Target Architecture for Generative AI: Data, Models, and Orchestration
 Jul, 12 2025
Jul, 12 2025
Most companies think building a generative AI system is about picking the best model-GPT-4, Llama 3, or Gemini. But here’s the truth: the model is the easiest part. The real challenge? Getting the data right, connecting it to the model, and making the whole thing work reliably in production. Without a solid architecture, even the most powerful AI will fail. It won’t hallucinate less. It won’t be faster. It won’t be trusted. And it certainly won’t save you money.
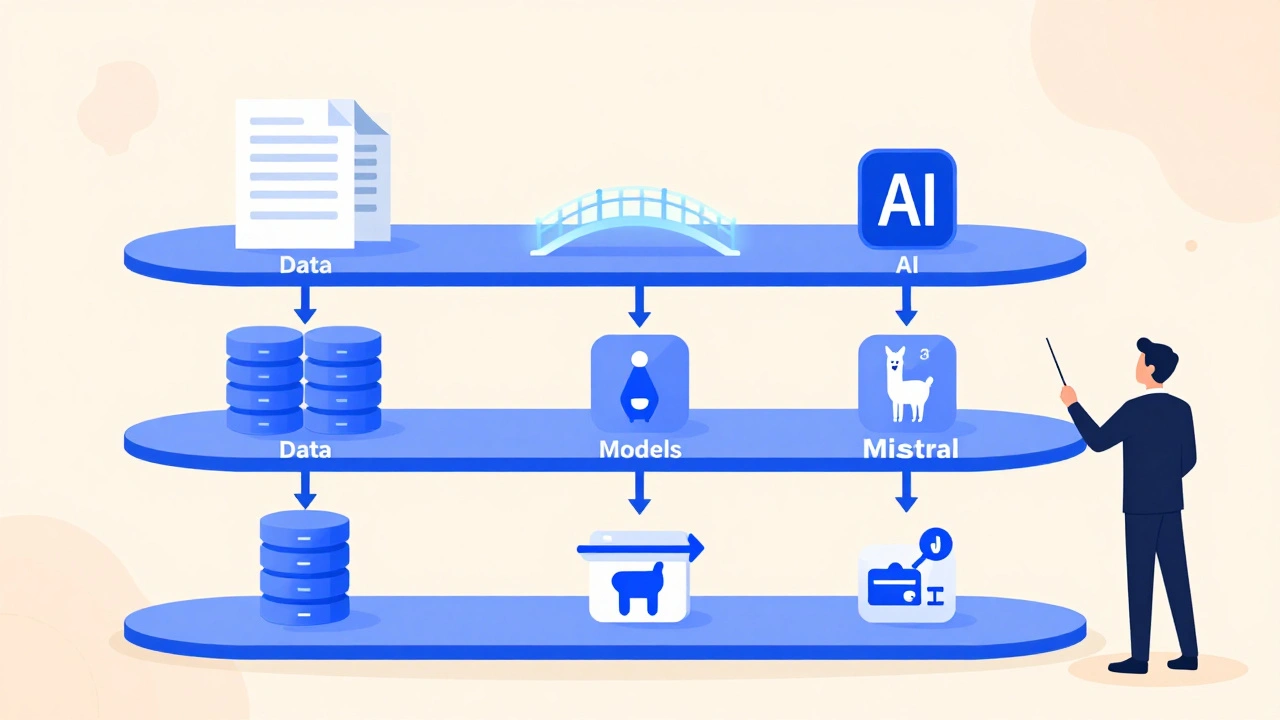
Data: The Hidden Foundation
Dr. Fei-Fei Li put it bluntly: 70% of generative AI failures come from bad data, not bad models. If your training data is messy, outdated, or biased, no amount of tuning will fix it. Enterprise teams spend 45-60% of their time just preparing data-not training models. That’s not inefficiency. That’s the job.
Good data architecture isn’t just about storage. It’s about structure. You need clean, labeled, domain-specific data. For example, a healthcare company using AI to summarize patient notes needs clinical terminology, not generic web text. A finance team building a report generator needs SEC filings, earnings calls, and internal compliance docs-not Reddit threads.
Vector databases like Pinecone or Azure Cosmos DB are now standard because they let you store and search embeddings-numerical representations of text, images, or audio. These aren’t just fancy search tools. They’re the bridge between your company’s knowledge and the AI’s understanding. Gartner found that architectures using vector databases outperform traditional SQL-based ones by 22% in retrieval accuracy. But they’re not magic. If you dump 10,000 PDFs into a vector store without chunking them properly, accuracy drops from 85% to 52%. That’s what happened at Atlassian before they fixed their document segmentation.
