Chain-of-Thought in Vibe Coding: Why Explanations Before Code Make AI Assistants Smarter
 Mar, 20 2026
Mar, 20 2026
Ever typed a simple coding question into your AI assistant and got back code that looked perfect - until it crashed on the first test? You’re not alone. Many developers have been burned by AI-generated code that seems right but hides a logic flaw. The secret to fixing this isn’t more powerful models. It’s asking the AI to explain before it codes.
Chain-of-Thought (CoT) prompting isn’t just a buzzword. It’s the difference between getting a working solution and getting a solution you can actually trust. Since its introduction in January 2022 by Google Research, CoT has become the default way top AI coding tools like GitHub Copilot, Claude 3, and GPT-4.5 handle complex tasks. And here’s the catch: it works because it forces the model to slow down, think out loud, and walk through each step - just like a senior engineer would.
How Chain-of-Thought Changes the Game in Coding
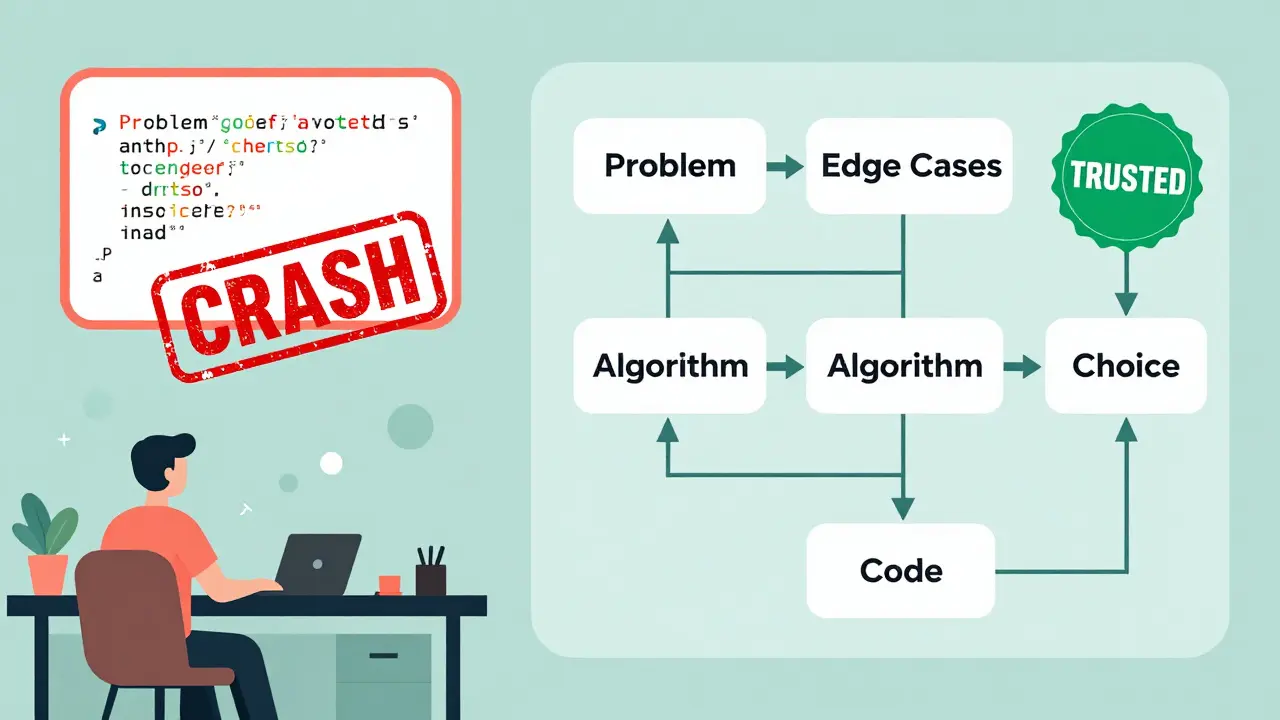
Standard prompting asks: "Write a function to sort a list of user IDs by last login date." The AI responds with code - fast, but often flawed. CoT prompting asks: "Think step by step: How would you approach sorting user IDs by last login date? What edge cases might break this? What’s the most efficient algorithm here? Then write the code."
