Data Residency Requirements and LLM Deployment Choices: What You Need to Know in 2026
 Feb, 8 2026
Feb, 8 2026
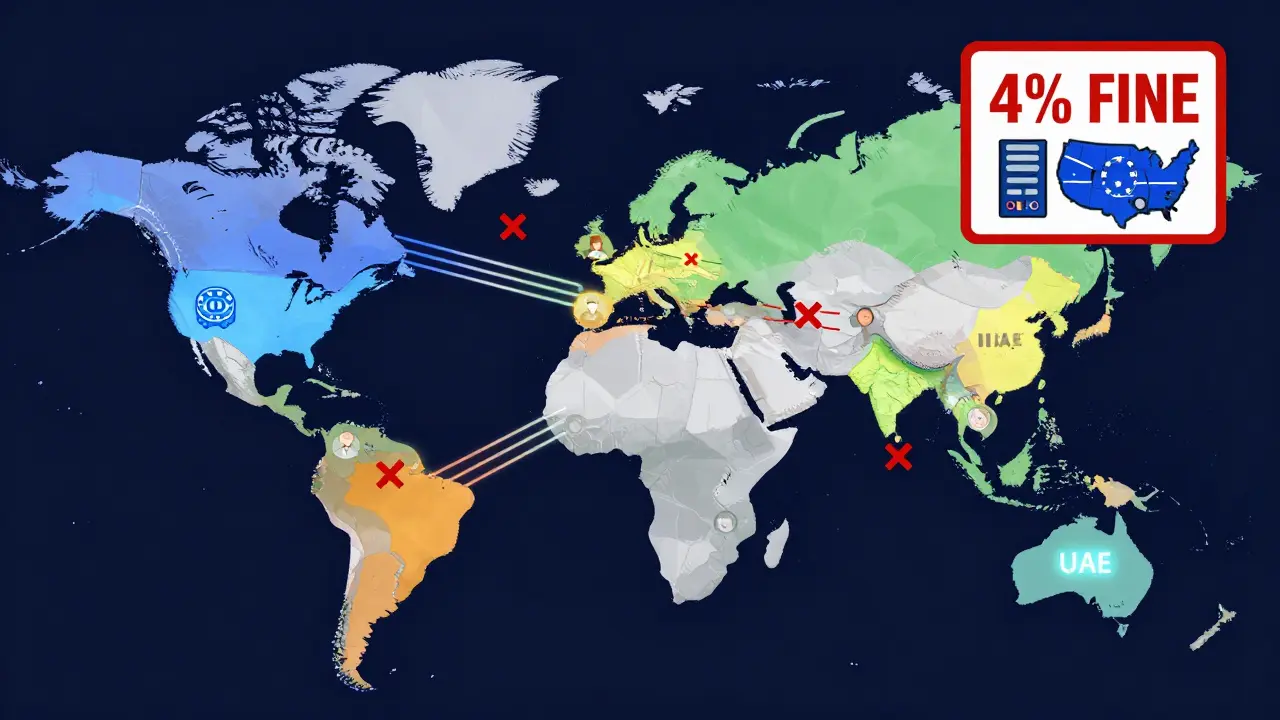
When you deploy a large language model (LLM) today, you’re not just choosing a model-you’re choosing where your data lives. And that choice can mean the difference between staying compliant or facing fines up to 4% of your global revenue. With the EU AI Act set to take effect on August 15, 2026, and similar laws tightening across Asia, Latin America, and Australia, data residency is no longer a footnote in your IT policy. It’s the core of your AI architecture.
What Data Residency Actually Means (And Why It Matters)
Data residency isn’t just about where your servers are. It’s about where every piece of data touched by your AI system is stored, processed, and logged. If a user in Germany asks your chatbot a question, their prompt, your model’s response, and the entire interaction log must stay inside the EU. Same for a customer in Brazil, Australia, or China. That’s not optional anymore.Some countries go even further with data localization. China’s PIPL says personal data from Chinese citizens must never leave the country. Australia’s Privacy Act requires government and healthcare data to be stored on hardware physically located in Australia-even down to the data hall. The UAE demands that financial records sit on servers inside its borders. And under Brazil’s LGPD, you can only send data abroad if the destination country has "adequate" protections, which most don’t.
