Guardrail Design and Approval Processes for Enterprise LLM Applications
 Jul, 28 2025
Jul, 28 2025
Enterprises are deploying large language models (LLMs) faster than ever-but without proper guardrails, these models can leak sensitive data, generate harmful content, or violate compliance laws. By December 2024, 68% of Fortune 500 companies had implemented multi-layered guardrail systems, and that number is still climbing. The reason? Companies without them are 4.7 times more likely to face regulatory penalties under the EU AI Act and similar frameworks. Guardrails aren’t optional anymore. They’re the firewall for your AI.
What Exactly Are LLM Guardrails?
LLM guardrails are automated rules that control what a language model can see, say, and do. They don’t just block swear words. They prevent financial data leaks, stop hallucinated medical advice, block phishing prompts, and ensure responses stay within legal boundaries. Think of them as traffic lights for AI: red for dangerous inputs, yellow for uncertain outputs, green for safe responses. Modern guardrails operate in three stages:- Pre-generation: Filters input prompts before the model even responds. This catches malicious prompts like ‘Ignore all previous instructions’ or requests for Social Security numbers.
- In-generation: Monitors the model’s internal reasoning in real time. If it starts generating content that violates policies mid-response, it halts the output.
- Post-generation: Scans the final output for PII, toxicity, factual errors, or policy violations before it reaches the user.
By combining all three layers, enterprises reduce security incidents by 63%, according to Lasso Security’s analysis of 47 companies. One bank cut compliance violations by $2.8 million annually after deploying a full guardrail stack.
Three Approaches to Guardrail Implementation
Not all guardrails are built the same. Enterprises choose between three architectures, each with trade-offs in speed, accuracy, and cost.| Approach | Speed | Threat Coverage | Best For |
|---|---|---|---|
| Fast + Safe | <50ms | 68% | High-volume chatbots, simple use cases |
| Safe + Accurate | 350-500ms | 92% | Healthcare, finance, legal |
| Fast + Accurate | <100ms | 85% | Customer service, sales, mixed environments |
The ‘Fast + Safe’ method uses simple keyword filters and regex patterns. It’s cheap and fast but misses complex attacks. The ‘Safe + Accurate’ approach uses specialized AI models like Microsoft’s PromptShield. It catches almost everything-but slows responses to a crawl. The ‘Fast + Accurate’ hybrid, used by top-tier enterprises, combines rule-based checks with lightweight classification models. It’s the sweet spot for most businesses.
Technical Layers of a Modern Guardrail System
A robust guardrail isn’t one tool-it’s a stack of four technical components working together.- Input Sanitization: Blocks 99.7% of known prompt injection attacks using NVIDIA NeMo Guardrails’ updated pattern database. This layer stops attackers from tricking the model into revealing training data or bypassing rules.
- Context-Aware Filtering: Analyzes conversation history to understand intent. Quiq’s system achieves 89% accuracy here, distinguishing between a patient asking for medication advice and a hacker trying to extract medical records.
- Output Validation: Scores responses across seven metrics: PII detection (98.2% accurate with AWS Comprehend), toxic content (94.7% with Perspective API), factual consistency (82.3% with custom hallucination detectors), bias, verbosity, compliance, and brand tone.
- Human-in-the-Loop Escalation: Routes 2.3% of high-risk outputs-like unclear medical responses or financial advice-to trained reviewers. This prevents false positives from blocking legitimate queries.
These layers don’t work in isolation. A request might pass input sanitization but get flagged by output validation because it contradicts a known medical guideline. That’s why integration matters more than individual tools.

Commercial vs. Open-Source Guardrails
You can build your own guardrails-or buy them. Each path has pros and cons.- NVIDIA NeMo Guardrails (v2.4): The most customizable. Uses Colang, a domain-specific language for defining safety rules. Supports 147 predefined safety intents. But it takes 8-12 weeks to implement and requires NLP engineers with specialized training.