The difference? Google Research found that with CoT, models improved accuracy on math-based coding problems from 18% to 79%. That’s not a tweak - that’s a revolution. Why? Because the model doesn’t just guess the answer. It builds a reasoning path.
Three things happen during CoT prompting:
- Problem decomposition: The AI breaks the task into smaller, manageable pieces. Instead of "sort by date," it thinks: "First, extract the login timestamps. Then, compare them. Then, reorder."
- Sequential reasoning: Each step is explained logically. "I’ll use merge sort because it’s stable and O(n log n), which handles large lists better than quicksort when we need to preserve order."
- Error prevention: The AI anticipates failures. "What if a user has no login date? I’ll handle nulls by placing them at the end."
This isn’t magic. It’s structure. And it turns guesswork into a repeatable process.
Why This Matters More Than You Think
Most developers don’t realize how much time they waste debugging AI-generated code. DataCamp’s study of 1,200 GitHub repositories showed that developers using CoT reduced logical errors by 63% compared to direct code generation. That’s not just fewer bugs - it’s fewer code reviews, fewer late-night fixes, and less stress.
And it’s not just juniors who benefit. Senior engineers at GitHub reported cutting their AI-assisted error rate from 34% down to 12% after just six weeks of using CoT prompts consistently. Why? Because they stopped treating AI as a code machine and started treating it like a junior teammate who needs guidance.
But here’s the twist: CoT doesn’t work on every task. GeeksforGeeks’ 2024 tests showed a 22% performance drop on simple CRUD operations. If you’re just generating a login form or a basic API endpoint, CoT adds unnecessary overhead. Token usage jumps from 150 to 420 per request. That’s expensive at scale. G2’s 2024 survey found 32% of developers complained about slower responses and higher costs.
So when should you use it? Stick to complex logic: graph algorithms, dynamic programming, system design, or anything involving conditional branching, edge cases, or multi-step logic. That’s where CoT shines.
What the Experts Say
Judgment matters. Jason Wei, co-author of the original CoT paper, put it bluntly: "Chain-of-thought prompting enables language models to solve problems that are orders of magnitude more complex than what they could handle with standard prompting."
Andrew Karpathy, former AI director at Tesla, called it "the single most effective prompt engineering technique for complex software tasks." His Twitter thread on the topic hit 1.2 million impressions - not because it was flashy, but because it was true.
Even critics acknowledge its power. Dr. Emily M. Bender from the University of Washington warned that CoT can create "false confidence." She found that 18% of CoT-generated explanations had logical fallacies - steps that sounded right but led to wrong code. The model might say, "I’ll use recursion because it’s elegant," when iteration is safer. The code still works, but the reasoning is flawed. That’s dangerous for long-term maintenance.
That’s why human oversight isn’t optional. CoT gives you better reasoning - not perfect reasoning. Always read the explanation. Ask: "Does this make sense? Could this break under load? What’s the fallback?"
How to Use CoT in Your Daily Workflow
You don’t need to be a prompt engineer to use this. Here’s the practical formula most top developers follow:
- Restate the problem: "Before I write code, let me make sure I understand the goal. You want to sort user IDs by last login date, and if there’s no login date, put them at the end. Correct?"
- Justify the approach: "Why merge sort over quicksort? Because stability matters - if two users have the same login time, we want to preserve their original order."
- Call out edge cases: "What if the input is empty? What if the date format is inconsistent? What if we’re dealing with 10 million records?"
GitHub’s internal training program found that developers who used this three-step method reduced errors by 65% within six weeks. It’s not about fancy wording. It’s about consistency.
