Why Smaller, Heavily-Trained AI Models Often Beat the Giants
 Apr, 8 2026
Apr, 8 2026
For years, the golden rule of AI was simple: bigger is better. If you wanted a smarter model, you added more parameters, more data, and more GPUs. This belief drove the race toward trillion-parameter behemoths. But a shift is happening. We're discovering that raw size isn't the only way to intelligence. In many real-world scenarios, a lean, highly-optimized model can actually outperform a giant that costs ten times as much to run.
The secret isn't just "training harder," but training smarter. By focusing on high-quality, curated data and architectural refinements, Small Language Models (or SLMs) are proving that efficiency often beats scale. An SLM is generally defined as an AI system with fewer than 10 billion parameters. While they lack the broad, encyclopedic knowledge of a frontier model, they are becoming lethal specialists in fields like coding and technical reasoning.
The Death of the "Bigger is Better" Myth
The traditional Scaling Laws are empirical observations that suggest model performance improves predictably as you increase compute, data, and parameter count . While true for general intelligence, these laws hit a wall of diminishing returns when you apply them to specific tasks. Why use a massive model that knows everything about 18th-century poetry to write a Python function when a tiny model trained exclusively on high-quality code can do it faster and more accurately?
Take Microsoft Phi-2 as an example. With only 2.7 billion parameters, this model achieves reasoning and coding performance that rivals models with 30 billion parameters. It didn't get there by accident; it was built using "textbook-quality" data-carefully curated information that teaches the model how to think rather than just how to predict the next word in a random web crawl.
Where Small Models Actually Win
If you're building a production application, you care about three things: speed, cost, and reliability. This is where scaling laws are flipped on their head. Large models are slow and expensive, often requiring multi-GPU enterprise clusters to run. SLMs, however, can fit on a single high-end consumer GPU, like an RTX 4090, making them accessible for local deployment.
In the world of software development, the difference is stark. GPT-4o mini can process code at roughly 49.7 tokens per second. For a developer, this means real-time suggestions that don't break their flow. When a model responds in 200ms instead of 2 seconds, it feels like a tool; when it takes 2 seconds, it feels like a hurdle.
| Feature | Small Language Models (SLMs) | Large Language Models (LLMs) |
|---|---|---|
| Avg. Inference Latency | 200-500ms | 500ms - 2s+ (Cloud dependent) |
| Hardware Req. | 16GB+ GPU (Consumer Grade) | Multi-GPU Enterprise Clusters |
| Operational Cost | Low (~$2M for scale) | Extreme ($50M - $100M+) |
| Training Time (Fine-tuning) | ~7.2 hours (Single A100) | ~83.5 hours (Distributed) |
| Carbon Footprint | 60-70% Lower | High |
The Trade-offs: What You Give Up
It’s not all sunshine and rainbows. If you swap a giant for a dwarf, you're trading breadth for depth. SLMs typically struggle with multi-turn conversations that exceed a few thousand tokens because their context windows are smaller (often 2K-4K tokens compared to the million-token windows seen in some LLMs).
They also fail more often on "edge cases." A larger model has a broader world-view, allowing it to handle weird, unexpected prompts through sheer associative power. An SLM is more likely to hallucinate or fail when pushed outside its specific domain. For example, a fintech startup recently found that while an SLM was great for basic tasks, it had an 18.7% higher false negative rate in complex fraud detection compared to a larger model. If your task requires deep, creative synthesis or complex multi-step reasoning, the big models are still the kings.
The Rise of the Specialists
We are seeing a surge in "specialist" models. Google Gemma 2 and Meta Llama 3.1 8B are prime examples. These aren't trying to be everything to everyone. They are designed to be the engine inside another app. Because they are smaller, they are far easier to fine-tune. An enterprise can take a Llama 8B model and train it on their own internal documentation in a few days, creating a private, secure AI that knows their business better than a general GPT model ever could.
This is especially critical for industries like healthcare. Running a model on-premises to maintain HIPAA compliance is nearly impossible with a trillion-parameter model, but a 7B parameter model fits comfortably in a secure local server. This shift toward privacy and local control is driving a massive spike in SLM adoption, with nearly 80% of Fortune 500 companies now using them for internal tools.
