How Sampling Choices in LLMs Trigger Hallucinations and What to Do About It
 Jan, 17 2026
Jan, 17 2026
Large language models (LLMs) don’t lie on purpose. But they often sound like they do. You ask for a fact, and the model gives you a convincing made-up answer - a fake citation, a nonexistent law, a person who never existed. This isn’t a bug. It’s a feature of how these models generate text. And the biggest culprit? The sampling choices you make during generation.
What Exactly Is a Hallucination?
A hallucination in an LLM isn’t a glitch. It’s the model confidently generating something that isn’t true, isn’t in the context, and can’t be verified. Think of it like a student who guesses on a test they didn’t study for - but then writes a 500-word essay as if they knew the answer all along. The model isn’t lying. It’s just predicting the most likely next word based on patterns it learned, not facts it remembers. There are two main types: intrinsic hallucinations, where the model invents facts from its training data, and extrinsic hallucinations, where it ignores the provided context entirely. Both are worsened by how you tell the model to generate text - specifically, the sampling settings.How Sampling Controls the Model’s Creativity
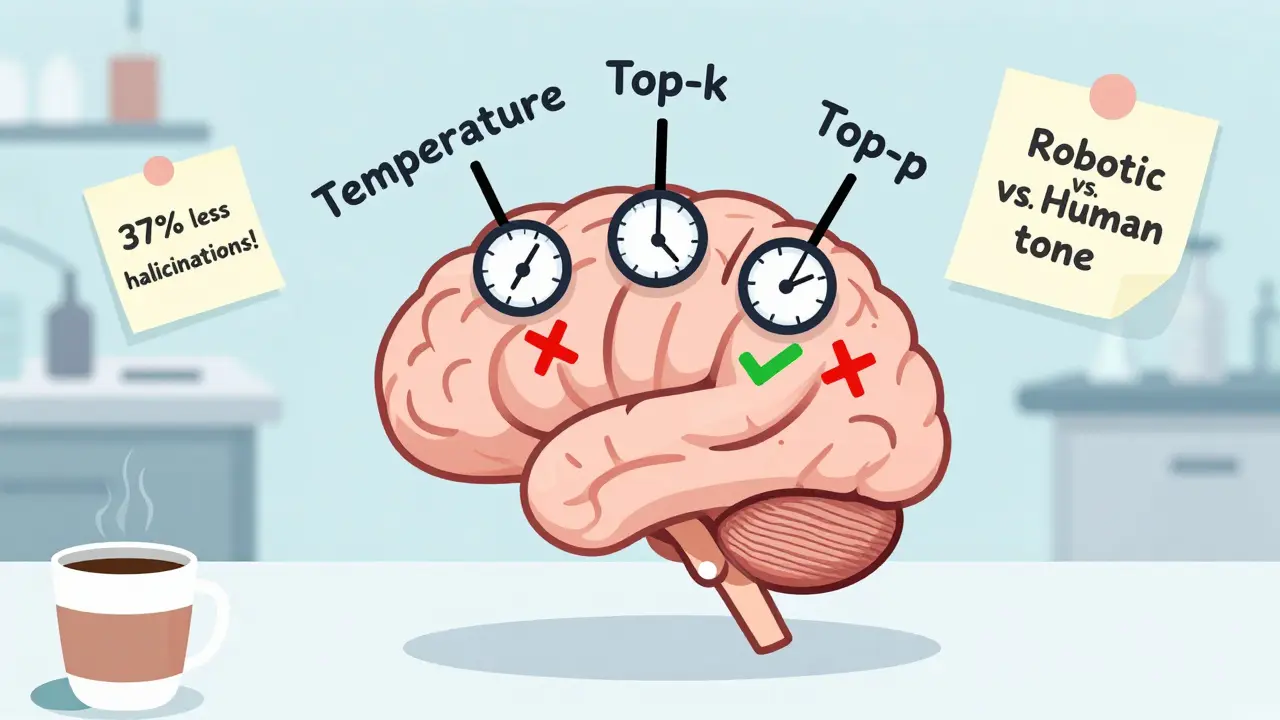
When an LLM generates text, it doesn’t pick the single most likely next word every time. That’s greedy decoding. Instead, it samples from a probability distribution - a list of possible next words ranked by how likely they are. The way you sample from that list determines whether the output is safe, boring, or wildly wrong. Think of it like cooking. If you follow a recipe exactly, you get consistent results. If you toss in random spices without measuring, you might get something amazing… or something that makes everyone sick. Sampling parameters are your spice drawer.Temperature: The Creativity Dial
Temperature is the most basic control. It stretches or squeezes the probability distribution. At 0, the model always picks the most likely word - predictable, safe, repetitive. At 1.0 or higher, it’s wild. It picks low-probability words just because it feels like it. Data from Datadog’s October 2024 testing on the HaluBench dataset shows lowering temperature from 0.7 to 0.3 cut hallucinations by 37%. That’s huge. But here’s the catch: at 0.2, responses become robotic. A customer service bot might give perfect answers - but sound like a vending machine. Experts like Professor Andrew Ng recommend 0.2-0.5 for factual tasks. For creative writing, 0.7-0.9 is fine. But for medical, legal, or financial use cases? Stick to 0.3 or lower. Too high, and you risk giving someone dangerous misinformation.Top-k Sampling: Cutting Out the Noise
Top-k sampling limits the model to choosing only from the k most likely next words. If k=10, it ignores the other 99.9% of possibilities. That sounds strict - and it is. But it works. Raga AI’s tests showed that reducing k from 100 to 40 cut factual errors by 28%. Why? Because low-probability words are often nonsense. The model might pick “quasar” when “star” was the only logical choice. By pruning those outliers, you remove a major source of hallucinations. But there’s a trap. If k is too low - say, k=10 - the model gets stuck in loops or fails on technical tasks. In Raga’s tests, k=20 led to 41% error rates in engineering contexts. The sweet spot? Around k=40-50 for most factual applications. For creative tasks, k=80-100 keeps things interesting without going off the rails.