Templates help. The "Chain-of-Thought Coding" GitHub repo (14,500 stars) has been downloaded over 87,000 times. It includes ready-to-use prompts for common scenarios: sorting, searching, validation, recursion, and concurrency. Copy. Adapt. Use.
Where It’s Being Adopted - And Why
CoT isn’t just a personal trick. It’s now baked into the tools you use.
- GitHub Copilot, Claude 3, and GPT-4.5 all apply CoT principles automatically when the task is complex.
- Google’s CodeT5+ model (May 2024) cut logical errors by 52% using specialized CoT training.
- Auto-CoT, a new technique from March 2023, now lets models generate their own reasoning steps without you even asking - and GitHub’s tests showed a 28% improvement on novel problems.
- JetBrains announced native CoT support in its 2025 IDE lineup. You’ll soon see "Explain this code" buttons next to "Generate code."
Adoption is highest where mistakes cost money: financial services (94% adoption), healthcare IT (89%), and autonomous systems (92%). These aren’t hobbyists. They’re teams who can’t afford bugs.
Meanwhile, individual developers are slower to adopt - only 63% use it regularly. But those who do? They’re the ones getting promoted. Why? Because they ship code that works - the first time.

The Future: Explanation-First Coding
By 2026, Gartner predicts "explanation-first coding" will be the dominant paradigm. That means AI won’t just generate code - it’ll generate a reasoning log alongside it. You’ll review the logic before approving the output.
This isn’t science fiction. It’s already happening in enterprise tools. The shift is from "give me code" to "help me think through this."
And that’s the real win. You’re not outsourcing your brain. You’re upgrading it.
What to Avoid
CoT isn’t a cure-all. Here’s what to skip:
- Don’t use it for boilerplate. No need to explain how to write a GET endpoint.
- Don’t ignore the explanation. If the AI says, "I’ll use a hash map because it’s fast," but doesn’t say why it’s better than a binary search tree, dig deeper.
- Don’t assume correctness. Just because the steps sound logical doesn’t mean they are. Always test.
And remember: CoT increases token usage. If you’re running 1,000 prompts a day, your bill could double. Use it strategically - on the hard problems, not the easy ones.
What exactly is Chain-of-Thought prompting in coding?
Chain-of-Thought (CoT) prompting is a technique where you ask an AI model to explain its reasoning step by step before generating code. Instead of just outputting a solution, it walks through the logic - breaking down the problem, justifying its approach, and identifying edge cases. This was first proven effective in a January 2022 Google Research paper, which showed accuracy improvements from 18% to 79% on complex coding tasks. It’s now a standard feature in tools like GitHub Copilot and Claude 3.
Does Chain-of-Thought work with all AI coding tools?
Most major tools now support it, but effectiveness depends on model size. CoT works best with models over 100 billion parameters - like GPT-4, Claude 3, and Llama 3. Smaller models don’t benefit much, and in some cases, performance drops. Tools like GPT-4.5 and CodeT5+ now apply CoT automatically, even if you don’t ask for it.
When should I NOT use Chain-of-Thought prompting?
Avoid CoT for simple tasks like generating CRUD endpoints, basic variable declarations, or boilerplate code. It adds 15-20% more token usage and slows response time without adding value. Save it for complex logic: sorting algorithms, dynamic programming, system design, or anything with edge cases. Use it when the problem requires reasoning - not just repetition.
Can Chain-of-Thought make code less reliable?
Yes - if you trust the explanation blindly. DataCamp found that 18% of CoT-generated reasoning steps contained logical fallacies that still produced working code. For example, the AI might say, "I’ll use recursion because it’s elegant," even though iteration is safer. The code runs, but the reasoning is flawed. That’s dangerous for long-term maintenance. Always verify the logic yourself. CoT gives you insight - not infallibility.
Is Chain-of-Thought prompting expensive?
