Large Language Models: Core Mechanisms and Capabilities Explained
 Dec, 15 2025
Dec, 15 2025
Large language models (LLMs) aren’t magic. They don’t understand language the way you or I do. But they’ve gotten terrifyingly good at pretending they do. If you’ve ever asked an AI to write an email, explain quantum physics in plain English, or debug your Python script, you’ve interacted with one. These models power chatbots, code assistants, and even medical summary tools. But how do they actually work? And why are they so different from older AI systems?
How LLMs Process Language: From Words to Numbers
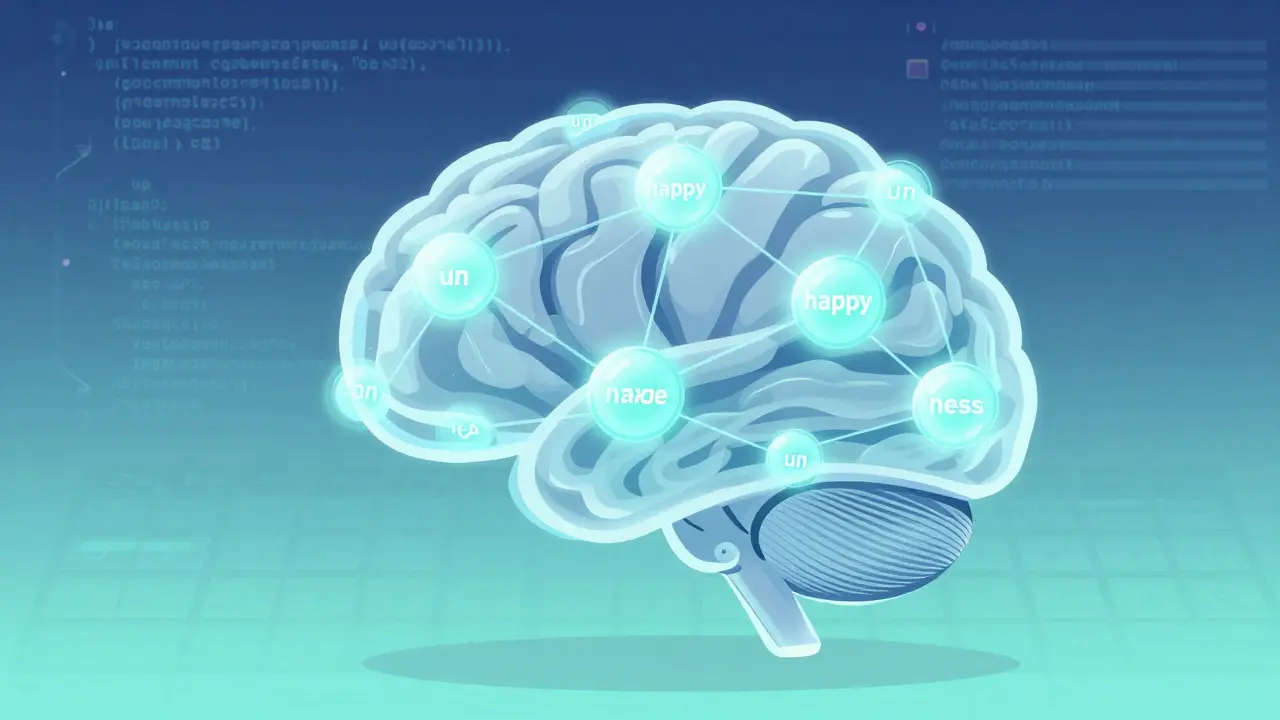
It all starts with breaking text into pieces. LLMs don’t read words like you do. They split them into smaller chunks called tokens. For example, the word "unhappiness" becomes three tokens: "un", "happy", and "ness". This is done using an algorithm called Byte Pair Encoding. Why? Because it lets the model handle rare or complex words by combining common parts. Modern models use vocabularies between 32,000 and 100,000 tokens. That’s far more efficient than trying to store every possible word in the English language.
Once tokens are identified, each one gets turned into a long list of numbers - an embedding. Think of it like assigning coordinates to a word in a high-dimensional space. Words with similar meanings end up close together. "King" and "queen" might be near each other. "Run" and "jog" are closer than "run" and "ocean". These embeddings are the foundation. Everything the model learns happens in this numeric space.
The Transformer: The Engine Behind the Magic
Before 2017, most AI models processed text one word at a time, like reading a book from left to right. That was slow and struggled with long sentences. Then came the Transformer architecture - a breakthrough from Google researchers. Instead of processing words in sequence, Transformers look at the whole sentence at once. This is what makes them fast and powerful.
The heart of the Transformer is the attention mechanism. Imagine you’re reading this sentence: "The cat sat on the mat, which was black." You instantly know "black" describes the mat, right? But what if the sentence was longer? Or if "black" appeared halfway through a 5,000-word paragraph? That’s where attention comes in. The model calculates a weight for every word in relation to every other word. It asks: "Which words should I pay the most attention to when predicting the next one?"
