Few-Shot Fine-Tuning of Large Language Models: When Data Is Scarce
 Feb, 7 2026
Feb, 7 2026
What if you could adapt a massive language model to your specific task-like summarizing medical notes or detecting fraud-with only 50 examples? Not thousands. Not millions. Just 50. That’s the promise of few-shot fine-tuning, and it’s changing how companies use AI when data is hard to come by.
Why Traditional Fine-Tuning Fails When Data Is Rare
Most people think fine-tuning a large language model (LLM) means feeding it thousands of labeled examples. You take a model like LLaMA or Mistral, give it 5,000 annotated medical records, and let it learn the patterns. Sounds simple, right? Except in real life, getting that many examples is often impossible. In healthcare, privacy laws like HIPAA make sharing patient data risky. In legal tech, contracts are confidential. In finance, fraud patterns change too fast to build large labeled datasets. And even if you could collect the data, training a full fine-tuned model on a 7B-parameter LLM needs 80GB of GPU memory. That’s not just expensive-it’s out of reach for most teams. Enter few-shot fine-tuning. This isn’t just a smaller version of traditional fine-tuning. It’s a completely different approach. Instead of updating every parameter in the model, you tweak only a tiny fraction-sometimes as little as 0.01%-and still get near-perfect results.How Few-Shot Fine-Tuning Works: The PEFT Breakthrough
The magic behind few-shot fine-tuning is called Parameter-Efficient Fine-Tuning, or PEFT. It doesn’t change the original model weights. Instead, it adds small, trainable modules-called adapters-that sit alongside the model’s layers. One of the most popular PEFT methods is Low-Rank Adaptation (LoRA). Here’s how it works: when you fine-tune a model normally, you’re adjusting millions of parameters. LoRA says: “What if we only adjust two tiny matrices?” These matrices are low-rank, meaning they’re small and efficient. They capture the essential changes needed for your task without touching the rest of the model. Think of it like upgrading a car’s engine without replacing the whole vehicle. You add a turbocharger (the adapter), and suddenly it performs better. But you still drive the same car. That’s why LoRA reduces trainable parameters by up to 10,000 times. Then came QLoRA-a game-changer. Developed in 2023 and widely adopted by 2025, QLoRA combines LoRA with 4-bit quantization. That means it doesn’t just use fewer parameters-it stores them in a compressed format. The result? You can fine-tune a 65-billion-parameter model like LLaMA-65B on a single consumer GPU with 24GB of memory (like an NVIDIA RTX 4090). Before QLoRA, you’d need a server with 780GB of VRAM. Now, it fits on a desktop.Performance: How Close Is It to Full Fine-Tuning?
You might wonder: if I’m only tweaking a fraction of the model, how good can it really be? The answer: surprisingly good. On tasks like math reasoning (GSM8K), QLoRA achieves 99.4% of the accuracy of full fine-tuning. On medical entity extraction, teams at Mayo Clinic got 83.7% accuracy using just 75 examples. A fintech startup cut their fine-tuning costs from $18,500 to $460 per task while keeping 94.3% of the original performance. But there’s a catch. Full fine-tuning still wins by 5-8% on average. Why? Because it learns deeper patterns across the entire model. Few-shot methods are like sharp tools-they excel in narrow domains but struggle when the task demands broad knowledge. For example, if you’re trying to adapt a model to a new language, few-shot fine-tuning only hits 63.2% accuracy. Full fine-tuning? 81.4%. That’s because language isn’t just about examples-it’s about deep structural understanding.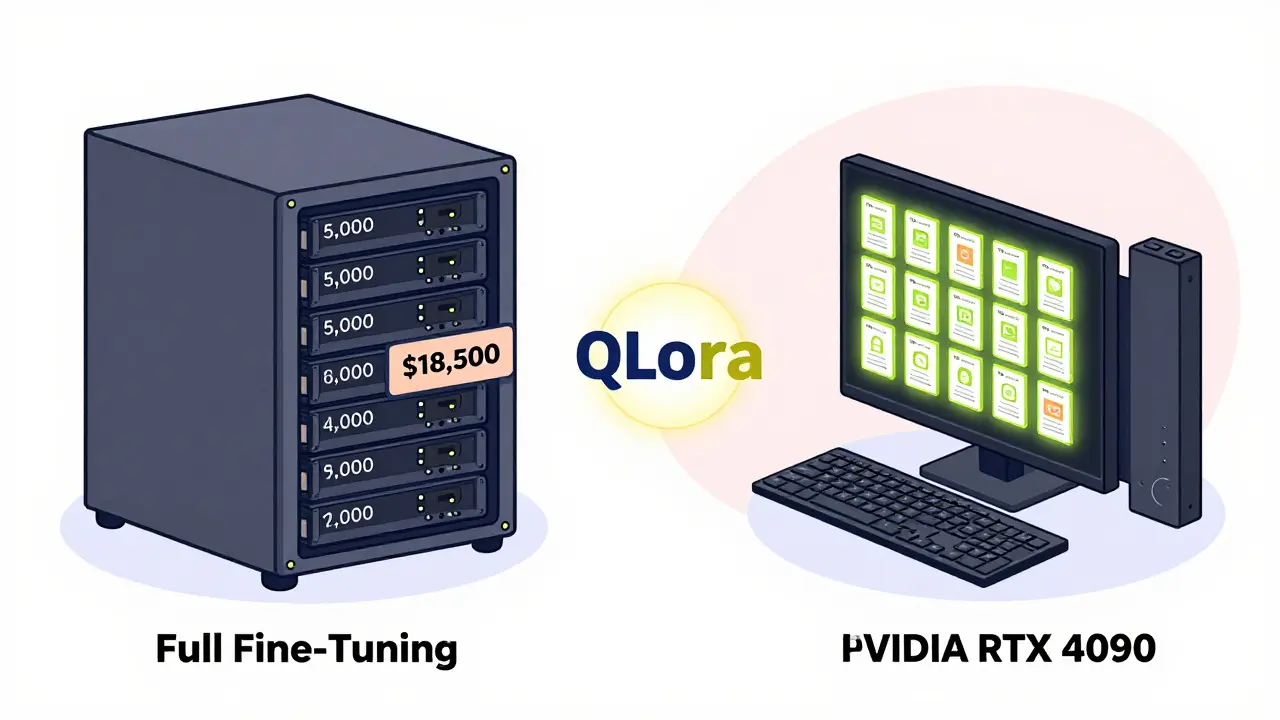
