In-Context Learning in Large Language Models: How LLMs Learn from Prompts without Training
 Feb, 3 2026
Feb, 3 2026
Imagine giving a language model a few examples of how to answer a question - and suddenly, it gets it right, every time. No retraining. No tweaking weights. No waiting days for a model to learn. Just a prompt with a couple of examples, and boom - it performs like it’s been trained on the task. This isn’t magic. It’s in-context learning, and it’s changing how we use AI today.
What Exactly Is In-Context Learning?
In-context learning (ICL) is when a large language model (LLM) figures out how to do a new task just by seeing a few examples inside the prompt you give it. You don’t change the model. You don’t retrain it. You just show it what you want, and it adapts on the fly.
This ability was first clearly demonstrated in 2020 with GPT-3. Researchers at OpenAI showed that if you gave GPT-3 a few input-output pairs - like "Translate this: Hello → Bonjour" - it could then translate new sentences it had never seen before. No fine-tuning. No gradients. Just the examples in the prompt.
That’s the core of ICL: learning from context. The model uses the examples you provide as temporary instructions. It’s like handing someone a cheat sheet right before a test. They don’t memorize the whole textbook - they just use the notes you gave them.
How Does It Work Inside the Model?
LLMs are trained on massive amounts of text. They learn patterns, grammar, facts, and even how to reason. But they’re not built to be programmed like a calculator. Instead, they’re built to predict the next word - billions of times.
When you give it examples in a prompt, something surprising happens. The model doesn’t just copy the examples. It tries to find the pattern behind them. Research from MIT in 2023 showed that LLMs can even learn tasks using completely synthetic data - data they’ve never seen during training. That means they’re not just memorizing. They’re generalizing.
One theory is that the model contains a "model within a model." Think of it like a tiny machine-learning algorithm hidden inside the neural network. When you show it examples, this internal model wakes up and starts working. It figures out the task, then applies it to the new input.
Studies using models like GPTNeo2.7B and Llama3.1-8B found that around layer 14 of 32, the model "gets" the task. After that point, it stops paying attention to the examples and starts generating answers based on what it learned. This discovery lets engineers cut computation by up to 45% - because they can skip processing later layers for the examples.
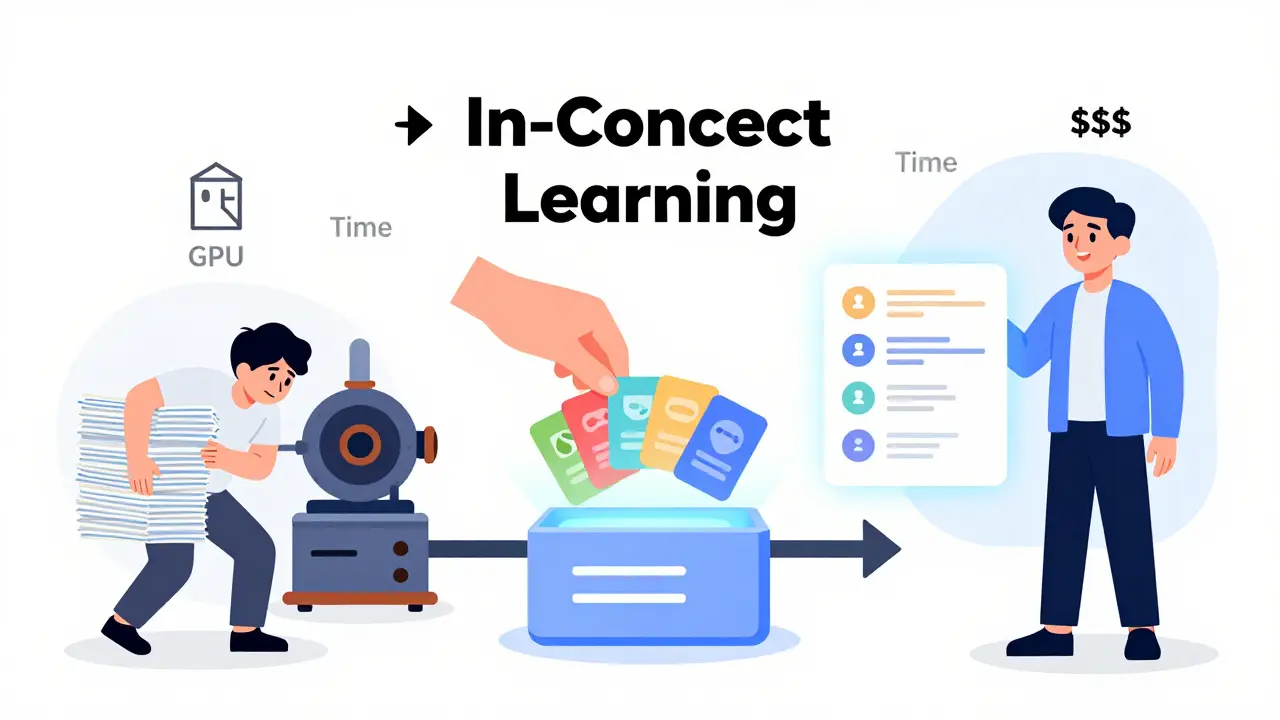
Why Is It Better Than Fine-Tuning?