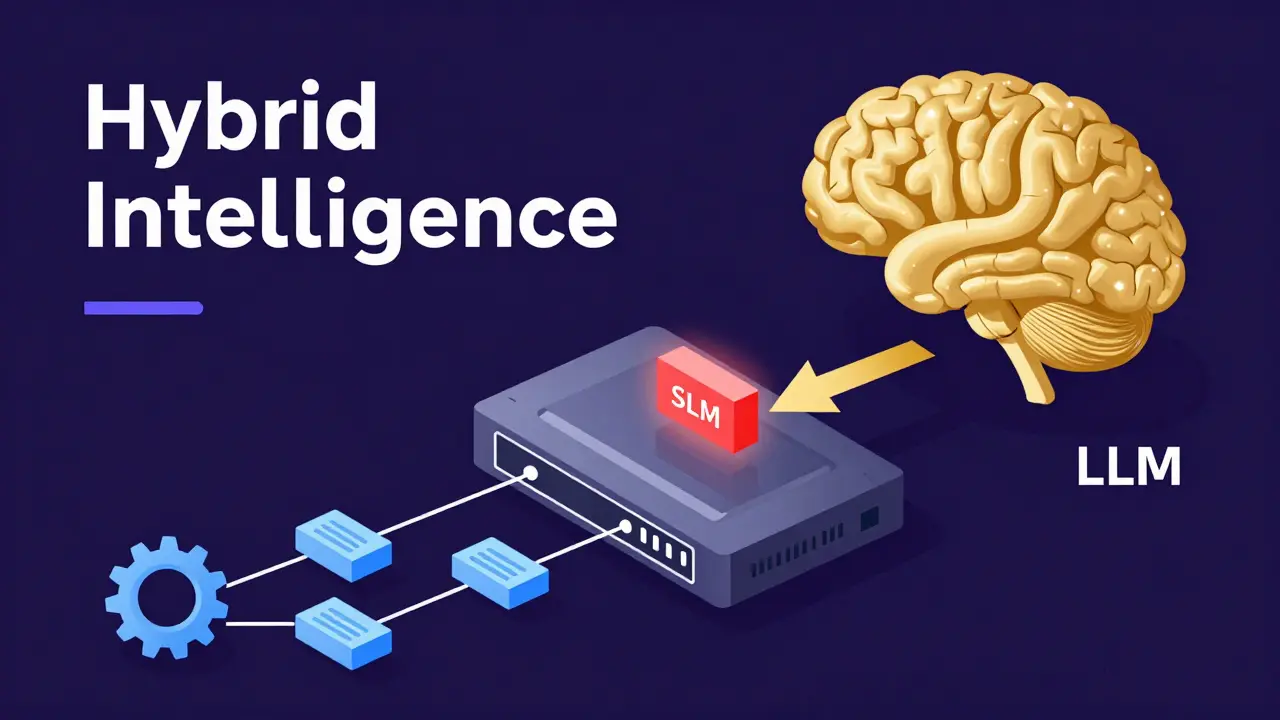
The Future: Hybrid Intelligence
The most likely future isn't a world with only small or only large models. It's a hybrid approach. Imagine an AI system where a tiny, lightning-fast SLM handles 90% of the requests-like formatting text, basic coding, or answering FAQs. If the SLM detects that a query is too complex, it "escalates" the task to a massive LLM in the cloud.
This "router" architecture gives you the best of both worlds: the speed and cost-efficiency of a small model with the raw power of a giant as a safety net. We're already seeing this in about 38% of enterprise AI deployments. It turns the AI from a single, expensive brain into a tiered system of intelligence.
What exactly is a Small Language Model (SLM)?
An SLM is an AI model typically featuring fewer than 10 billion parameters. Unlike general LLMs, they are often optimized for specific tasks through high-quality data curation and architectural tweaks, allowing them to perform complex tasks (like coding) with a fraction of the compute power.
Can an SLM really be as smart as a huge model?
In specific domains, yes. For instance, Microsoft's Phi-2 (2.7B) has shown reasoning and coding abilities comparable to models 10 times its size. However, they lack the broad general knowledge and creative flexibility of giant models.
Why are SLMs better for privacy?
Because they require significantly less memory (often 16GB-24GB VRAM), they can be run locally on a company's own hardware. This means sensitive data never leaves the building, making them ideal for HIPAA or GDPR-compliant environments.
What are the main downsides of using smaller models?
The primary trade-offs are a smaller context window (limiting how much text they can "remember" in one go) and a higher likelihood of failure on very complex, multi-step reasoning tasks or niche edge cases.
Which hardware do I need to run an SLM?
Most SLMs between 1B and 8B parameters can run on high-end consumer GPUs, such as the NVIDIA RTX 3090 or 4090. Some even run on high-end laptops with sufficient unified memory (like Apple's M-series chips).