Data pipelines matter too. Snowflake’s Cortex and Google’s Vertex AI now automate ETL (Extract, Transform, Load) steps, cutting setup time by 35%. But if you’re building your own, expect to write custom Python scripts using Spark or Pandas. And don’t forget data drift. Google Cloud found that 63% of models degrade within six months because the data they see in production changes. You need monitoring. You need alerts. You need a way to retrain automatically.
Models: Bigger Isn’t Better
It’s tempting to go for the biggest model-Gemini Ultra at 1.8 trillion parameters, or GPT-4 Turbo. But size comes with cost. Training a model that big needs dozens of NVIDIA A100 GPUs and weeks of compute time. For most businesses, that’s overkill.
Real-world success comes from fine-tuning smaller models on your data. A 7B-parameter model, fine-tuned on your customer service logs, can outperform a 100B model trained on public internet data. Why? Because it understands your context. Your tone. Your rules. Your jargon.
And then there’s retrieval-augmented generation (RAG). Instead of stuffing everything into the model’s memory, RAG pulls in live data from your knowledge base when it answers. AWS showed this cuts hallucinations from 27% to 9%. That’s huge for legal, medical, or financial use cases where accuracy isn’t optional. But RAG only works if your data is well-organized. Bad retrieval = bad answers.
Open-source models like Llama 3 and Mistral are changing the game. You can run them on your own servers, control the updates, and avoid vendor lock-in. But they need more engineering. You’ll need ML engineers who know PyTorch, quantization, and inference optimization. Most companies underestimate this. AWS reports that teams without dedicated ML engineers take 3.2 times longer to deploy.
Orchestration: The Glue That Holds It Together
Think of orchestration as the conductor of an orchestra. The model is the violinist. The data is the sheet music. Orchestration makes sure they play in sync.
Without it, you get brittle, one-off systems. A chatbot that works in testing but crashes when real users ask unexpected questions. A report generator that breaks every time the CRM updates its schema. That’s why Dr. Andrew Ng calls orchestration frameworks the "unsung heroes" of production AI.
Tools like LangChain, LlamaIndex, and Microsoft’s Azure AI Studio let you chain steps: retrieve data → clean it → prompt the model → validate the output → log feedback → trigger retraining. This isn’t scripting. It’s building a system that learns from its mistakes.
For example, Mayo Clinic’s diagnostic assistant uses a feedback loop. Doctors correct the AI’s suggestions. Those corrections are fed back into the training pipeline. Result? A 29% boost in diagnostic accuracy. That’s not luck. That’s orchestration.
Security is part of orchestration too. Prompt injection attacks-where users trick the AI into revealing secrets or running malicious code-are the #1 vulnerability. OWASP reported 57% of implementations lack basic protections. Your orchestration layer needs filters. Input sanitization. Output validation. And role-based access control so only authorized people can tweak prompts or access sensitive data.

Infrastructure: What You Actually Need
You don’t need a $2 million AI supercomputer. But you do need the right hardware.
For training: 8-16 NVIDIA A100 or H100 GPUs. For inference (running the model in real time): 2-4 GPUs. Snowflake’s Q3 2024 data confirms this is the sweet spot for enterprise use. Cloud providers charge $14,500 per month on average to run a single generative AI app. That’s not sustainable if you’re not optimizing.
Use quantization. It reduces model size by 50% with minimal accuracy loss. Use caching. If ten people ask the same question, don’t run the model ten times. Store the answer. Use spot instances. They’re 70% cheaper than on-demand, and most AI workloads can tolerate brief interruptions.
And don’t forget energy. NVIDIA’s new Blackwell GPUs, released in October 2024, deliver 2.5x more performance per watt. If you’re scaling beyond a few models, efficiency isn’t optional-it’s financial.
Real-World Trade-Offs
Every architecture decision has a cost.
- Using a vendor like Snowflake? You get seamless data integration but a steep learning curve. Teams report needing 3-4 months of training just to use it well.
- Building your own with open-source tools? You save money but need 5-7 specialized roles: data engineers, ML engineers, DevOps, security experts, UX designers, domain specialists, and a product owner.
- Going all-in on RAG? You gain accuracy but add complexity. Each retrieval step is a potential failure point.
- Choosing a monolithic system? Easier to start, but impossible to update later. The industry is moving toward composable AI-modular pieces you swap in and out.