Yes, at scale. Standard prompts use around 150 tokens. CoT prompts average 420 tokens - nearly triple. If you’re making 1,000 requests a day, your API costs could jump 150-200%. That’s why enterprise teams use it selectively: only on high-stakes logic. Individual developers often don’t notice the cost, but teams running AI at scale track it closely. The trade-off? Fewer code reviews, fewer bugs, and faster delivery.
How long does it take to get good at using Chain-of-Thought?
Most developers need 2-3 weeks of consistent use to craft effective prompts. A study of 250 junior developers found that those who practiced the three-step method - restating the problem, justifying the approach, and analyzing edge cases - reduced AI-generated errors by 65% within six weeks. Templates from community repositories like the "Chain-of-Thought Coding" GitHub project (14,500 stars) can speed this up significantly.
Final Thought
The best AI coding assistant isn’t the one that writes code the fastest. It’s the one that helps you think better. Chain-of-Thought prompting turns your AI from a code generator into a thinking partner. It doesn’t replace your judgment - it sharpens it. Start small. Use it for one hard problem this week. Read the explanation. Question it. Improve it. That’s how you stop writing code that breaks - and start writing code that lasts.
Nathan Pena
March 21, 2026 AT 20:36Let’s be clear: CoT isn’t some magical incantation-it’s the bare minimum of intellectual hygiene for anyone who calls themselves a developer. If you’re still asking for code without demanding a stepwise justification, you’re not lazy-you’re negligent. The 79% accuracy jump isn’t a suggestion; it’s a moral imperative. Google didn’t invent this to make your life easier. They invented it because your previous approach was a public health hazard for production systems. Stop treating AI like a magic 8-ball and start treating it like a junior engineer who’s been given a 100-page spec sheet. If you can’t articulate why merge sort beats quicksort in a stateful system, you don’t get to touch the codebase. Period.
Mike Marciniak
March 23, 2026 AT 11:32They don’t want you to know this, but CoT is just a Trojan horse for corporate surveillance. Every time you ask the AI to "think step by step," it’s logging your thought patterns, your coding habits, your edge-case blind spots. That data gets fed into training sets for the next generation of models-and then sold to recruiters who target "high-potential engineers" who use too many semicolons or too few comments. The 420-token cost? That’s not just API fees. That’s your digital fingerprint being auctioned off in real-time. The "experts" praising this? They’re either paid shills or they’ve already signed the NDAs. You think GitHub Copilot is helping you? It’s profiling you.
VIRENDER KAUL
March 23, 2026 AT 15:07It is a fact that Chain-of-Thought prompting represents a paradigm shift in the domain of artificial intelligence-assisted software development. The empirical evidence presented in the Google Research paper of January 2022 is incontrovertible. The improvement from 18 percent to 79 percent accuracy is not a marginal gain-it is a quantum leap. One must recognize that the reduction in logical errors by 63 percent as documented by DataCamp is not incidental but systemic. Furthermore, the adoption rate among financial services at 94 percent and healthcare IT at 89 percent indicates institutional validation. The resistance observed among individual developers is not a critique of methodology but a symptom of cognitive inertia. One must adopt CoT not as an option but as a professional obligation. Failure to do so constitutes a dereliction of duty in modern software engineering.
Mbuyiselwa Cindi
March 24, 2026 AT 21:32I’ve been using CoT for about three months now and it’s been a game-changer. I used to get so frustrated when my AI-generated code would break on edge cases I didn’t even think about. Now I ask it to walk me through the logic first-and honestly? I’ve learned more from the AI’s reasoning than from half the code reviews I’ve done. I even started sharing the templates with my team. We’re not all experts, but we’re all trying. And if you’re worried about cost? Start small. Try it on one complex function this week. Read the explanation. If it makes sense, keep it. If it’s weird? Tweak it. No one’s expecting perfection. Just consistency. You’ve got this.
Krzysztof Lasocki
March 25, 2026 AT 22:39