How to Avoid LLM Vendor Lock-In: A Practical Migration Guide
 May, 21 2026
May, 21 2026
Imagine your entire customer support system freezes because a major AI provider raises prices or suffers an outage. You can't switch models overnight because your code is hard-coded to one specific API. This isn't a hypothetical nightmare; it's the reality of vendor lock-in for many companies today. In 2026, relying on a single Large Language Model (LLM) provider like OpenAI is no longer just a technical choice-it’s a strategic vulnerability. The industry has shifted from treating AI as a rented utility to building portable, sovereign infrastructure.
The good news? You don’t need to become a hardware giant to fix this. By adopting a model-agnostic architecture and moving incrementally toward self-hosting, you can retain control over costs, data privacy, and uptime. Here is how to navigate the transition without breaking your application.
The Cost of Dependence: Why "Token Tax" Hurts
When you start using an LLM API, it feels cheap and easy. But as usage scales, so does the bill. Industry analysts now refer to this escalating cost structure as the "Token Tax." Unlike traditional software where licensing fees are often flat or predictable, API costs scale linearly with every word processed. For high-volume applications, these costs can quickly exceed the price of running your own hardware.
Beyond money, there is the risk of data exposure. Sending sensitive customer documents to external endpoints creates compliance headaches, especially with regulations like the EU Cloud and AI Development Act (2026). If your provider changes their terms or pricing roadmap, you have zero leverage. True independence requires moving away from pure API dependency toward a hybrid or fully self-hosted model.
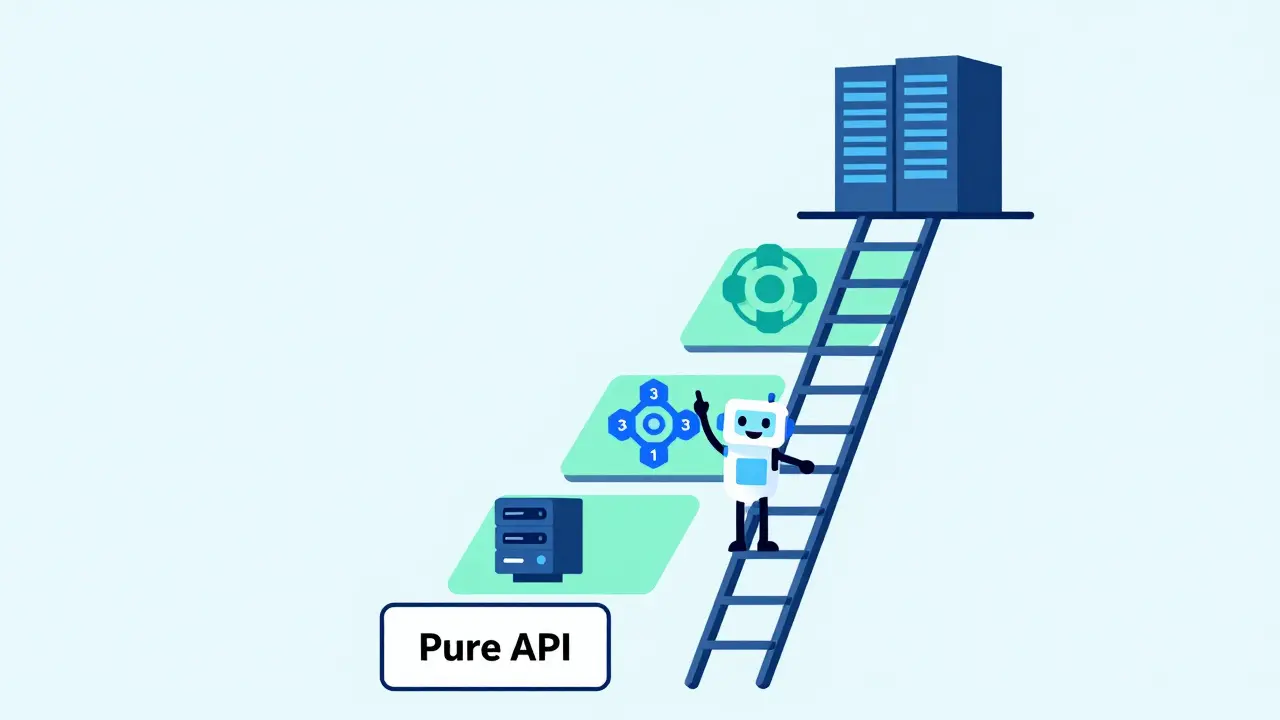
The Five Classes of LLM Sovereignty
Migrating isn't a binary jump from "cloud" to "on-premise." It’s a spectrum. Understanding where you sit helps you plan your next move. Think of these classes as rungs on a ladder:
- Class 1 (Pure API): Full dependency. You send data out, get text back. Zero control.
- Class 2 (Fine-Tuning via API): You customize a proprietary model, but still rely on the provider’s infrastructure.
- Class 3 (Managed Open Source): You use open-source models (like Llama or Mistral) through managed endpoints. Better portability, but still dependent on a host.
- Class 4 (Managed Kubernetes/Serverless): You deploy open-source models on scalable cloud infrastructure (like AWS EKS or Lambda Labs). You control the model version and routing.
- Class 5 (Self-Hosted): Complete ownership. Your GPUs, your drivers, your data. Maximum control, maximum operational responsibility.