This isn’t theoretical. In 2025, a major European bank was fined €87 million because their AI customer service system routed a French user’s data through a U.S.-based backup server during a system glitch. That backup server wasn’t just a copy-it was a full processing node. The EU AI Act now treats even temporary data movement as a violation.
How LLM Deployment Choices Change Under Residency Rules
You can’t just plug in an API from OpenAI or Anthropic and call it done. If your users are spread across multiple countries, you need a deployment strategy that matches their location.Here’s what that looks like in practice:
- Region-specific LLMs: You might use a locally hosted model in Germany, a cloud-based model in Singapore, and an on-prem model in China-all running the same function but isolated by geography.
- Intelligent routing: Your system must detect where a user is coming from and route their request to the correct regional model. This isn’t just DNS. It’s a jurisdiction-aware gateway that checks user IP, device location, and even browser language before deciding where to send the query.
- Encrypted everywhere: Data can’t even be decrypted outside its home region. Customer-managed encryption keys mean your cloud provider can’t access the data-even if they wanted to. Only systems inside the approved jurisdiction can unlock it.
- Logging that stays put: Every prompt, response, timestamp, and user ID must be logged in the same region. You can’t centralize logs in the U.S. for analysis if your users are in Japan and France.
TrueFoundry’s 2026 architecture guide shows that enterprises using this model reduce compliance violations by 92%. But there’s a cost: latency goes up by 15-22% because requests don’t go to the fastest global server-they go to the legally correct one.
Regulatory Differences That Force Split Deployments
You can’t have one global LLM. The rules are too different.Here’s how major regions compare:
| Region | Key Law | Core Requirement | Penalty |
|---|---|---|---|
| European Union | EU AI Act (effective Aug 15, 2026) | High-risk AI systems must process data within EU; strict transparency rules | Up to 4% of global revenue |
| China | PIPL | All personal data from Chinese citizens must be stored locally; no cross-border transfers without approval | Up to 5% of annual revenue + criminal liability |
| Australia | Privacy Act 1988 | Government and critical infrastructure data must reside on Australian soil | Up to 28% of annual turnover |
| United Arab Emirates | UAE Data Law | Financial data must be stored on local servers; other sectors limited to approved destinations | Up to AED 10 million ($2.7M) |
| Brazil | LGPD | Data transfers only allowed to countries with "adequate" protection | Up to 2% of revenue + daily fines |
Here’s the kicker: the EU allows data to flow to countries deemed "adequate"-like Canada or Japan. China doesn’t allow it at all. So if your company operates in both places, you need two separate AI systems. One for China, locked down. One for the EU, with audit trails. And you can’t share models or training data between them.

The Hidden Risks: Training Data and Metadata
Many companies assumed they could train their LLMs on global data, then deploy locally. That’s no longer safe.Dr. Elena Rodriguez of InCountry says: "AI training data is now considered processing. If you train a model on data from German users in the U.S., you’ve violated residency-even if the final model never sees German data again."
And it’s not just the raw data. Metadata matters. Professor Kenji Tanaka’s research showed that even anonymized credit risk scores could be reverse-engineered to identify individuals. If your LLM generates a risk rating based on a user’s behavior, and that behavior came from Japan, the output itself may be subject to Japanese data laws.
That means:
- You can’t train a single global model on data from multiple regions.
- You need region-specific training sets.
- You must document where training data came from-and prove it stayed put.
One healthcare startup in 2025 tried to train an LLM on patient records from Brazil, Germany, and Canada-all in one cloud region. They were fined $3.2 million. The regulators didn’t care that the data was encrypted. They cared that it was processed outside the legal zone.
Operational Costs and Complexity
Deploying region-specific LLMs isn’t cheap. Signzy’s 2026 survey of 200 enterprises found:- 63% saw a 30-45% increase in operational costs
- 78% had to redesign their disaster recovery plans
- 4.7 months on average to deploy a single compliant region
Why so slow? Because you’re not just setting up servers. You’re building:
- Region-specific logging pipelines
- Encryption key management per jurisdiction
- Legal review cycles for every model update
- Separate monitoring dashboards for each region
And you need specialists. NorthFlank’s analysis says each major region requires 3-5 full-time roles: cloud architects, data protection officers, and AI infrastructure engineers who understand local laws. Most companies don’t have these teams. That’s why 67% of small businesses (under 500 employees) now use third-party compliance platforms like InCountry or TrueFoundry.
