Distributed Transformer Inference: How Tensor and Pipeline Parallelism Power Large Language Models
 Dec, 14 2025
Dec, 14 2025
Large language models like GPT-4, Llama 3, and Claude 3 don’t run on a single GPU anymore. Not even close. As these models grow past 10 billion, then 70 billion, and now over 100 billion parameters, the math becomes impossible: no single device has enough memory or compute to handle them in production. That’s where distributed transformer inference comes in. It’s not a luxury-it’s the only way these models work at scale today.
Why Single-GPU Inference Is Dead
A 70B-parameter model needs about 140 GB of memory just to hold its weights in 16-bit precision. Even the most powerful consumer GPU, like the NVIDIA RTX 4090 with 24 GB, can’t touch that. Enterprise GPUs like the H100 have 80 GB, but that’s still not enough for models used in real applications. And memory isn’t the only problem. Loading and running a single request through a massive model takes seconds on one GPU. In production, you need to serve hundreds or thousands of requests per second. Single-device inference can’t keep up. Enter distributed inference: splitting the model across multiple GPUs or even CPUs so they work together like a team. Two main techniques make this possible: tensor parallelism and pipeline parallelism. Neither is perfect alone. But together, they unlock what was once science fiction-running trillion-parameter models with low latency and high throughput.Tensor Parallelism: Breaking Down Layers
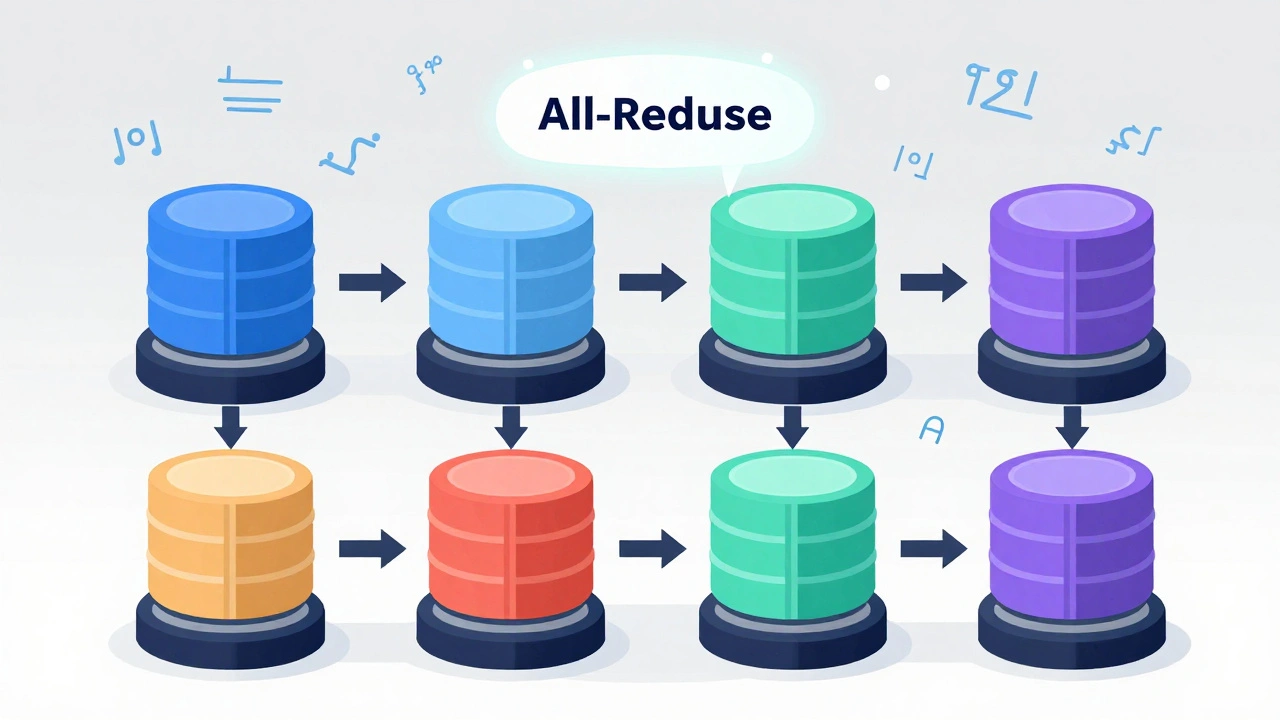
Tensor parallelism cuts up the math inside each transformer layer and spreads it across devices. Think of a transformer’s attention mechanism: it has 32, 64, or even 128 attention heads. Instead of one GPU computing all of them, tensor parallelism assigns 8 heads to each of four GPUs. Each GPU computes its slice of the attention output. Then, all GPUs sync up using an All-Reduce operation to combine their partial results into the final output. This approach keeps latency low because every part of the layer runs in parallel. But it comes with a cost: communication. Every time GPUs need to exchange data, they slow each other down. NVIDIA’s Megatron-LM (2019) showed that as you add more GPUs, the All-Reduce overhead grows fast. At 8 or 16 GPUs, communication can become the bottleneck, eating up 40% or more of your compute time. Still, for single-request inference-like answering a prompt from one user-tensor parallelism is often the best choice. It avoids pipeline bubbles (more on that later) and delivers consistent speed. Frameworks like vLLM and TensorRT-LLM use tensor parallelism heavily, especially for models under 70B parameters. But if you’re running a 130B model? You’ll need more than just tensor parallelism.Pipeline Parallelism: Chaining Layers Like an Assembly Line
Pipeline parallelism takes a different approach. Instead of splitting one layer, it splits the whole model across devices. Layers 1-8 go on GPU 1, layers 9-16 on GPU 2, and so on. Each GPU processes one chunk of the model, then passes the output to the next. It’s like an assembly line: one station does the first step, then hands the part to the next. This method scales much better than tensor parallelism. You can run a 70B model across 8 GPUs without drowning in communication overhead. vLLM’s implementation of pipeline parallelism achieves 45% higher throughput than Hugging Face’s Text Generation Inference on 70B models at batch size 32. But there’s a catch: pipeline bubbles. Imagine the first GPU finishes its work and waits for the second to catch up. While GPU 2 is busy, GPU 1 sits idle. That’s wasted time. The more stages you add, the more bubbles you get. To fix this, modern systems use overlapping: while one batch is being processed on GPU 3, the next batch starts on GPU 1. This keeps all devices busy. Pipeline parallelism shines when you’re serving many requests at once. It’s less about speed per request and more about squeezing out maximum throughput. That’s why it’s the go-to for cloud providers running LLM APIs at scale.Combining Both: The Real-World Solution