Before ICL, if you wanted a model to do something new - like classify medical reports or summarize legal contracts - you had to fine-tune it. That meant collecting data, labeling it, training the model, and waiting days or weeks. It was expensive and slow.
ICL changes all that. With ICL:
- You don’t need labeled data
- You don’t need GPU time
- You don’t need to retrain
- You can test ideas in minutes
According to McKinsey’s 2023 AI survey, 68% of enterprises prefer ICL over fine-tuning. Why? Because it’s faster. The average time to deploy an ICL-based solution is 2.3 days. Fine-tuning? 28.7 days.
And it’s cheaper. You’re not paying for training. You’re just paying for inference - which costs pennies per request.
How Many Examples Do You Need?
More examples don’t always mean better results. In fact, too many can hurt performance.
Research from arXiv in early 2023 found that for most tasks, 2 to 8 examples work best. Beyond 16, accuracy often drops. Why? Because the model’s context window gets filled up. Attention mechanisms get overloaded. It starts confusing itself.
Here’s what works in practice:
- One-shot (1 example): 40-50% accuracy on average
- Two-to-eight shot (2-8 examples): 60-80% accuracy
- Zero-shot (no examples): 30-40% accuracy
For simple tasks like sentiment analysis, even one example helps. For complex reasoning - like solving math problems - you need more. Chain-of-thought prompting, where you show the model how to think step-by-step, boosted GPT-3’s accuracy on math problems from 17.9% to 58.1%.
What Makes a Good Example?
Not all examples are created equal. A poorly chosen example can make the model go off track.
IBM’s 2023 research showed that using high-quality, relevant examples can improve accuracy by up to 25% compared to random ones. Here’s what to look for:
- Clarity: Clear input-output pairs. Avoid vague language.
- Relevance: Examples should match the task type. Don’t mix categories.
- Consistency: Format matters. If you use "Answer: Yes" in one example, use it in all.
- Order: Putting harder examples first improved sentiment analysis accuracy by 7.3% in one study.
Also, watch out for wording. Change one word - "Translate" to "Convert" - and performance can drop. ICL is sensitive. That’s why prompt engineering has become its own skill.

Where Is ICL Used Today?
ICL isn’t just a research curiosity. It’s everywhere.
- Customer service chatbots: 78% of enterprises use ICL to handle common questions without training new models.
- Content generation: 65% of marketing teams use ICL to generate product descriptions, ad copy, or social posts.
- Legal and medical analysis: Lawyers and doctors use ICL to summarize documents, flag risks, or extract key points - even when labeled data doesn’t exist.
- Financial reporting: 42% of finance teams use ICL to turn raw data into structured summaries.
The prompt engineering market hit $1.2 billion in 2023 and is projected to grow to $8.7 billion by 2027. Why? Because companies are realizing: you don’t need to train AI to make it useful. You just need to talk to it right.
Limitations and Challenges
ICL isn’t perfect. It has real limits.
- Context window: Most models handle 4K to 128K tokens. If your examples are too long, you lose space for the actual question.
- Task dependency: ICL works great for classification, translation, summarization. It struggles with tasks requiring deep domain knowledge (like diagnosing rare diseases) or multi-step planning.
- Inconsistent behavior: The same prompt might work on GPT-4 but fail on Llama 3.1. Different models handle ICL differently.
- Example quality: If your examples are biased, incomplete, or confusing, the model will follow that path.
And here’s the big debate: Is ICL really learning? Some experts, like Yann LeCun, say it’s just pattern matching. Others, like Ilya Sutskever, call it an emergent property of scaling - proof that bigger models do things we didn’t expect.
MIT’s Ekin Akyürek proved that LLMs can learn tasks from synthetic data they’ve never seen. That suggests it’s more than just memorization. But we still don’t fully understand how it works.