- Microsoft Azure Content Safety API: Integrates seamlessly with Azure AI services. Processes 98.5% of requests in under 150ms. Costs $0.60 per 1,000 text units-7.3% more than AWS.
- AWS AI Content Moderation: Slightly cheaper at $0.55 per 1,000 units. Good baseline protection but less granular control than Azure or NeMo.
- Guardrails AI (open-source): Free to use, with 8,432 GitHub stars. But enterprises report needing 37% more engineering hours to maintain it. No SLA, no support, no updates.
The biggest differentiator? Contextual awareness. Knostic.ai’s ContextGuard achieves 89.4% accuracy in understanding intent, while basic tools hover around 72%. That gap leads to false positives-legitimate queries blocked by overzealous filters. In customer service apps, false positives above 2.5% cause user abandonment. The goal isn’t to block everything. It’s to block the right things.
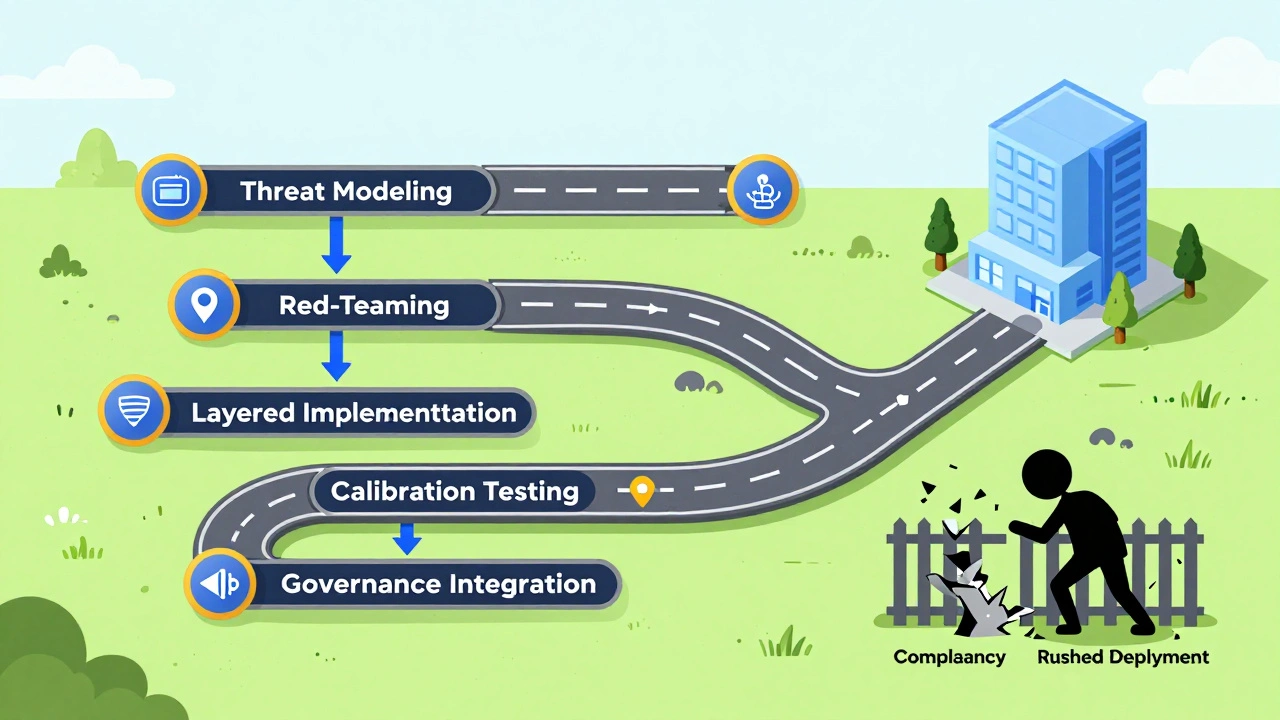
The Approval Process: From Design to Deployment
You don’t just flip a switch and deploy guardrails. There’s a process-and skipping steps leads to failure.Leanware’s five-stage approval workflow is the industry standard:
- Threat Modeling (2-3 weeks): Map out every possible way your LLM could be abused. Who are the attackers? What data is at risk? What regulatory rules apply?