What You Need to Get Started
If you’re ready to try few-shot fine-tuning, here’s what actually matters:- Quality over quantity: 50 well-chosen examples beat 500 messy ones. A 2025 Stanford study found that below 50 examples per class, performance becomes wildly unpredictable. The examples must cover edge cases, not just the obvious ones.
- Use QLoRA: Unless you have access to enterprise GPUs, skip LoRA and go straight to QLoRA. It’s faster, cheaper, and just as accurate.
- Set the right hyperparameters: Learning rate between 1e-5 and 5e-4. Batch size of 4 to 16. Train for 3 to 10 epochs. Go beyond 10 epochs? You’ll overfit. Hugging Face’s diagnostics show 63% of training failures come from wrong learning rates.
- Use Hugging Face’s PEFT library: Released in 2024 and updated in February 2026, it now supports QLoRA out of the box. No more manual code. Just a few lines.
Where Few-Shot Fine-Tuning Shines (and Where It Fails)
This technique isn’t a magic bullet. It’s a scalpel, not a hammer. Best for:- Medical documentation (summarizing clinical notes)
- Legal contract analysis
- Financial fraud detection
- Customer support classification
- Domain-specific chatbots (e.g., insurance policy Q&A)
- Learning entirely new languages
- Tasks requiring broad world knowledge
- Highly dynamic domains (e.g., real-time stock sentiment)
- When you have 10,000+ labeled examples already (just full fine-tune)
Real-World Challenges: What Goes Wrong
People think few-shot fine-tuning is easy. It’s not. On Reddit, a data scientist described spending 37 hours just tuning learning rates on a medical NLP task. Another user on Hugging Face’s forum said their model started hallucinating facts after 5 epochs. That’s not rare. Stanford’s 2025 research found few-shot models produce 18.3% more hallucinations than fully fine-tuned ones-especially on out-of-distribution queries. Common mistakes:- Using too few examples (<20): performance plummets
- Choosing bad examples: if your 50 examples are all similar, the model learns patterns that don’t generalize
- Ignoring data diversity: you need examples that cover edge cases, not just the majority
- Using learning rates above 2e-4: 47% of training attempts fail because of this

The Future: What’s Coming Next
This field is moving fast. In January 2026, Meta AI announced Dynamic Rank Adjustment-a system that automatically tunes the LoRA rank during training. It improved performance by 4.7% across 15 benchmarks. Hugging Face added native QLoRA support in Transformers v4.38 on February 1, 2026. That means you can now fine-tune a 70B model with one Python script. No more custom code. Looking ahead, Stanford’s 2026 roadmap predicts automated example selection: systems that scan unlabeled data and pick the 10 most informative examples for you. Imagine uploading 10,000 unannotated contracts and letting the AI choose the 50 best ones to train on. That’s not science fiction-it’s coming in 18 months.Market Trends: Who’s Adopting This?