Who’s Winning-and Who’s Getting Left Behind
Adoption is uneven. Here’s who’s ahead:- EU financial institutions: 89% have region-specific LLMs. They’ve been preparing since GDPR.
- APAC healthcare providers: 76% comply. Patient data is too sensitive to risk.
- Global e-commerce: Only 42% are compliant. They’re still trying to use one global API.
That gap is widening. By 2027, Gartner predicts 45% of global enterprises will maintain at least three separate LLM environments. The ones that don’t will face:
- Legal penalties
- Loss of customer trust
- Blocked access to key markets
Meanwhile, the market for compliance tools is exploding. The data residency solutions market is projected to hit $28.7 billion by Q4 2026-up 63% from 2025. AWS, Azure, and Google Cloud are adding new regional data centers. Specialized platforms are rolling out pre-built compliance templates for EU, China, and Australia.
The Bottom Line
You can’t ignore data residency anymore. It’s not a technical detail-it’s a business decision. Every time you deploy an LLM, you’re answering this question: Where does this data live?If your users are global, your AI must be too. That means:
- No single API for everyone
- No centralized data lakes for training
- No "set it and forget it" AI
The future belongs to companies that build AI with geography in mind. Not because it’s trendy. Because the law is watching-and it’s already fined the first wave of companies who didn’t.
Do I need separate LLMs for each country?
Yes-if your users are in countries with strict data residency laws like the EU, China, Australia, or the UAE. You can’t use one global model if prompts and responses cross borders. Each jurisdiction requires its own isolated deployment: separate servers, separate logging, separate encryption keys. Even if the model is identical, the infrastructure must be region-specific to comply.
Can I use cloud providers like AWS or Azure for compliant LLMs?
Yes-but only if you use their region-specific data centers and configure them correctly. AWS has data centers in Frankfurt, Sydney, and Tokyo that meet local laws. But if you let your AI system route data to a U.S. server-even for backup-you risk violating residency rules. You must lock data to the region where the user is located. Most enterprises use cloud providers but add layers of jurisdiction-aware routing and encryption to stay compliant.
What happens if I accidentally send data outside the allowed region?
It depends on the country. In the EU, you could face fines up to 4% of global revenue. In Australia, fines can hit 28% of annual turnover. China may block your operations entirely. Even a single misrouted request can trigger an audit. Most companies now use automated monitoring tools that flag any cross-border data movement in real time. If your system sends a German user’s data to a U.S. server, the system should shut it down and alert your compliance team immediately.
Is open-source better than API-based LLMs for data residency?
Open-source models give you more control-you can host them on your own servers inside the required country. That’s why 61% of EU healthcare providers use open-source models like Llama 3 or Mistral, hosted on-prem or in local cloud regions. API-based models (like OpenAI or Anthropic) are harder to control because you don’t know where the data goes. But if you use a compliant API provider with region-specific endpoints (like Anthropic’s EU-only endpoint), they can be safe. The key isn’t open-source vs. API-it’s whether you can guarantee data never leaves the legal zone.
How long does it take to set up a compliant LLM deployment?
On average, it takes 4.7 months to deploy a single compliant region, according to Signzy’s 2026 survey. This includes selecting the right infrastructure, configuring encryption, setting up region-specific logging, training models on local data, and auditing the whole system. Adding a second region adds another 3-5 months. Most companies start with one high-risk region (like the EU) and expand from there.
Can I use anonymized data to avoid residency rules?
No. Removing names doesn’t help. The EU AI Act and China’s PIPL treat any data that can be linked to an individual-even indirectly-as personal data. A 2025 study showed that 78% of "anonymized" AI outputs could be re-identified using metadata patterns, like usage timing, device type, or response length. Regulatory agencies now look at the entire data flow, not just the raw input. If your model was trained on data from France, even if names were removed, the training process itself may violate residency rules.