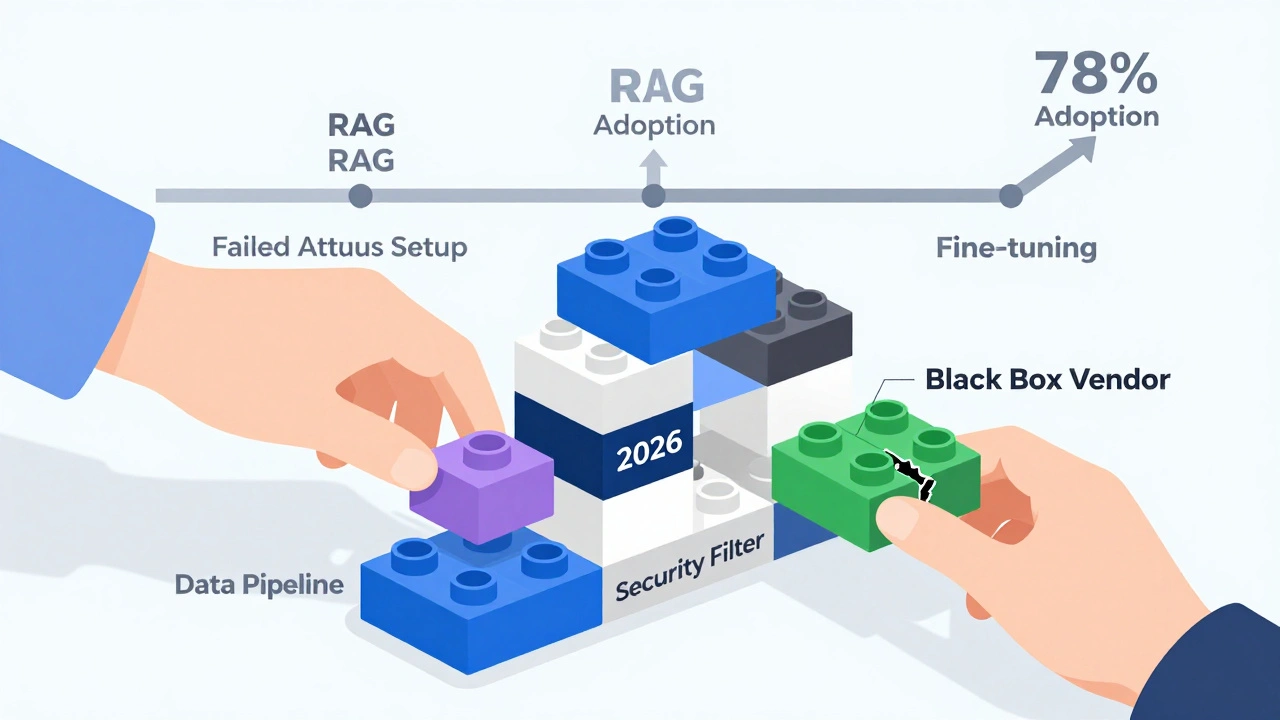
Atlassian’s Confluence AI rollout failed the first time because their vector database wasn’t configured right. Responses took 45 seconds. Users left. They fixed it by switching to semantic chunking and adding caching. Adoption jumped to 78%. The lesson? Architecture isn’t set-and-forget. It’s iterative.
What Works in 2025
Here’s what top performers are doing:
- Start small. Pick one high-value task-like summarizing support tickets or drafting internal memos.
- Build a feedback loop from day one. Let users rate answers. Use those ratings to improve.
- Use a hybrid model. Combine open-source LLMs with cloud APIs. You get control and scalability.
- Automate data pipelines. If you’re manually cleaning data, you’re doing it wrong.
- Measure everything. Track latency, accuracy, cost, and user satisfaction. If you can’t measure it, you can’t improve it.
By 2026, Gartner predicts 70% of enterprises will use composable AI-mixing and matching components like Lego bricks. The winners won’t be the ones with the biggest models. They’ll be the ones with the cleanest data, smartest orchestration, and strongest feedback loops.
What to Avoid
- Buying AI as a black box. Vendors promise "plug-and-play" solutions. They rarely deliver.
- Ignoring prompt security. Prompt injection attacks are rising fast. Treat prompts like SQL queries-sanitize them.
- Waiting for perfect data. You’ll never have it. Start with 80% clean data and improve over time.
- Skipping documentation. If you can’t explain how your AI works to a lawyer or auditor, you’re at risk under the EU AI Act.
The goal isn’t to build the fanciest AI. It’s to build one that works reliably, safely, and at scale. That takes architecture-not magic.
What’s the biggest mistake companies make with generative AI architecture?
They focus on the model instead of the data and orchestration. The model is only one piece. If your data is messy, your feedback loops are missing, or your security is weak, even the best AI will fail in production. Most teams spend 60% of their time fixing data issues-not training models.
Do I need a vector database for generative AI?
If you’re building a system that answers questions using your internal documents-like a customer support bot or legal assistant-then yes. Vector databases let you search through thousands of documents quickly using meaning, not keywords. Gartner found they improve retrieval accuracy by 22% compared to traditional databases. But if you’re just using a pre-trained model for simple text generation, you might not need one.