The numbers don’t lie:- 78% of enterprise LLM deployments will use PEFT by 2026 (Gartner)
- 54% of the $3.8 billion LLM customization market is PEFT-based (IDC)
- 68% of healthcare AI projects use few-shot methods
- 61% of legal tech teams rely on it
Final Thought: Is Few-Shot Fine-Tuning Right for You?
If you’re working in a field where data is scarce, expensive, or sensitive-healthcare, law, finance, compliance-then yes. Few-shot fine-tuning isn’t just useful. It’s essential. But if you have 10,000 labeled examples? Skip it. Full fine-tuning is still better. The key is knowing your data. Start with 50 high-quality examples. Use QLoRA. Set a learning rate of 3e-5. Train for 5 epochs. Evaluate on unseen data. If performance is above 80%, you’ve unlocked a powerful, low-cost AI tool. This isn’t about doing more with less. It’s about doing the right thing with the data you have.What’s the minimum number of examples needed for few-shot fine-tuning?
Experts recommend at least 50 high-quality, diverse examples per class for classification tasks. Below 20 examples, performance becomes unstable and highly sensitive to example selection. A 2025 Stanford study found that models trained on fewer than 50 examples showed erratic behavior, especially on edge cases. For tasks like summarization or generation, 30-50 examples can work if they cover a wide range of input patterns.
Can I use few-shot fine-tuning on consumer hardware?
Yes, with QLoRA. Before 2023, fine-tuning a 7B model required 80GB of VRAM. Now, QLoRA with 4-bit quantization lets you run fine-tuning on a single NVIDIA RTX 4090 (24GB VRAM). Even models as large as 65B parameters can be fine-tuned on a $1,500 GPU. This has made LLM adaptation accessible to startups, researchers, and small teams without cloud budgets.
How does few-shot fine-tuning compare to prompt engineering?
Prompt engineering (zero-shot or few-shot prompting) requires no training-it just gives the model examples in the input. But it underperforms fine-tuned models by 12-18% on domain-specific tasks. A 2024 Mayo Clinic study found that prompting failed to accurately code medical diagnoses 31% of the time, while a few-shot fine-tuned model got it right 91% of the time. Fine-tuning learns patterns. Prompting just asks the model to guess. For critical applications, fine-tuning wins.
Does few-shot fine-tuning reduce hallucinations?
Not automatically. In fact, few-shot fine-tuned models produce 18.3% more hallucinations than fully fine-tuned ones, according to Stanford’s 2025 research. This happens because the model overfits to small datasets and starts inventing patterns. The fix? Careful hyperparameter tuning, early stopping, and using diverse examples. With optimized settings, the gap drops to just 6.2%.
Is QLoRA better than LoRA?
For most users, yes. LoRA reduces memory use by compressing updates. QLoRA goes further by compressing the model weights themselves using 4-bit quantization. This cuts memory requirements from 780GB to 48GB for a 65B model. QLoRA also matches or exceeds LoRA’s accuracy while being faster and cheaper. Unless you’re working with legacy systems that don’t support quantization, QLoRA is the default choice in 2026.
What tools should I use to start?
Start with Hugging Face’s PEFT library and Transformers v4.38 (released February 2026). It has built-in QLoRA support. Combine it with a model like Mistral-7B or Llama-3-8B. Use PyTorch. The entire process can be done in under 10 lines of code. Documentation has improved dramatically since 2024, with 1.85 million monthly views on Hugging Face’s guides. Avoid manual implementations unless you’re an expert.
Jeroen Post
February 8, 2026 AT 22:47Honey Jonson
February 10, 2026 AT 20:34Sally McElroy
February 11, 2026 AT 12:38Destiny Brumbaugh
February 12, 2026 AT 15:47Sara Escanciano
February 12, 2026 AT 17:07Elmer Burgos
February 13, 2026 AT 15:29