Encoder-Decoder vs Decoder-Only Transformers: Which Architecture Wins for LLMs?
 Apr, 29 2026
Apr, 29 2026
Key Takeaways
- Decoder-Only: The gold standard for creative writing, chatbots, and zero-shot learning (e.g., GPT series).
- Encoder-Decoder: Superior for precise tasks like translation and summarization where input context is everything (e.g., T5, BART).
- Performance: Decoder-only models are generally 15-22% faster during inference.
- Market Trend: About 92% of enterprise LLM implementations currently lean toward decoder-only architectures.
The Structural Divide: How They Actually Work
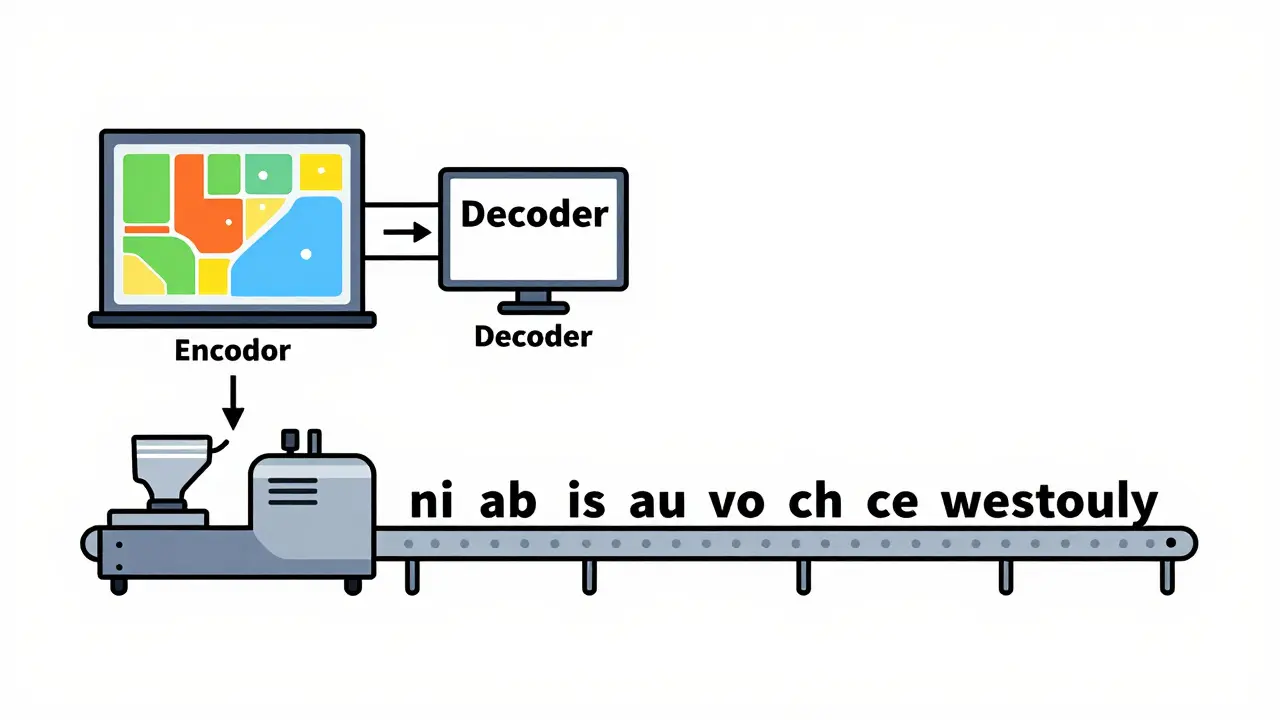
To understand the difference, we have to look at the plumbing. Encoder-Decoder is an architecture that uses a separate encoder to process the input and a decoder to generate the output. Think of it as a two-stage process. The encoder looks at the entire input sequence at once-this is called bidirectional self-attention-meaning every word can "see" every other word. This creates a rich, contextual map. The decoder then takes this map and generates text token by token, using cross-attention to keep checking back with the encoder's map. On the flip side, Decoder-Only models, like the GPT series, skip the separate map-making stage. They use masked self-attention, which means a token can only look at the tokens that came before it. The input prompt and the generated response are treated as one long continuous sequence. It's essentially a very sophisticated autocomplete engine that predicts the next word based on everything that preceded it.Comparing the Heavy Hitters: Performance and Trade-offs
If you're choosing between these for a project, the decision usually comes down to a trade-off between "deep understanding" and "generation speed."| Feature | Encoder-Decoder (e.g., T5) | Decoder-Only (e.g., LLaMA 3) |
|---|---|---|
| Attention Type | Bidirectional + Causal | Causal (Masked) only |
| Inference Speed | Slower (Higher overhead) | Faster (15-22% average gain) |
| Context Window | Smaller (Avg. 4,096 tokens) | Massive (Up to 1M+ tokens) |
| Best Use Case | Summarization, Translation | Creative Text, General Chat |
| Training Stability | More complex/prone to bugs | Simpler, more stable dynamics |
Where Encoder-Decoder Still Rules the Roost
Despite the hype around GPT-style models, there are places where T5 (Text-to-Text Transfer Transformer) and BART still win. When the output needs to be a precise reflection of the input-like turning a data table into a sentence-decoder-only models often stumble. They can "hallucinate" or drift away from the source material because they aren't processing the input holistically. For instance, in machine translation tasks (like the WMT14 English-German benchmark), T5-base often hits higher BLEU scores than comparable decoder-only models. The same goes for summarization. In the CNN/DailyMail dataset, BART-large typically outperforms decoder-only alternatives in ROUGE-L scores because it can effectively "compress" the input before it starts writing.The Rise of the Decoder-Only Empire
Why is everyone using LLaMA 3 or Mistral 7B then? The answer is scalability and flexibility. Decoder-only models are significantly better at few-shot and zero-shot learning. This means you can give them a few examples of a task in the prompt, and they "get it" without needing weeks of expensive fine-tuning. OpenAI's research highlighted this gap: decoder-only models achieved 45.2% accuracy on the SuperGLUE benchmark with zero-shot prompting, while encoder-decoder models lagged at 32.7%. For a business, this is the difference between launching a feature in a day versus spending a month gathering labeled data and training a model.Developer Realities: Deployment and Pain Points
If you've spent time in the Hugging Face forums or r/MachineLearning, you know that theory and production are different. Developers implementing encoder-decoder pipelines often complain about latency. The two-stage process (encoding then decoding) adds a layer of complexity to the inference stack. On the other hand, those using decoder-only models often struggle with "structural drift." Because there's no separate encoder to lock the model onto the input's meaning, these models can sometimes ignore parts of a long prompt or fail to follow strict output formats. However, the sheer amount of community support-roughly 28% more tutorials for decoder-only setups-makes them the path of least resistance for most engineers.What's Next? The Hybrid Future