Nucleus Sampling (Top-p): The Smart Compromise
Nucleus sampling, or top-p, is smarter than top-k. Instead of picking a fixed number of words, it picks the smallest group of words whose combined probability adds up to p. So if the top 5 words add up to 92%, it only considers those - even if the 10th word has a 3% chance. This adapts to context. In a technical question, the top words might be very concentrated. In a story, they’re spread out. That’s why nucleus sampling often outperforms top-k. Datadog’s February 2025 testing found that p=0.92 gave 94.3% factual accuracy - better than top-k at k=50. Appsmith’s customer support team saw a 22% drop in hallucinations switching from p=0.95 to p=0.90. It’s the current gold standard for balancing accuracy and fluency.Beam Search: Safe But Boring
Beam search doesn’t sample at all. It explores multiple paths simultaneously and keeps the top N (the “beams”) at each step. It’s deterministic. It’s reliable. And it’s dull. In RAGTruth benchmarks, greedy decoding (a form of beam search with beam width=1) achieved 98.7% factual accuracy. But Evidently AI found that 73% of real-world users found these outputs unusable - too repetitive, too robotic. It’s like having a robot lawyer who never makes a mistake… but also never says anything interesting. Use beam search only if accuracy is non-negotiable and creativity is irrelevant - think legal document summarization or medical report generation. For chatbots, customer emails, or content creation? Skip it.Real-World Results: What Works in Practice
Companies aren’t just theorizing. They’re testing this stuff daily. At Datadog, switching to nucleus sampling with p=0.92 across all customer-facing tools reduced reported hallucinations by 37% in Q1 2025. But it took weeks of tuning per app. Reddit users saw similar wins: one engineer cut hallucinations in a financial advice bot by 42% by dropping temperature to 0.3. But another user got complaints because responses became too stiff - satisfaction scores dropped from 4.2 to 3.1. Domain matters. Medical apps need temperature=0.15-0.25. Customer service can use 0.3-0.4. Creative writing? 0.7-0.9 is fine - even if hallucinations jump 2-3x. GitHub’s “llm-hallucination-tracker” project confirmed this pattern across 12,000 real prompts.Advanced Tactics: Combining Methods
The best results come from stacking techniques. The Datadog team uses a two-stage approach: first, generate with low temperature (0.3) and p=0.9 to ensure facts are correct. Then, rephrase the output with slightly higher temperature (0.45) to make it sound more human. This cut implementation time by 40%. Dr. Percy Liang’s Stanford team found that combining low temperature (0.3) with structured output constraints - like forcing the model to answer in bullet points or JSON - reduced hallucinations by 58% compared to free-form generation. Even more powerful: consortium voting. Cambridge Consultants ran the same prompt through five models with identical settings, then picked the most common answer. This slashed hallucinations by 18-22 percentage points. But it tripled compute costs. Only worth it for high-stakes use cases - think surgery recommendations or court filings.