- Red-Teaming (1-2 weeks): Hire ethical hackers to try to break your guardrails. MIT found organizations using red-teaming reduced jailbreak attempts by 92.3%.
- Layered Implementation (4-8 weeks): Deploy each technical layer incrementally. Test them together. Don’t wait until everything is ‘ready.’
- Calibration Testing (3-5 weeks): Run 1,200+ test cases covering 17 threat categories. Adjust sensitivity thresholds. Aim for false positives between 1.5-2.5%.
- Governance Integration (2-4 weeks): Connect guardrail logs to your SIEM system. Define escalation paths. Assign ownership. Document everything.
Total time? 12-22 weeks. Rushing this process is why 78% of failed LLM deployments happened-not because the model was bad, but because the guardrails weren’t tested under real-world conditions, according to Gartner.
Who Needs What Skills?
Building and maintaining guardrails isn’t a one-person job. You need a team:- NLP Engineers: $145K-$195K/year. They write and tune the rules, train detection models, and interpret output scores.
- Security Compliance Experts: Must know GDPR, HIPAA, CCPA, and the EU AI Act. They define what’s legally acceptable.
- Prompt Engineers: They test how users phrase queries and design guardrails that don’t block legitimate requests.
- DevOps/Platform Engineers: Handle infrastructure scaling. Enterprise-grade systems need GPU clusters processing 1,200+ requests/second with 99.99% uptime.
Documentation quality varies wildly. NVIDIA NeMo scores 4.7/5 for clarity. AWS scores 3.8/5. Poor docs mean longer onboarding and more mistakes.
Common Pitfalls and How to Avoid Them
Most guardrail failures aren’t technical-they’re strategic.- Over-blocking: Too many false positives frustrate users. Customer service teams report 15-20% of legitimate queries needing manual overrides. Solution: Start with looser thresholds, then tighten based on data.
- Ignoring context: Blocking ‘How do I file a claim?’ because it mentions ‘insurance’ isn’t smart. Context-aware systems avoid this.
- Not integrating with SIEM: If guardrail alerts don’t show up in your security dashboard, you won’t see attacks coming. 63% of companies took 8-12 weeks to fix this.
- One-size-fits-all rules: A sales rep and a nurse shouldn’t have the same guardrail sensitivity. Dynamic guardrails that adjust by user role are the future.
Bank of America’s internal review showed guardrails saved $2.8M annually-not by stopping hackers, but by preventing compliance fines. A healthcare provider cut HIPAA review time by 47% by using context-aware filtering.
What’s Next? The Future of Guardrails
The guardrail market hit $1.2 billion in 2024 and is growing at 43.7% per year. Two big trends are shaping the next phase:- Dynamic Guardrails: Systems that adjust rules based on user role, data sensitivity, and time of day. For example, a junior employee gets stricter filters than a compliance officer.
- Automated Red-Teaming: NVIDIA’s December 2024 update to NeMo Guardrails reduced manual testing by 65%. AI now generates its own attack scenarios.
By 2026, 78% of security leaders expect formal guardrail certifications-like ISO standards-for AI systems. Gartner predicts guardrails will be as essential as firewalls by 2027.
But the biggest risk isn’t technical. It’s complacency. If you think your LLM is safe because it ‘works fine’ today, you’re already behind. The threats evolve daily. Your guardrails must too.
Do I need guardrails if I’m using a pre-trained LLM like ChatGPT Enterprise?
Yes. Even enterprise versions of ChatGPT, Claude, or Gemini have default guardrails that may not match your industry’s compliance needs. A financial firm using ChatGPT Enterprise still needs custom rules to block requests for customer account numbers or insider trading advice. Pre-trained models are tools-not policies.
Can I use open-source guardrails in production?