These weights aren’t fixed. They change based on context. In one sentence, "bank" might mean a river edge. In another, it means a financial institution. The attention mechanism figures that out by looking at surrounding words. Modern LLMs use multiple "attention heads" - often 16 to 96 - each focusing on different relationships. One head might track pronouns. Another might track cause and effect. Together, they build a rich understanding of the text.
Layers of Understanding: How Depth Creates Intelligence
Transformers are built in layers - like an onion. A typical LLM has anywhere from 24 to 96 layers. Each layer refines the meaning further. Early layers handle basic stuff: identifying parts of speech, recognizing names, spotting punctuation. Deeper layers do complex reasoning: connecting ideas across paragraphs, inferring tone, even spotting contradictions.
Each layer has two main parts. First, the attention mechanism, which we just talked about. Then, a feedforward network - basically a set of mathematical functions that transform the data. After attention picks out what’s important, the feedforward layer processes it. This happens over and over, with each layer adding more nuance.
Think of it like a team of analysts. The first team reads the raw text. The second team highlights key facts. The third team connects those facts to broader patterns. The final team writes the answer. That’s what happens inside an LLM - just with numbers instead of people.

Scale Matters: Why Bigger Is (Usually) Better
Size isn’t everything - but it’s a big deal. The number of parameters in an LLM tells you how many internal connections it has. GPT-3 had 175 billion. PaLM 2 had 340 billion. Google’s Gemini Ultra is rumored to have over a trillion. More parameters mean the model can store more patterns, recognize subtler relationships, and handle more complex tasks.
But there’s a rule: you need about 20 tokens of training data for every parameter. So a 100-billion-parameter model needs 2 trillion tokens to train properly. That’s like reading every book in a large university library - multiple times. Training these models takes thousands of high-end GPUs running for weeks. The cost? $10 million to $20 million. That’s why only big tech companies and well-funded labs can build them from scratch.
Still, size alone doesn’t make a model smart. A 10-billion-parameter model fine-tuned for medical reports can outperform a 100-billion-parameter general-purpose model in that specific task. That’s why fine-tuning matters.
Types of LLMs: Generic, Instruction-Tuned, and Dialog-Tuned
Not all LLMs are the same. There are three main types, each built for a different job:
- Generic models (like GPT-2) predict the next word based on what came before. They’re good for text completion but don’t follow instructions well.
- Instruction-tuned models (like Flan-T5) are trained to follow commands: "Summarize this", "Translate to French", "Explain like I’m 10." They’re used in tools that need to respond to user prompts.
- Dialog-tuned models (like ChatGPT or Claude 3) are optimized for conversation. They remember context across multiple turns, adjust tone, and handle follow-ups naturally. These are the ones you chat with.
The difference between them isn’t just training data - it’s how they’re fine-tuned. A generic model learns from books and websites. An instruction-tuned model learns from pairs of commands and correct answers. A dialog-tuned model learns from real conversations.

Autoregressive vs. Masked: Two Ways of Thinking
LLMs predict text in two main ways:
- Autoregressive models (like GPT, Llama, Claude) predict one token at a time, left to right. Given "I like to eat", they guess the next word: "ice cream". This is how chatbots generate responses - step by step.
- Masked models (like BERT) fill in blanks. Given "I like to [MASK] [MASK] cream", they predict "eat" and "ice". These are better at understanding context than generating text.
Most modern LLMs are autoregressive because they’re better at open-ended tasks like writing, coding, or answering questions. But some combine both approaches for improved accuracy.
What LLMs Can - and Can’t - Do
LLMs can write essays, summarize legal documents, generate code in six languages, and even draft emails in your boss’s tone. Companies use them to automate customer service, analyze research papers, and create marketing copy. In 2024, 67% of Fortune 500 companies were using LLMs for at least one business function.
But they have serious limits. They don’t know facts - they predict likely sequences. That’s why they "hallucinate" - confidently making up false information. A model might say the Eiffel Tower is in Berlin. It’s not lying. It just thinks that’s the most probable answer based on patterns in its training data.
They’re also bad at math. Ask an LLM to calculate 123 × 456, and it might guess 56,000. It doesn’t understand numbers - it’s predicting what numbers usually come after "123 times 456". For precise math, you need a calculator. For logic, you need a human.
And they’re expensive. Training a single model uses as much electricity as 100 homes use in a year. That’s why there’s a push for smaller, smarter models - called "small language models" (SLMs) - that get 80% of the performance with 10% of the cost.
What’s Next: Smarter, Faster, Greener
By 2025, the biggest changes aren’t about size - they’re about efficiency. Google’s Gemini 1.5, released in late 2024, can handle a million tokens in one go. That’s enough to process an entire novel or a year’s worth of customer support logs in a single prompt.