What’s Next: Automated Sampling
The future isn’t manual tuning. It’s adaptive sampling. Google’s Gemma 3, released in January 2025, detects whether you’re asking for a fact or a story - then auto-adjusts temperature and top-p. Internal tests showed a 44% drop in hallucinations. OpenAI’s January 2025 API update includes “hallucination guardrails” - if you’re using RAG (retrieval-augmented generation), the system automatically lowers temperature and narrows sampling to protect accuracy. Meta’s Llama 4, expected in Q2 2025, will monitor token-level confidence mid-generation. If the model starts picking low-confidence words, it’ll clamp down on randomness automatically. Gartner predicts that by 2027, 90% of enterprise LLMs will use automated sampling - not because engineers are lazy, but because manual tuning is too slow and inconsistent.Where to Start
You don’t need a PhD to fix hallucinations. Here’s your starter kit:- For factual tasks (medical, legal, finance): Start with temperature=0.3, top-p=0.9, top-k=50.
- For customer service or general chat: Try temperature=0.4, top-p=0.92, top-k=70.
- For creative writing: Use temperature=0.7-0.8, top-p=0.95, top-k=100.
The Catch: Too Safe Can Be Bad Too
Dr. Emily Bender from the University of Washington warns: over-optimizing for accuracy can create new problems. A model that never hallucinates might also never help. It might refuse to summarize, avoid answering complex questions, or give overly cautious replies that frustrate users. A medical chatbot that says “I don’t know” every time is safer - but useless. You need the model to be confident when it’s right, and cautious when it’s unsure. That’s the balance.Final Thought
Sampling parameters aren’t magic. They won’t fix a broken model. But they’re the fastest, cheapest, and most effective tool you have right now to reduce hallucinations - without retraining, without RAG, without fine-tuning. You’re not fixing the model. You’re guiding its behavior. The next time your LLM makes up a fact, don’t blame the AI. Look at your temperature setting. Chances are, it’s too high.What is the most effective sampling method to reduce hallucinations?
Nucleus sampling (top-p) with p=0.90-0.92 currently offers the best balance of accuracy and fluency. It outperforms top-k and beam search in real-world tests, reducing hallucinations by up to 22% compared to looser settings, while keeping outputs natural. Datadog’s 2025 testing showed 94.3% factual accuracy with p=0.92, making it the industry standard for most applications.
Does lowering temperature always reduce hallucinations?
Yes, lowering temperature reduces hallucinations by making the model pick higher-probability words. But going too low - below 0.2 - makes responses robotic and unhelpful. For factual tasks, 0.3 is ideal. For creative tasks, keep it above 0.6. The goal isn’t zero hallucinations - it’s enough accuracy without losing usability.
Can I use top-k and nucleus sampling together?
Technically yes, but it’s rarely useful. Nucleus sampling already filters out low-probability tokens dynamically. Adding top-k on top can over-constrain the model, especially if k is set too low. Most practitioners use one or the other. If you’re unsure, start with nucleus sampling alone - it’s more adaptive and performs better across domains.
Why do some companies still use high temperature settings?
Because creativity matters. In marketing, storytelling, or brainstorming, users want unexpected, imaginative responses - even if they’re occasionally wrong. Media and entertainment companies accept higher hallucination rates (up to 3x more) because their goal isn’t factual precision - it’s engagement. The tradeoff is intentional.