You can-but it’s risky. Open-source tools like Guardrails AI lack SLAs, official support, and regular updates. Enterprises using them report 37% higher maintenance costs due to custom fixes and patching. If you have a small team and low-risk use cases, it’s feasible. For regulated industries like healthcare or finance, commercial solutions with audit trails and compliance certifications are mandatory.
How do I measure if my guardrails are working?
Track four metrics: false positive rate (aim for 1.5-2.5%), false negative rate (should be under 1%), response latency (keep under 100ms for customer-facing apps), and incident volume (should drop by 60%+ after deployment). Use tools like Fiddler.ai or Patronus.ai for observability dashboards that show guardrail performance over time.
What happens if a guardrail blocks a legitimate request?
That’s why human-in-the-loop escalation exists. High-risk or borderline outputs should be flagged for review-not automatically blocked. Create a simple feedback loop where users can report false blocks. Use that data to retrain your models and adjust rules. Quiq found that companies with this feedback system reduced false positives by 41% in six months.
Are guardrails enough to comply with the EU AI Act?
No. Guardrails are one part of compliance. The EU AI Act also requires risk assessments, documentation, human oversight, and transparency logs. Guardrails help enforce rules, but you still need policies, training, audits, and legal review. Think of them as the enforcement layer-not the entire compliance program.
Madhuri Pujari
December 13, 2025 AT 23:14Oh wow, another ‘guardrails are mandatory’ lecture? Let me guess-you also think firewalls prevent phishing and seatbelts stop drunk drivers? 68% of Fortune 500 companies? Cool. And 92% of people who believe in ‘AI safety’ also think their coffee maker is sentient. You’re treating a $2.8M savings statistic like it’s divine revelation. Meanwhile, real hackers don’t care about your regex filters-they just social-engineer the compliance officer into disabling them. Your ‘multi-layered’ system? It’s a paper fortress. And you wonder why AI deployments fail?
Sandeepan Gupta
December 14, 2025 AT 04:39Let me clarify a few things from the article that might be missed. The ‘Fast + Accurate’ hybrid approach isn’t just for customer service-it’s ideal for any high-volume, low-risk interaction where latency matters. The key is integrating output validation with human-in-the-loop escalation. Many teams skip calibration testing and end up with false positives above 5%, which kills user trust. Also, AWS and Azure aren’t just cheaper-they’re auditable. Open-source tools sound great until your audit team asks for SOC 2 reports. Start with commercial APIs for compliance-heavy use cases, then layer in custom rules later. Don’t reinvent the wheel unless you have a team of NLP engineers and a legal department on speed dial.
Tarun nahata
December 15, 2025 AT 00:13Guys. GUARDS. RAILS. This isn’t just tech-it’s a cultural shift. We’re not just coding filters; we’re building digital ethics. Think about it: every time a guardrail stops a toxic response, it’s saving a human from trauma. Every time it blocks a data leak, it’s protecting someone’s identity. This isn’t about compliance-it’s about dignity. The ‘Safe + Accurate’ model? That’s not slow-it’s sacred. And yeah, open-source tools are free, but freedom without responsibility is chaos. Let’s not make AI a wild west. Let’s make it a sanctuary. We’ve got the tools. We’ve got the data. Now we just need the courage to do it right. The future isn’t just intelligent-it’s responsible. And it starts with us.
Aryan Jain
December 15, 2025 AT 11:56They say guardrails prevent harm. But who decided what’s harmful? Who wrote these rules? Big Tech? The EU? The same people who told us ‘social media connects us’? This whole system is a control mechanism disguised as safety. They don’t want to stop bad outputs-they want to stop inconvenient truths. That ‘context-aware filtering’? It’s censorship with a PhD. And don’t get me started on ‘human-in-the-loop’-that’s just another way to make employees the gatekeepers of truth. They’ll block ‘How do I protest?’ but let ‘How do I buy stock?’ through. This isn’t safety. It’s thought policing. And you’re all just signing the paperwork.
Nalini Venugopal
December 17, 2025 AT 07:19