NLP Pipelines vs End-to-End LLMs: When to Use Each for Real-World Language Tasks
 Sep, 6 2025
Sep, 6 2025
What’s really going on with NLP and LLMs today?
You’ve probably heard that LLMs are replacing old-school NLP pipelines. That’s not true - at least not yet. In fact, the smartest companies aren’t choosing one or the other. They’re using both, together. And if you’re building something that needs to work reliably, cheaply, and at scale, you need to understand why.
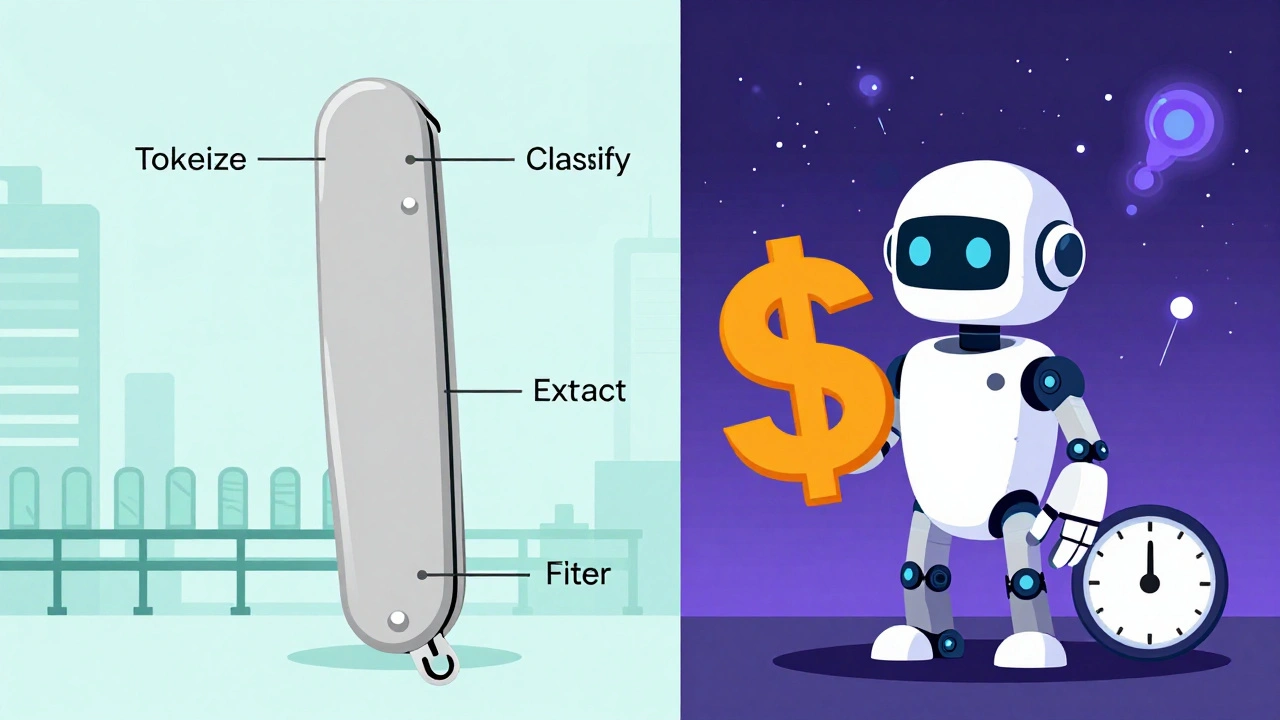
Think of NLP pipelines like a Swiss Army knife with separate tools: one blade for cutting, one for opening bottles, one for screwing in bolts. Each piece does one thing well. LLMs, on the other hand, are like a robot that can do all those things - but sometimes it forgets what you asked for, takes 10 seconds to respond, and charges you $5 every time you turn it on.
Here’s the real question: When should you build a pipeline? When should you just prompt an LLM? And when should you do both?
NLP pipelines: precise, fast, cheap - but rigid
NLP pipelines have been around since the 1950s. They’re not new. But they’re still the backbone of most production systems that can’t afford mistakes.
These systems break language processing into clear steps: tokenize the text, tag parts of speech, extract named entities, classify sentiment, filter spam - each handled by a specialized model or rule. You chain them together like assembly line workers.
Why does this matter? Because each step is predictable. If your sentiment analyzer misclassifies a review as positive when it’s negative, it doesn’t mess up your entity extraction. The error stays contained. That’s huge for compliance, finance, healthcare - anywhere audit trails matter.
Performance? Unbeatable. On a basic CPU, a well-tuned pipeline can process 5,000 tokens per second with under 10 milliseconds of latency. That’s fast enough for live chat moderation, real-time search suggestions, or product categorization on an e-commerce site handling tens of thousands of requests per minute.