No one uses just tensor or just pipeline parallelism in production anymore. The best results come from combining them. vLLM’s benchmarks show that using both approaches together on an 8-GPU setup achieves 89% scaling efficiency for a 13B model. Tensor parallelism handles the heavy lifting within each layer, while pipeline parallelism distributes the layers across devices. The result? Near-linear performance gains as you add more hardware. This hybrid approach is now standard in enterprise deployments. Companies like Anthropic and Meta use it to run their largest models. Even smaller teams are adopting it-thanks to tools like vLLM and DeepSpeed, which automate much of the complexity. You don’t need to manually split attention heads or assign layers anymore. The frameworks do it for you. But there’s a hidden advantage: flexibility. You can adjust the balance. For low-latency apps like chatbots, lean toward tensor parallelism. For high-throughput batch processing like document summarization, lean into pipeline parallelism. The right mix depends on your workload, not your hardware.
The Hidden Bottleneck: KV Cache Management
There’s one thing most people overlook: the key-value (KV) cache. When a model generates text, it remembers what it’s seen so far. That memory-called the KV cache-grows with every token generated. For long prompts, the cache can be larger than the model itself. In distributed setups, if every GPU keeps its own copy of the cache, you waste memory. Worse, if a new request comes in that’s similar to a previous one, you can’t reuse the cache unless it’s shared. That means re-running the same prefill computation over and over. Research from the University of Chicago (2024) showed that decoupling the KV cache from the serving engine improves performance by 22%. Systems like vLLM now use centralized cache management. Instead of each GPU holding its own cache, a shared memory pool stores it. This lets multiple requests reuse cached results-cutting prefill time by up to 60% for repetitive prompts. Red Hat’s llm-d (2025) takes this further. It separates the KV cache entirely from the model weights, letting you scale cache storage independently. This is huge for edge deployments where memory is tight.Edge Inference and Heterogeneous Hardware
Most distributed inference happens in the cloud. But that’s changing. Privacy laws, latency needs, and cost pressures are pushing LLMs to the edge-to phones, factory floor servers, even Raspberry Pi clusters. Traditional tensor and pipeline parallelism assume all devices are identical. But edge environments are messy. You might have one powerful GPU, a few weak CPUs, and a couple of low-power accelerators. That’s where Model-Distributed Inference (MDI) comes in. MDI, described in arXiv:2505.18164v1 (2025), assigns layers based on device capability. The first and last layers-often the most computationally expensive-go to the strongest device. Lighter middle layers spread across weaker ones. This cuts latency by 37% on Raspberry Pi clusters compared to rigid parallelism schemes. Red Hat’s llm-d takes this even further. It lets you run prefill stages on CPUs and decode stages on GPUs. Why? Because prefilling (processing the input prompt) is CPU-friendly, while decoding (generating tokens one by one) is GPU-optimized. This split reduces hardware costs by 35% for enterprises that don’t want to over-provision GPUs.Mixture of Experts: The Next Leap
There’s another layer to this: Mixture of Experts (MoE). Instead of using every parameter for every request, MoE models activate only a small subset-like choosing a few specialists from a team of 100. Models like DeepSeek-R1 and GPT-OSS use MoE to achieve 2.8x higher throughput than dense models with the same number of parameters. But they add complexity. Routing tokens to the right experts requires extra logic-and that logic needs to be distributed too. vLLM’s February 2025 update added expert parallelism, letting MoE models run across commodity hardware with 83% scaling efficiency. That’s a game-changer. Now, you can run a 120B-parameter MoE model on 16 consumer-grade GPUs instead of needing expensive H100s. The catch? Routing adds 15-20ms of latency per request. For real-time apps, that’s noticeable. But for batch processing, the trade-off is worth it.