Most successful migrations start at Class 3 to validate performance, move to Class 4 when volume justifies dedicated infrastructure, and graduate to Class 5 only when internal expertise and economics align. Don’t try to jump straight to Class 5 unless you already have a mature MLOps team.
The Secret Weapon: Model-Agnostic Proxies
The biggest mistake teams make is hard-coding API calls into their business logic. Instead, implement a model-agnostic proxy layer. This sits between your application and the LLM providers. To your app, it looks like one standard interface. Behind the scenes, the proxy decides which model handles the request.
With this setup, switching from Llama 3.1 to Mistral Large 2 involves changing a single configuration file (config.yaml), not rewriting thousands of lines of code. You can even set up intelligent routing: send simple summarization tasks to a fast, local Small Language Model (SLM) like Phi-4, while routing complex reasoning queries to a powerful frontier model like Claude 3.5 Sonnet. This reduces costs and improves latency simultaneously.
| Class | Control Level | Operational Effort | Best For |
|---|---|---|---|
| Class 1 | None | Low | Prototypes, low volume |
| Class 3 | Medium | Medium | Validating open-source models |
| Class 4 | High | High | Scaling with flexibility |
| Class 5 | Total | Very High | Enterprise sovereignty, strict compliance |
Infrastructure Options: Serverless vs. Managed Kubernetes
Once you decide to move beyond pure APIs, you face a choice in infrastructure. Do you want the flexibility of serverless or the stability of managed clusters?
Serverless GPU Clusters (from providers like RunPod, CoreWeave, or Lambda Labs) are ideal if you want to avoid long-term hardware commitments. They automatically scale during peak inference windows and shut down when idle, saving money. However, you still depend on their availability.
Managed Kubernetes (such as Amazon EKS with NVIDIA H100 instances) offers industrial-grade reliability. Your AI infrastructure stays within your corporate Virtual Private Cloud (VPC), behind your firewall. This is crucial for enterprises requiring strict security and consistent performance. While the setup is more complex, it provides the foundation for true multi-provider orchestration.
Data Migration: The Hidden Bottleneck
Many teams migrate their inference engine but forget about their data. If you’re using a managed vector database like Pinecone, you’re still sending embeddings out. To achieve full sovereignty, you must migrate both your knowledge base and your embedding process.
Switch to self-hosted vector engines like Milvus or Qdrant. Pair this with local embedding models such as BGE-M3. This ensures that the semantic mapping of your proprietary knowledge never leaves your network. It prevents the common pitfall where an organization thinks it’s independent, but its data pipeline remains tethered to a third-party service.
Latency and Performance Gains
One surprising benefit of self-hosting is speed. Cloud APIs introduce network overhead and queuing delays. By deploying specialized Small Language Models (SLMs) on local hardware, enterprises can achieve sub-200ms response times. This enables real-time features like fluid voice AI or instant autocomplete that feel native to the user. For applications where every millisecond counts, eliminating the round-trip to a distant data center is a game-changer.
Risks of Going Fully Self-Hosted
Don’t romanticize Class 5 deployments. With great power comes great responsibility. When you self-host, security risks shift from the provider to your team. Misconfigured firewalls or outdated NVIDIA drivers can expose vulnerabilities. Staff turnover becomes an existential threat-if your lead ML engineer leaves, who maintains the cluster? Hardware aging is also faster than expected; GPUs and drivers require continuous upgrades to maintain performance and security patches. These operational challenges are why incremental migration is critical. Build your expertise at Class 4 before committing to full ownership.
Regulatory Drivers and Future-Proofing
In 2026, regulation is pushing companies toward flexibility. The EU Cloud and AI Development Act imposes compliance requirements that may conflict with single-provider lock-in. Building a model-agnostic architecture allows you to move workloads between private clusters and public clouds as laws change. Major players like AWS are already adopting multi-model strategies, signaling that flexibility is becoming the industry standard, not an optional optimization.
Is it worth migrating from OpenAI to open-source models?
Yes, if you are facing high token costs, strict data privacy requirements, or latency issues. Open-source models like Llama 3.1 or Mistral offer comparable performance for many tasks at a fraction of the long-term cost, provided you have the infrastructure to host them efficiently.
What is a model-agnostic proxy?
It is a middleware layer that abstracts the underlying LLM provider from your application code. This allows you to switch between different models (e.g., from Claude to Llama) by changing configuration settings rather than rewriting code, preventing vendor lock-in.
Do I need to self-host everything to avoid lock-in?
No. You can reduce lock-in by using managed services for open-source models (Class 3 or 4) combined with a multi-provider strategy. Full self-hosting (Class 5) is only necessary for organizations with extreme security needs or massive scale where API costs are prohibitive.
How do I handle data migration for RAG applications?
You must migrate both your vector database and your embedding models. Move from managed services like Pinecone to self-hosted solutions like Milvus or Qdrant, and replace cloud-based embedding APIs with local models like BGE-M3 to ensure your data never leaves your secure environment.
What are the operational risks of self-hosting LLMs?
Key risks include security misconfigurations, staff turnover affecting maintenance capabilities, and rapid hardware/driver aging. Self-hosting requires a dedicated MLOps team to manage updates, scaling, and security patches, unlike API services where the provider handles these tasks.