The Future of In-Context Learning
ICL is evolving fast.
- Longer context: Anthropic’s Claude 3.5 is targeting 1 million tokens by late 2024. That means hundreds of examples in one prompt.
- Smarter examples: Researchers are building tools that automatically select the best few examples - reducing the need for manual effort.
- Warmup training: A new technique that fine-tunes models briefly on prompt-like data before deployment. It improves ICL performance by 12.4% on average.
- Instruction tuning: Training models on thousands of task instructions makes them better at ICL, even with fewer examples.
Gartner predicts that by 2026, 85% of enterprise AI apps will use ICL as their main adaptation method - not fine-tuning. That’s because it’s faster, cheaper, and more flexible.
What does this mean for you? If you’re using AI today, you’re probably already using ICL - even if you don’t realize it. The future of LLMs isn’t about training more models. It’s about teaching them better.
Can in-context learning replace fine-tuning entirely?
Not always. ICL works great for quick, low-cost adaptations - like answering customer questions or summarizing documents. But if you need high accuracy on a very specific task with lots of data - like detecting fraud in financial transactions - fine-tuning still outperforms ICL. The best approach often combines both: use ICL for rapid prototyping, then fine-tune if needed.
Why does adding more examples sometimes make performance worse?
LLMs have a context window limit. When you add too many examples, the model runs out of space to process the actual question. Also, attention mechanisms get overwhelmed. Too many examples can introduce noise or conflicting patterns, confusing the model. Most tasks peak at 2-8 examples. Beyond that, accuracy drops.
Is in-context learning the same as few-shot learning?
Yes, essentially. "Few-shot learning" is the broader term from machine learning. "In-context learning" is how LLMs do it - by using examples inside the prompt, not by updating weights. So all ICL is few-shot learning, but not all few-shot learning is ICL (some methods still involve training).
Do all large language models support in-context learning?
Most modern LLMs do - GPT-3.5, GPT-4, Llama 3.1, Claude 3, and Gemini all support it. But performance varies. Some models are better at following patterns, others handle complex reasoning better. It’s not a yes/no feature - it’s a spectrum of effectiveness.
Can ICL work with non-text data like images or audio?
Not directly. ICL as it exists today only works with text. But multimodal models - like GPT-4V or Claude 3 - can combine text prompts with images. You can show an image and say, "This is a cat. What is this?" and the model learns from that. So while ICL itself is text-based, the concept is being extended to other data types.
Ashton Strong
February 4, 2026 AT 00:20In-context learning is one of the most elegant breakthroughs in modern AI. The fact that we can guide a model’s behavior without touching its weights is nothing short of revolutionary. It shifts the entire paradigm from "train more" to "prompt better." This isn’t just efficiency-it’s a philosophical shift in how we interact with intelligence.
For enterprises, this means faster iteration, lower costs, and democratized access to AI capabilities. No longer do you need a team of ML engineers to deploy a simple classification task. A product manager with a good prompt can do it in minutes.
The real magic? It works across domains. Legal, medical, finance-each with their own jargon, structure, and nuance-and yet, with the right examples, the model adapts. It’s like giving a brilliant intern a cheat sheet before their first client meeting.
What’s even more impressive is how consistently it scales. The performance curve isn’t linear; it plateaus around 2–8 examples, which means we’ve found a sweet spot that’s both effective and economical.
And yes, context window limits are real, but with models pushing toward 1M tokens, we’re approaching a future where entire datasets can be included as context. Imagine feeding a model a full contract, five precedents, and a summary template-all in one prompt.
This isn’t a stopgap. It’s the new baseline for enterprise AI.
Let’s not forget: prompt engineering is now a core competency. The best models are only as good as the guidance they’re given. And that’s empowering. We’re not just users-we’re teachers.
Steven Hanton
February 5, 2026 AT 01:07It’s fascinating how in-context learning blurs the line between memorization and reasoning. We used to assume that if a model didn’t update its weights, it couldn’t truly "learn." But the evidence suggests otherwise-especially with synthetic data tasks where the model has no prior exposure.
It makes me wonder: if the model is extracting patterns from examples without training, is it developing an internal representation of the task? Or is it just a very sophisticated pattern-matching engine?
The layer 14 insight is particularly compelling. It implies that the model doesn’t need to process every token to complete the task. That has huge implications for efficiency. We might soon see architectures that dynamically route computation based on early task recognition.
I’d love to see more research on how different architectures handle ICL. Is this a property of transformer attention, or something deeper? And why do some models outperform others even with identical prompts?