What You Need to Know Before You Start
If you’re thinking about deploying distributed inference, here’s what you’re signing up for:- Hardware matters. NVLink between GPUs reduces communication latency by 5x compared to PCIe. If you’re using tensor parallelism, skip PCIe-only setups.
- Start simple. Harvard’s Kempner Institute recommends beginning with pipeline parallelism before adding tensor parallelism. Misconfigured tensor parallelism can drop throughput by 60%.
- Expect a learning curve. Setting up vLLM or DeepSpeed takes 2-3 days for experienced engineers. Tuning it for your workload? That’s 2-4 weeks.
- Watch for errors. GitHub users report cryptic errors during tensor parallelism setup-often because tensor_parallel_size doesn’t match the number of GPUs. Double-check your configs.
- Plan for cache. If your app handles long conversations or repeated prompts, make sure your framework supports shared KV caching. Otherwise, you’re wasting compute.
Market Trends and What’s Next
The LLM inference market hit $2.8 billion in 2024 and is on track to hit $8.3 billion by 2027. Sixty-three percent of companies using models larger than 13B parameters already rely on distributed inference. Financial services and healthcare lead the way-both need speed, accuracy, and compliance. New tools are emerging fast. NVIDIA’s Unified Parallelism Framework (planned for Q3 2026) will automate tensor and pipeline parallelism configuration. Apache TVM’s Zero-Communication Overhead project aims for 95% scaling efficiency across 128 nodes by 2027. The EU AI Act, effective February 2026, will require companies to document their distributed inference setups. That means you’ll need to track exactly how your model is partitioned-not just for performance, but for compliance.Final Thoughts
Distributed transformer inference isn’t about making models bigger. It’s about making them usable. Tensor parallelism gives you speed. Pipeline parallelism gives you scale. KV cache management gives you efficiency. MoE gives you cost savings. And edge deployment gives you control. The future isn’t one-size-fits-all. It’s hybrid. It’s adaptive. It’s smart about where each piece of the model runs-and why. If you’re deploying LLMs today, you’re already using distributed inference. The question isn’t whether you should. It’s whether you’re doing it right.What’s the difference between tensor parallelism and pipeline parallelism?
Tensor parallelism splits the math inside each transformer layer across multiple devices-like dividing attention heads. Pipeline parallelism splits the layers themselves across devices, like an assembly line. Tensor parallelism is better for low-latency single requests. Pipeline parallelism is better for high-throughput batch processing. Most real-world systems use both together.
Can I run a 70B model on a single GPU?
No, not reliably in production. Even with quantization, a 70B model needs at least 140 GB of memory just for weights. The most powerful single GPU today (H100) has 80 GB. You need at least two high-end GPUs, and usually more, to handle the cache, activations, and concurrent requests.
Which framework is best for distributed inference?
vLLM leads in ease of use and throughput for most use cases, especially with its Chunked Prefill and shared KV cache. DeepSpeed is strong for large-scale training and inference on Microsoft Azure. TensorRT-LLM is best for NVIDIA hardware with maximum optimization. For edge or mixed CPU/GPU setups, llm-d (2025) is the most flexible option.
Does distributed inference slow down response time?
It can, if poorly configured. Communication between devices adds latency. But modern systems like vLLM and Voltage’s framework reduce this overhead by 4x compared to older methods. With proper tuning, distributed inference can be faster than single-GPU inference because it avoids memory bottlenecks and enables higher batch sizes.
