LLMs vs Task-Specific NLP: Why Scale and Versatility Win (and Where They Don't)
 Apr, 6 2026
Apr, 6 2026
For years, if you wanted a computer to understand sentiment or pull names out of a legal document, you had to build a dedicated tool for that one specific job. You'd gather a few thousand labeled examples, spend weeks on feature engineering, and train a model that did exactly one thing very well. Then came the era of Large Language Models, and suddenly, one single model could write poetry, debug code, and summarize a 50-page report without being told exactly how to do any of it. But does "bigger" always mean "better"?
The shift from task-specific systems to LLMs isn't just a bump in speed; it's a total change in how machines "understand" us. To see why LLMs often crush traditional systems, we have to look at the engine under the hood and the sheer amount of data they've devoured.
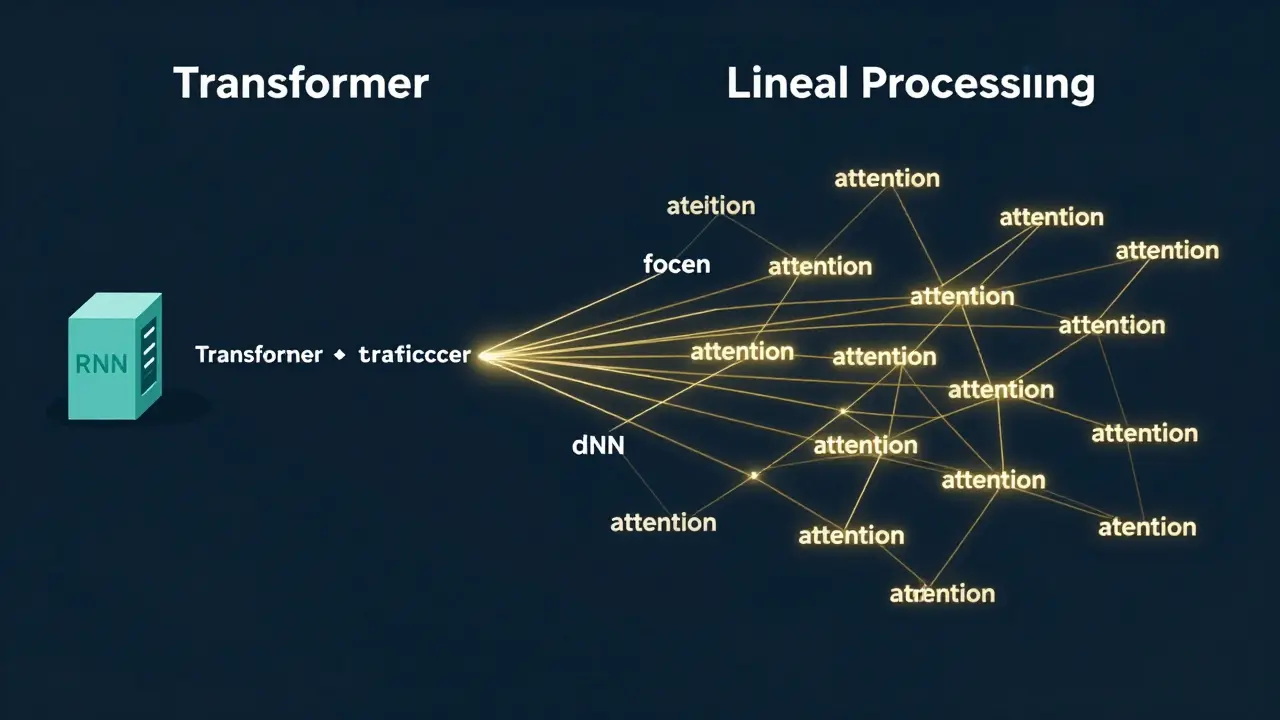
The Engine: Transformers vs. Old School NLP
Traditional NLP relied on things like Recurrent Neural Networks (RNNs)a class of neural networks where connections between nodes form a directed graph along a sequence or simpler statistical models. These systems processed text linearly-one word at a time. The problem? By the time the model reached the end of a long sentence, it often "forgot" how the sentence started. It struggled with nuance and long-distance relationships between words.
Enter the Transformera deep learning architecture that uses self-attention mechanisms to weight the significance of different parts of the input data. Unlike its predecessors, a Transformer looks at the entire block of text simultaneously. It uses an attention mechanism to decide which words are most important to the meaning of others, regardless of how far apart they are in a paragraph. This allows Generative Pre-trained Transformers (GPT) to grasp complex context and sarcasm in a way that a rule-based system simply can't.
The Data Gap: Web-Scale vs. Curated Sets
A task-specific model is like a student who memorizes one specific textbook. If the test is based exactly on that book, they get an A+. But if you ask them a question from a different subject, they're lost. These models are trained on small, curated datasets-maybe a few hundred thousand parameters-focused on one goal, like classifying emails as spam.