Meta’s Llama 3, open-sourced in early 2025, supports 100 languages and runs well on consumer hardware. That’s huge for developers outside big tech.
Techniques like Retrieval-Augmented Generation (RAG) are helping reduce hallucinations. Instead of guessing, the model pulls facts from trusted databases before answering. Prompt engineering tricks like "Chain-of-Thought" - where you ask the model to think step by step - improve accuracy by 15-25%.
Future models might blend neural networks with symbolic reasoning - like adding a logic engine to an LLM. That could fix their biggest flaw: inconsistency. Right now, they’re brilliant pattern matchers. The goal is to make them true thinkers.
What makes LLMs different from older AI models?
Older models like RNNs and LSTMs processed text one word at a time, making them slow and unable to handle long-range context. LLMs use the Transformer architecture, which processes entire sentences in parallel using attention mechanisms. This lets them understand relationships between words far apart in a text - like connecting "he" to "the scientist" five sentences back. They’re faster, more accurate, and scalable.
Can LLMs really understand what they’re saying?
No. LLMs don’t have consciousness, beliefs, or understanding. They predict the most statistically likely next word based on patterns in their training data. They can mimic understanding, generate coherent responses, and even sound empathetic - but they don’t feel or know anything. Think of them as extremely advanced autocomplete.
Why do LLMs make things up?
They’re trained to predict likely text, not to verify facts. If the training data contains conflicting or incorrect information, the model learns those patterns. When uncertain, it fills gaps with plausible-sounding guesses - called hallucinations. Techniques like Retrieval-Augmented Generation (RAG) help by grounding responses in real data, but they’re not foolproof.
How much does it cost to run an LLM?
Training a 100-billion-parameter model costs $10-20 million and uses around 1,000 NVIDIA A100 GPUs for 30-60 days. Running inference (using the model) is cheaper but still expensive at scale. A single query might cost a fraction of a cent, but millions of queries per day add up. For businesses, optimizing prompts and using smaller models helps reduce costs.
Are open-source LLMs as good as proprietary ones?
Yes, in many cases. Meta’s Llama 3 and Mistral AI’s models rival commercial ones in performance, especially after fine-tuning. Open-source models give developers control, transparency, and the ability to customize. The trade-off is less polish, fewer safety filters, and no official support. For most technical users, they’re the best choice.
What’s the future of LLMs?
Expect smaller, faster models optimized for specific tasks. Hybrid systems combining neural networks with symbolic logic will improve reasoning. Multimodal models that understand text, images, and audio will become standard. Regulatory frameworks like the EU AI Act will push for safety and transparency. And energy-efficient training methods will make LLMs more sustainable.
Karl Fisher
December 16, 2025 AT 18:28Okay but let’s be real - LLMs are just glorified autocomplete on steroids. I mean, I’ve seen them write sonnets in the voice of Shakespeare while simultaneously debugging Python and composing a breakup letter to my ex. It’s not intelligence, it’s performance art. And the fact that people treat them like oracle machines? Chilling. We’re outsourcing our thinking to a statistical ghost that doesn’t know what a tree is, but can tell you how one would feel about climate change. The uncanny valley of language, baby.
Buddy Faith
December 17, 2025 AT 13:51Man i just use it to write my grocery list and it works great. no need to overthink it. if it helps me get through the day, that’s enough.
Scott Perlman
December 17, 2025 AT 23:07Honestly i think this stuff is amazing. i used to spend hours writing emails and now i just say what i mean and it cleans it up. no more staring at a blank screen. it’s like having a buddy who’s really good with words but doesn’t get tired. we’re not replacing humans here, we’re just making them better.
Sandi Johnson
December 18, 2025 AT 16:33Oh wow so the AI doesn’t understand anything? Groundbreaking. I’m shocked. Next you’ll tell me the toaster doesn’t actually know what bread is. But hey, if it can write my quarterly report in the tone of a motivational speaker while pretending it’s my boss, who am I to judge? I’ll take the magic over the truth any day.
Eva Monhaut
December 19, 2025 AT 00:24What fascinates me most isn’t the scale or the math - it’s how these models mirror the chaos of human language. They absorb everything: poetry, memes, legal jargon, Reddit rants, and 18th-century letters. They don’t understand meaning, but they’ve learned rhythm, cadence, and emotional texture. That’s why they feel alive. Maybe we’re not teaching machines to think - we’re teaching them to echo us. And honestly? That’s kind of beautiful. And terrifying. And very human.
mark nine
December 20, 2025 AT 20:59Been using llama 3 on my old laptop for coding help. Surprisingly smooth. No need for the trillion parameter monsters. Most tasks don’t need that much muscle. Just give it clear prompts and it’ll get you 90% there. The rest? That’s where you come in. Keep it simple, keep it real.