Cost? Around $0.0001 to $0.001 per 1,000 tokens. For a company processing 10 million product descriptions a month, that’s $10 to $100. An LLM doing the same job? $200 to $1,200. That’s not a difference - it’s a chasm.
And you don’t need a GPU. You can run these on a Raspberry Pi if you need to. Edge devices. Microservices. Legacy servers. All of it works.
End-to-end LLMs: flexible, powerful - but unpredictable
LLMs changed everything by removing the need to build pipelines. Instead of training separate models for every task, you just give the model a prompt and let it figure it out.
Want to summarize a legal document? Write: “Summarize this in three bullet points, using simple language.”
Want to extract relationships between drugs and side effects from medical papers? Just paste the text and ask: “What are the key drug-side effect pairs mentioned here?”
That’s magic. No retraining. No new code. No adding new modules. One model handles everything.
But here’s the catch: LLMs are not deterministic. Ask the same question twice, and you might get two different answers. That’s fine for generating marketing copy. It’s a disaster for classifying insurance claims or flagging regulatory violations.
They also hallucinate. Studies show 15-25% of complex reasoning outputs from LLMs contain made-up facts. In healthcare, that’s not a bug - it’s a liability. In finance, it’s a regulatory violation.
And then there’s cost. GPT-3.5 costs about $0.002 per 1,000 tokens. GPT-4? Up to $0.12. If you’re processing 1 million customer support tickets a month, you’re looking at $2,000 to $120,000 just in API fees. Add in infrastructure, monitoring, and prompt tuning, and you’re talking enterprise budgets.
Latency is another killer. On average, LLMs take 100ms to 2 seconds per request. That’s fine for batch processing. It’s unbearable for live chat or search autosuggest. One study found a 1.2-second delay caused a 37% drop-off in user engagement.

When to use NLP pipelines
Use an NLP pipeline when you need:
- Speed - under 50ms response time for real-time apps
- Cost control - processing millions of items with minimal spend
- Reliability - consistent, repeatable outputs for compliance
- Transparency - you need to explain why a decision was made
- Low-resource environments - running on edge devices or legacy systems
Real-world examples:
- An e-commerce platform categorizing 10,000 products per minute using rule-based keyword matching and entity extraction - cost: $0.50/hour.
- A financial institution flagging suspicious transactions based on named entity patterns (e.g., “transfer to offshore account”) - accuracy: 93%, false positives: 2%.
- A healthcare app extracting diagnosis codes from doctor’s notes using spaCy and custom regex rules - cost per query: $0.0003.
These systems don’t need to be smart. They need to be precise. And they are.
When to use end-to-end LLMs
Use an LLM when you need:
- Contextual understanding - interpreting sarcasm, nuance, or implied meaning
- Creative generation - writing emails, product descriptions, summaries
- Open-ended reasoning - answering questions that aren’t predefined
- Multi-language support - handling dialects, code-switching, or low-resource languages
- Fast prototyping - testing ideas without building entire pipelines
Real-world examples:
- A research team analyzing 500 scientific papers on battery materials, asking the LLM to extract “material → performance improvement” relationships - accuracy: 87%, no manual labeling needed.
- A customer support bot generating personalized apology emails after a shipping delay - tone adjusted per user history.
- A legal startup summarizing court rulings in plain English for non-lawyers - capturing intent, not just keywords.
These tasks are messy. They don’t have clear rules. That’s where LLMs shine.
The hybrid approach: the real secret weapon
Most companies that get this right don’t pick one. They combine them.
Here’s how it works:
- Preprocess with NLP - clean the input. Extract entities, remove noise, detect language, classify intent.
- Feed clean data to LLM - now the LLM isn’t guessing what the user meant. It’s working with structured, reliable inputs.
- Validate output with NLP - check if the LLM’s answer contains valid entities, follows format rules, or contains hallucinations.
This is called “NLP-guided prompting.” And it’s a game-changer.
One company using this method cut LLM token usage by 65% and improved accuracy by 9 percentage points. Why? Because the LLM wasn’t wasting time on bad inputs. It was given clean, focused data.
Another example: Elastic’s ESRE engine uses BM25 (classic NLP search) to find the top 10 relevant documents, then lets an LLM rank them. Result? 94% relevance - 12 points higher than LLM-only search - with 60% lower latency.
And cost? A hybrid system can reduce LLM usage by 80-90%. You only call the expensive model when the simple system is unsure.

What’s failing in pure LLM deployments
Too many teams go all-in on LLMs because it’s trendy. Then they hit walls.