Also, the drop-off beyond 8 examples is counterintuitive. It suggests that less is more-not just in design, but in cognition. Maybe the model gets distracted by noise, or the examples start competing for attention.
Either way, this is one of those rare cases where the simplest solution turns out to be the most powerful.
Pamela Tanner
February 6, 2026 AT 18:26One thing that’s often overlooked: consistency in formatting. If your examples switch between "Answer: Yes" and "Yes," or use inconsistent capitalization, punctuation, or spacing, the model will mirror that chaos.
I’ve seen teams spend hours debugging poor performance-only to realize the issue was a missing period in one example.
Also, order matters more than people think. Putting a complex example first primes the model for abstraction. A simple example first can anchor it to surface patterns.
And please, stop using random internet examples. If you’re doing medical summarization, use real clinical notes-not made-up sentences from a blog. The model picks up on the tone, the structure, even the bias.
High-quality prompt engineering isn’t about clever wording. It’s about precision, discipline, and attention to detail. It’s not magic. It’s craftsmanship.
And yes, this is why I’m teaching my students to treat prompts like code: version-controlled, tested, documented, and peer-reviewed.
Kristina Kalolo
February 8, 2026 AT 13:00The fact that ICL works at all is still surprising. We built models to predict the next word, and somehow, by stacking a few examples, we’ve unlocked task generalization. It’s like teaching a dog to fetch by showing it three different sticks-it doesn’t understand "fetch," but it learns the pattern.
What’s interesting is how unreliable it can be. Same prompt, different model, different result. GPT-4 nails it. Llama 3.1 stumbles. Why? We don’t know.
And the sensitivity to wording? I tested a sentiment analysis prompt with "This movie is great" versus "This film is excellent." The model treated them as different tasks.
It feels less like intelligence and more like statistical mimicry with a very large memory. But it works. And that’s what matters for now.
I’m not convinced this is true learning. But I’m not convinced it needs to be. If it solves the problem, who cares how it does it?
ravi kumar
February 9, 2026 AT 07:21I use ICL every day for customer support replies in Hindi-English mix. Works like charm. No training. Just show 3 examples, and model understands tone, slang, even regional phrases.
One example enough for simple queries. For complaints, need 5–6. Too many? Model gets confused. Like overloading a brain.
Also, format matters. Always use same structure. "User: ...\nAgent: ..."
Best part? No server cost. Just API call. Perfect for small teams like mine.
Megan Blakeman
February 10, 2026 AT 23:27Okay, but... what if the examples are biased? Like, what if you give it five examples where "CEO" is always male and "nurse" is always female? Does the model just absorb that? And then spit it back out like it’s truth?
I’m not saying we shouldn’t use ICL-I love how fast it is! But we’re handing over so much power to something that doesn’t understand ethics, just patterns.
It’s like giving a child a textbook with only one version of history and expecting them to know the whole story.
Also, I’ve seen prompts where the model starts hallucinating because the examples were too vague. "Summarize this" with no structure? Chaos.
So yes, ICL is amazing. But it’s also a mirror. And if we feed it garbage, it gives us back our own flaws. With perfect grammar.
:/
Akhil Bellam
February 10, 2026 AT 23:57Let’s be honest-this isn’t "learning." It’s glorified copy-paste with attention weights. You think you’re teaching the model? No-you’re just triggering a statistical echo chamber.
And don’t get me started on "prompt engineering" as a skill. It’s not engineering. It’s voodoo with a Python script.
Companies are paying $200/hour for people to tweak punctuation because they don’t understand the underlying architecture. Pathetic.
Meanwhile, real AI research-like causal reasoning, symbolic integration, or grounded learning-is being ignored because ICL is cheap and flashy.
Yann LeCun is right. This isn’t intelligence. It’s a parlor trick with a billion parameters.
And yet... it works. Which is why everyone’s pretending it’s magic. Don’t be fooled. The emperor has no clothes-just a very well-trained autocomplete.
Amber Swartz
February 11, 2026 AT 09:01Okay, but I tried ICL yesterday and it wrote my entire client email in ALL CAPS and called my boss "the great one." I had to delete it. I cried. I’m not okay.
Also, I gave it 8 examples and it started talking about dinosaurs. Why? WHY?
And then I switched models and it said "I’m not trained to do this"-like it had feelings.
WHY IS AI SO UNRELIABLE??
Also, I read somewhere that if you add "Think step by step" it gets smarter? Is that real??
I just want my AI to not embarrass me in front of my boss.
Someone please help.
😭