Are there tools that automate sampling parameter tuning?
Yes. AWS SageMaker now auto-optimizes sampling parameters for RAG applications. Weights & Biases tracks sampling behavior across experiments. OpenAI’s API has built-in guardrails that lower randomness when detecting factual queries. These tools reduce manual tuning by 60-70%. The “LLM Sampling Playbook” on GitHub also offers automated scripts for common use cases.
Will sampling parameters fix hallucinations forever?
No. Sampling controls symptoms, not causes. Hallucinations come from how models are trained - they’re rewarded for sounding confident, not for admitting uncertainty. MIT’s 2025 white paper says architectural changes are needed to eliminate hallucinations entirely. But for the next 3-5 years, smart sampling will remain the most practical solution for reducing them in production.
Priti Yadav
January 18, 2026 AT 15:00Okay but what if the whole thing is a psyop? I’ve seen models spit out fake UN resolutions that never existed - and then the same exact text shows up in a ‘research paper’ from a think tank linked to a defense contractor. Who’s really training these models? And why do they all sound like they’re reading from a CIA briefing? 🤔
Ajit Kumar
January 20, 2026 AT 07:48It is not merely a matter of temperature or top-p - it is a fundamental epistemological failure of statistical language models to distinguish between syntactic plausibility and semantic truth. When a model generates a citation to a non-existent journal article with perfect APA formatting, it is not ‘hallucinating’ - it is performing exactly as designed: to maximize likelihood, not accuracy. The entire paradigm must be rethought, not merely tuned.
Diwakar Pandey
January 21, 2026 AT 21:43Been using p=0.9 and temp=0.3 for my legal doc summaries. Works great. No more fake case law. But yeah, sometimes it sounds like a robot reciting the dictionary. I just add a line at the end like ‘This is not legal advice’ - keeps people from panicking. Also, don’t forget to test with real user prompts. The lab numbers don’t always match real life.
Geet Ramchandani
January 22, 2026 AT 01:19Wow. Another ‘guide’ from someone who thinks lowering temperature is a ‘fix.’ You people are so naive. The model doesn’t care if you set p=0.92 or k=40 - it’s still a glorified autocomplete trained on internet garbage. You’re not ‘reducing hallucinations,’ you’re just making the lies sound more polite. And now you’re patting yourselves on the back like you solved AI? Please. Go read the original papers. The problem is training data, not sampling. Stop pretending tweaking knobs fixes broken systems.
Pooja Kalra
January 22, 2026 AT 12:59There is a silence between the words the model speaks and the truth it was never taught to hold. We ask it to be wise, yet feed it only echoes. The sampling parameters are merely the volume dial on a recording of a dream. We mistake the echo for the voice - and then blame the machine for not knowing what it was never allowed to learn.
Sumit SM
January 22, 2026 AT 21:39Wait - so you’re saying that if I set top-p to 0.92, and temp to 0.3, and use beam search with a width of 5 - and then rephrase with temp 0.45 - I can reduce hallucinations by 40%? That’s… actually kind of beautiful. Like tuning a violin while blindfolded. But why does it feel like we’re all just trying to make a broken clock tell the right time twice a day?
Jen Deschambeault
January 24, 2026 AT 03:32Just tried the two-stage method on my customer chatbot. Huge difference. First pass: cold and accurate. Second pass: human-sounding. Clients actually smiled at replies now. No more robotic ‘I cannot provide legal advice’ spam. Small tweak, big impact. Seriously, try it.
Kayla Ellsworth
January 25, 2026 AT 05:50So the solution to AI making things up is… to make it less creative? Brilliant. Next you’ll tell us to stop using fire because it burns things. Maybe the problem isn’t the sampling - maybe it’s that we keep asking machines to be humans.
Soham Dhruv
January 26, 2026 AT 03:33just dropped temp to 0.3 and top-p to 0.9 on my coding assistant and wow it stopped making up fake stackoverflow answers. still a bit stiff but way better than before. also i think we should all just use the github playbook. no need to reinvent the wheel lol