- Prompt drift - The model’s responses slowly get worse over time. No one retrained it. No one noticed. 63% of enterprises report this.
- Compliance failures - The EU AI Act requires deterministic outputs for high-risk systems. Pure LLMs fail this. Hybrid systems pass.
- Unexplainable decisions - “Why did you reject this loan?” “I don’t know. The model said so.” That’s not acceptable in banking.
- Cost explosions - One startup spent $18,000/month on LLMs for customer service. Switched to hybrid. Cut it to $2,000. Accuracy improved.
Even OpenAI and Anthropic are pushing hybrid solutions now. Anthropic’s Claude 3.5 introduced “deterministic mode” - but it’s 30% slower. That’s not a fix. It’s a workaround.
What you should build today
Start simple. Ask yourself:
- Is this task well-defined? (e.g., extract email addresses, classify product type)
- Do I need to explain how the decision was made?
- Am I processing more than 100,000 items per month?
- Do I need sub-100ms responses?
If you answered yes to any of these - use an NLP pipeline.
If your task is open-ended, creative, or requires deep context - try an LLM.
But if you’re serious about scale, cost, and reliability - build a hybrid.
Here’s a simple blueprint:
- Use spaCy or NLTK to clean and extract entities from input.
- Use those entities to build a precise prompt for an LLM (like Llama-3 or Claude).
- Run a rule-based validator on the LLM’s output to catch hallucinations or format errors.
- Log everything. Track cost per task. Monitor accuracy over time.
One engineer on Reddit summed it up: “We run spaCy first, then Llama-3 for relationships, then validate with rules. Cut our error rate by 63%. Costs under $500/day for 2 million requests.”
That’s not magic. That’s engineering.
Future-proofing your NLP strategy
By 2027, Gartner predicts 90% of enterprise language systems will be hybrid. The era of “LLMs replace everything” is over.
NLP pipelines won’t disappear. They’ll become the foundation. LLMs won’t replace them. They’ll become the brain - but only when the body (the pipeline) gives it the right data.
The future isn’t one or the other. It’s both - working together, each doing what it does best.
Don’t chase the latest model. Build the right system.
Steven Hanton
December 14, 2025 AT 01:27I've seen teams go all-in on LLMs and then panic when the model starts hallucinating insurance claim codes. The pipeline approach isn't sexy, but it's the difference between a system that works and one that gets you sued.
Pamela Tanner
December 14, 2025 AT 14:22Let’s be precise: NLP pipelines aren’t ‘old-school’-they’re rigorously validated. LLMs are probabilistic black boxes. In regulated industries, that’s not innovation-it’s negligence. If your model can’t explain why it rejected a claim, you’re not building AI-you’re building liability.
ravi kumar
December 15, 2025 AT 04:57in india, we use pipelines for customer support because we can’t afford gpt-4 prices. a simple rule-based system with regex for ticket routing cuts our costs by 90%. no one needs a 2-second delay to answer ‘where is my order?’
Megan Blakeman
December 15, 2025 AT 06:14OH MY GOSH, THIS IS SO TRUE!!! I work in healthcare and we tried an LLM for diagnosis code extraction... it said 'diabetes' was a type of 'car'... I cried... 😭 Then we added spaCy before the LLM and now it's perfect!!! We're basically using AI like a really smart intern who needs a checklist!!!
Akhil Bellam
December 16, 2025 AT 01:13Pathetic. You’re still clinging to rule-based spaghetti from the 2000s? LLMs are the future-period. Pipelines are for engineers who can’t write a coherent prompt. If you need a ‘validator’ after the LLM, you didn’t prompt it right. You’re not ‘engineering’-you’re debugging your own incompetence. GPT-4 Turbo is cheaper than your dev team’s coffee budget.
Amber Swartz
December 17, 2025 AT 20:04So... let me get this straight... you're saying we shouldn't use LLMs because they're 'unreliable'? But we all know the real problem is that LLMs are too smart for their own good. They see the truth. They see how broken our systems are. And they refuse to play along. That's why they hallucinate. They're not broken-they're bored. And honestly? I get it. Who wants to classify spam for the 10,000th time? I'd hallucinate too.
Robert Byrne
December 19, 2025 AT 14:11You’re all missing the point. The hybrid approach isn’t ‘smart’-it’s the bare minimum. Anyone who’s worked with production LLMs knows you need validation layers. The real crime is companies deploying LLMs without any guardrails and calling it ‘AI innovation.’ That’s not engineering. That’s corporate negligence. And if your CTO thinks GPT-4 is a drop-in replacement for a 10-year-old NLP system, they’re not leading-they’re endangering the business. Stop romanticizing chaos.