeling the emotional and logical flow.
I’ve worked with LLMs for years, and I’ve seen so many models lose track of pronouns, flip subjects, or ignore earlier instructions. This isn’t just a technical upgrade-it’s a philosophical one. We’re moving from ‘pattern matching’ to ‘narrative continuity’.
And FoX? The gentle fading of irrelevant details? That’s not forgetting. That’s wisdom.
Thank you to the researchers for building something that doesn’t just scale, but *senses*. This gives me hope for AI that doesn’t overwhelm us with noise-but helps us find meaning.
Also, if anyone’s building a version for poetry analysis… I’d love to beta test it. 📖✨
Gareth Hobbs
February 25, 2026 AT 19:13UK here. Honestly, this 'PaTH' thing smells like American overengineering. We had perfectly good attention mechanisms in the 2010s. Why do you Yanks need to add 'Householder reflections' just to make yourselves look smart?
Also, 'FoX'? Sounds like a typo. Did you mean 'Fox'? As in... the animal? Or... the news channel?
And don't get me started on 'meaningful flow'. We don't need AI to 'understand meaning'. We need it to stop making up facts. This isn't philosophy class. It's engineering.
Also, who approved this paper? I'm 90% sure the lead author went to Harvard and thinks 'transformer' is a train. Real engineers in the UK just use RNNs with dropout and call it a day. Works fine. No math needed.
PS: The spelling of 'Paradigmatic' in the elitist comment above? Should be 'paradigmatic'. Just sayin'. 😏