Is distributed inference only for big companies?
No. Tools like vLLM and llm-d let small teams deploy 13B-70B models on 4-8 consumer GPUs. Red Hat’s CPU/GPU disaggregation cuts hardware costs by 35%. Even startups are running LLMs on edge devices like Raspberry Pi clusters using adaptive partitioning. You don’t need a data center to get started.
What’s the biggest mistake people make with distributed inference?
Ignoring the KV cache. Many teams focus only on model partitioning and forget that the cache grows with every token. Without shared or decoupled cache management, you waste compute re-running the same prefill steps. That’s the #1 performance killer in real deployments.
Will distributed inference become standard?
Yes. Gartner predicts that by 2028, every production LLM deployment over 7 billion parameters will use distributed inference. The trend is clear: models are getting bigger, hardware is not. Distributed inference isn’t the future-it’s the present.
Sanjay Mittal
December 15, 2025 AT 02:59Just ran a 70B model on 4x A100s using vLLM with tensor + pipeline hybrid last week. KV cache sharing cut our prefill time from 4.2s to 1.6s for repeated prompts. Huge win for customer support chatbots. Also, don’t sleep on chunked prefill-it lets you serve long-context requests without blocking the whole pipeline.
Mike Zhong
December 15, 2025 AT 05:54Stop pretending this is engineering. It’s just glorified jenga with GPUs. You’re not ‘solving’ scaling-you’re papering over the fact that we’ve hit the wall of physics. Moore’s Law is dead, and now we’re duct-taping together 16 H100s like a toddler’s Rube Goldberg machine just to answer ‘What’s the capital of Belarus?’
Jamie Roman
December 17, 2025 AT 00:24I get what you’re saying, Mike-but hear me out. I used to think this was overkill too, until I tried running a 34B model on a single 4090 with quantization. It worked… for one request. Then everything froze. The latency spikes were brutal. Once I switched to pipeline + tensor on 8x 3090s (yes, consumer cards), suddenly my app went from ‘unusable’ to ‘smooth as butter.’ And the KV cache thing? Game changer. I had a user ask the same question 17 times in one session-cache reuse dropped their total wait time from 34 seconds to 3. It’s not magic, it’s just smart memory management. Also, if you’re worried about cost, Red Hat’s llm-d letting you run prefill on CPU? That’s like getting a free upgrade without buying a new car.
Salomi Cummingham
December 17, 2025 AT 13:01Oh my god, Jamie, you just described my entire weekend. I spent three days wrestling with vLLM configs, crying over ‘tensor_parallel_size mismatch’ errors, and then-BAM-suddenly it just WORKED. And the first time I saw a 70B model respond to a 12K token prompt in under 2 seconds? I cried. Not because I’m dramatic (okay, maybe a little), but because this is the first time in my career I felt like I wasn’t just pushing pixels-I was making something that actually *works* for real people. And the fact that a small team in Bangalore can now deploy this on 4 GPUs instead of waiting for AWS credits? That’s hope. That’s progress. That’s what keeps us going.
Johnathan Rhyne
December 18, 2025 AT 00:43Y’all are missing the forest for the GPUs. ‘Tensor parallelism’? That’s not a term-it’s a buzzword salad. And ‘pipeline bubbles’? Please. It’s called idle time. And ‘KV cache’? That’s just RAM you forgot to free. Also, ‘MoE’ isn’t ‘mixture of experts’-it’s ‘mixture of overhyped acronyms.’ And don’t get me started on ‘llm-d.’ That’s not a framework, that’s a typo waiting to happen. Also, ‘Raspberry Pi clusters’? You’re not deploying AI, you’re running a very expensive screensaver. But hey, at least you’re not using TensorFlow. That’s something.
Jawaharlal Thota
December 18, 2025 AT 18:01Bro, I’ve been doing this since the days when we had to manually split attention heads with Python scripts. Back then, if you messed up the tensor split, your model would just silently output ‘The sky is green.’ Now? vLLM does it for you. But here’s the real secret: it’s not about the tech-it’s about the workflow. Start with pipeline, get your batching right, then add tensor parallelism only when you hit latency walls. And please, for the love of all that’s holy, turn on shared KV cache from day one. I’ve seen teams waste $20k/month on redundant prefill because they thought ‘it’s fine for now.’ Spoiler: it’s never fine. Also, if you’re on AWS, use NVLink. PCIe is like trying to fill a bathtub with a garden hose while the drain’s open.