We are starting to see a convergence. Instead of picking one, researchers are building hybrids. Microsoft's Orca 3 is a great example, combining a small encoder module with a decoder-only backbone to get the best of both worlds: the deep understanding of an encoder and the generative efficiency of a decoder. As we look toward 2027, the divide will likely shift toward specialization. General-purpose AI will remain the domain of the decoder-only giants, but industries like healthcare and law-where a single mistranslated word can be a disaster-will likely drive a resurgence in specialized encoder-decoder deployments.Why are decoder-only models faster during inference?
They eliminate the need for a separate encoding pass and the subsequent cross-attention mechanism that a decoder must use to communicate with the encoder. By treating everything as a single stream of tokens, they reduce computational overhead and memory requirements.
Is T5 a decoder-only model?
No, T5 is a classic encoder-decoder model. It converts every NLP task into a text-to-text format, using an encoder to understand the input and a decoder to generate the response.
Which architecture is better for zero-shot learning?
Decoder-only models are significantly better for zero-shot and few-shot learning. Their training objective (predicting the next token) makes them highly adaptable to new tasks via prompting without needing further weight updates.
Do encoder-decoder models have a smaller context window?
Generally, yes. While not a hard rule, modern decoder-only models like GPT-4 Turbo have pushed context windows to 32k or even 1M tokens, whereas many encoder-decoder models typically hover around the 4,096 token mark.
When should I choose an encoder-decoder model over a decoder-only one?
Choose encoder-decoder if your primary goal is high-precision mapping from input to output, such as translation, abstractive summarization, or structured data-to-text generation where you cannot afford the model to "drift" from the source material.
Next Steps and Troubleshooting
- For the Chatbot Builder: Stick with decoder-only models (LLaMA, Mistral). Focus on prompt engineering and RAG (Retrieval-Augmented Generation) to solve the "context drift" problem.
- For the Translation Specialist: Experiment with T5 or BART. If latency is too high, look into model distillation to shrink the encoder size.
- For the Enterprise Architect: If you need a hybrid approach, look into recent "small encoder" additions to large decoder backbones to improve accuracy on structured tasks.
Kirk Doherty
April 30, 2026 AT 22:29decoder only just feels like it won the lottery for devs
Cynthia Lamont
May 1, 2026 AT 13:29The sheer arrogance of claiming decoder-only models are a "gold standard" is absolutely INSANE!!! You're basically saying we should just accept hallucinations as a feature! It's an absolute disaster for anyone who actually cares about accuracy!! This whole industry is just chasing speed while the quality goes straight into the trash can!!!
Aimee Quenneville
May 2, 2026 AT 17:54omg the dramaa.... just use a hybrid and stop cryin about it!!!! lollll
Meghan O'Connor
May 4, 2026 AT 06:21It is laughable that people still debate this. The encoder-decoder's bidirectional attention is fundamentally superior for mapping tasks, period. The industry's shift toward decoder-only is merely a symptom of lazy engineering and a preference for "vibes" over verifiable precision. Most people using LLaMA don't even understand why it fails at complex summarization; they just keep adding more tokens to the prompt and hope for a miracle. It is a pathetic state of affairs when we prioritize inference speed over structural integrity. The math doesn't lie, but the marketing teams certainly do. We're trading correctness for a slightly faster chatbot that can tell a joke. Absolute rubbish.
Dmitriy Fedoseff
May 5, 2026 AT 16:16The pursuit of "speed" is a degenerate path that strips the soul from linguistic precision. If you cannot respect the bidirectional context of a language, you aren't translating; you are merely guessing. This obsession with decoder-only efficiency is a colonialist approach to data-strip away the nuance, flatten the context, and serve it up fast for profit. It is an insult to the intellectual rigor required for true translation. We must stop treating AI as a product and start treating it as a philosophical tool, or we will lose the very essence of how meaning is constructed across different cultures.
Liam Hesmondhalgh
May 5, 2026 AT 16:43Typical American-centric view of LLMs. You're so obsessed with the "market trend" that you've forgotten how to actually build a stable system. The memory penalty is a small price to pay for not having your model hallucinate a completely different language halfway through a sentence. Get your priorities straight.
Patrick Tiernan
May 5, 2026 AT 23:44imagine actually caring about bleu scores in 2024 lol just let it hallucinate and call it creative writing
Morgan ODonnell
May 7, 2026 AT 12:36everyone has a good point here and it's okay that we have different ways of looking at the tech