Is RAG better than fine-tuning?
It depends. Fine-tuning changes the model’s internal knowledge, which is great for consistent tone or style. RAG keeps knowledge external, so you can update facts without retraining. RAG reduces hallucinations by 67% (from 27% to 9%) according to AWS. But RAG needs high-quality data and smart retrieval. If your documents are poorly organized, RAG won’t help. Many teams use both: fine-tune for style, RAG for facts.
How much does it cost to run a generative AI system?
Average monthly costs range from $5,000 to $20,000 per application, depending on usage. Training a model from scratch can cost $100,000+. But most companies don’t need to train-they fine-tune. For inference (running the AI), 2-4 GPUs are enough. Use spot instances, caching, and quantization to cut costs by 50-70%. Flexera’s 2024 report shows the average is $14,500/month, but smart teams get it under $5,000.
Can I use open-source models in production?
Absolutely. Llama 3, Mistral, and Phi-3 are powerful, free, and can be run on your own servers. They’re used by banks, hospitals, and government agencies. But they require more engineering. You need ML engineers to optimize them, secure them, and monitor them. If you don’t have that team, a managed service like Azure AI Studio might be safer-even if it costs more.
How long does it take to build a generative AI architecture?
Most enterprise projects take 6-12 months. Data preparation alone takes 45-60% of that time. A simple chatbot might launch in 8 weeks if you use a vendor platform. A custom system with feedback loops, security, and multi-modal support? Expect 9-12 months. Bloomberg’s finance AI took 9 months: 2 months for data, 3 for models, 4 for orchestration. Rushing leads to failure.
What skills do I need on my team?
You need five core roles: 1) Data engineers (SQL, Python, Spark), 2) ML engineers (PyTorch, model optimization), 3) DevOps (cloud, containers, monitoring), 4) Security specialist (prompt injection, access control), and 5) Domain expert (someone who knows your business-healthcare, finance, etc.). Many companies try to skip the ML engineers. That’s why their projects stall.
Is generative AI regulated?
Yes. The EU AI Act (effective August 2024) requires documentation for high-risk systems-like those used in hiring, healthcare, or law enforcement. You must prove your data is unbiased, your model is explainable, and your feedback loops work. PwC found 22% of current implementations don’t meet these requirements. If you’re in finance, healthcare, or government, compliance isn’t optional.
selma souza
December 12, 2025 AT 15:54The notion that data is the "easiest part" is not just misleading-it's dangerously negligent. Without structured, auditable, and ethically sourced datasets, any generative system is a liability waiting to be exposed. Companies that treat data as an afterthought are not innovating; they're building legal and reputational time bombs.
James Boggs
December 13, 2025 AT 18:48Well said. I’ve seen teams waste months chasing model benchmarks while their data pipelines were a mess. Starting with clean, domain-specific data and a feedback loop cuts deployment time in half.
Addison Smart
December 15, 2025 AT 07:30There’s a deeper cultural issue here that no one talks about: AI architecture isn’t just technical-it’s organizational. The companies that succeed aren’t the ones with the most GPUs; they’re the ones where data engineers sit next to compliance officers, where ML teams have direct access to domain experts, and where leadership understands that iteration isn’t a bug-it’s the feature. Atlassian’s failure wasn’t a vector database misconfiguration-it was a failure of cross-functional alignment. The fix? Not better tech, but better communication. When doctors at Mayo Clinic corrected the AI’s diagnoses, they weren’t just improving accuracy-they were building trust. Trust that took months to earn, and seconds to lose if the system gave a wrong answer without context. That’s why orchestration isn’t about tools like LangChain-it’s about creating feedback loops that humanize technology. And yes, that means hiring people who care about the why, not just the how. The EU AI Act isn’t a burden; it’s a compass. It forces organizations to stop treating AI like a magic box and start treating it like a public service. If we can do that, we won’t just build better systems-we’ll build better societies.
Frank Piccolo
December 16, 2025 AT 21:04Let’s be real-most of these "architectures" are just expensive PowerPoint slides. You don’t need a vector database if you’re just summarizing internal memos. And no, RAG isn’t magic. I’ve seen teams spend six months on retrieval tuning while the model was garbage. If you’re not using GPT-4 Turbo or Claude 3 Opus, you’re already behind. Stop overengineering and just buy the damn API.
Barbara & Greg
December 16, 2025 AT 22:51It’s not about cost. It’s about accountability. If your AI hallucinates a medical diagnosis or misquotes a legal precedent, who pays? Not the engineer. Not the vendor. The patient. The client. The public. And yet, we still treat this like a software sprint. We need ethics boards for AI systems, not just ML engineers. This isn’t innovation-it’s institutional negligence dressed up as progress.