LLMs, on the other hand, are trained on nearly the entire public internet. We're talking trillions of parameters and hundreds of gigabytes of unstructured text. Because they've seen everything from Reddit threads and scientific papers to Python scripts and classic literature, they develop a general-purpose understanding of language. They don't just learn that "bad" usually means negative sentiment; they learn how sentiment shifts across different cultures, eras, and professional contexts.
Zero-Shot Learning: The End of Constant Retraining
One of the biggest headaches with old NLP systems was the need for explicit rules and massive amounts of labeled data for every new task. If you wanted to move from sentiment analysis to named entity recognition, you basically had to start over from scratch.
LLMs introduced the world to Zero-Shot Learningthe ability of a model to complete a task without having seen any specific examples of that task during training. Because they've learned the underlying patterns of language, you can simply tell an LLM, "Translate this to French," and it does it. No specific "translation training" required. This versatility significantly cuts down development time. You no longer need a team of data scientists to label 10,000 sentences just to get a basic classifier working.
| Feature | Task-Specific NLP | Large Language Models (LLMs) |
|---|---|---|
| Training Data | Small, curated, labeled | Web-scale, unstructured, diverse |
| Adaptability | Low (requires retraining) | High (Zero-shot / Few-shot) |
| Computational Cost | Low (runs on basic hardware) | High (requires GPUs/TPUs) |
| Context Window | Short/Limited | Very Long/Expansive |
| Deployment | Fast and cheap | Resource-intensive |
Where the Big Models Fail: The Specialization Paradox
It sounds like LLMs have won the war, but that's not actually the case. There's a "specialization paradox": sometimes, a tiny, focused model can outperform a giant, general one. This happens because generic LLMs can be "distracted" by the vast amount of noise in their training data, whereas a specialized model is laser-focused on a specific domain.
Take a 2025 study on mental health classification. Researchers compared a prompt-engineered LLM, a fine-tuned LLM, and a traditional NLP model with heavy feature engineering. The results were surprising: the traditional NLP model hit 95% accuracy, while the prompt-engineered LLM only managed 65% and the fine-tuned version hit 91%. In a high-stakes field like medicine, that 4% gap is huge. When you have a very narrow definition of success and a specific set of domain rules, the "brute force" approach of an LLM isn't always the most accurate.

The Practical Trade-off: Speed, Cost, and Hardware
If you're running a startup on a budget, you can't ignore the operational costs. Running an LLM requires massive compute power-expensive GPUs or TPUs-and can lead to high latency (the time it takes to get an answer). For a simple task like extracting keywords from a news article, using a giant model is like using a sledgehammer to crack a nut.
Traditional models are lightweight. They can be deployed on a cheap server or even locally on a device without an internet connection. They provide faster response times and are far more interpretable. If a traditional model makes a mistake, you can often trace exactly which rule or feature caused the error. With LLMs, you're often dealing with a "black box" where it's hard to explain why the model hallucinated a fact.
Choosing Your Weapon: How to Decide
So, which one should you use? It comes down to the complexity of your goal. If you need a system that can handle open-ended conversations, summarize diverse documents, or support 50 different languages without extra setup, an LLM is your only real choice. Their multilingual capabilities and general reasoning make them indispensable for modern AI assistants.
However, if you are working in a specialized field-like medical coding or legal compliance-where accuracy is non-negotiable and the output must follow strict rules, don't dismiss the old school. A traditional NLP pipeline with domain-specific feature engineering can be more accurate, cheaper to run, and easier to maintain.
Do LLMs always require more data than traditional models?
In terms of total training, yes. LLMs are trained on trillions of words. However, for a specific *new* task, LLMs actually require *less* data. Through zero-shot or few-shot learning, an LLM can perform a task with zero or just a few examples, whereas a traditional model would need thousands of labeled examples to achieve the same result.
What is "feature engineering" in traditional NLP?
Feature engineering is the process of manually identifying and creating specific indicators that help a model understand text. For example, in a sentiment analysis tool, a developer might create a list of "positive" and "negative" words or write rules to handle negation (like "not bad"). LLMs replace this manual work by automatically learning these features from their massive datasets.
Why are LLMs better at multilingual tasks?
Traditional models are usually built for one language at a time. To support Spanish and English, you'd often need two separate models. LLMs are trained on multilingual datasets, allowing them to learn the common structures across languages. This enables them to translate or reason in multiple languages using a single shared set of weights.
Can you combine both approaches?
Absolutely. Many modern systems use a hybrid approach. They might use a traditional NLP model for fast, high-accuracy entity extraction and then pass those entities into an LLM to generate a nuanced, human-like summary based on that data. This balances the efficiency of specific tools with the creativity of general models.
Are LLMs more expensive to maintain?
Generally, yes. While you spend less time on initial labeling and rule creation, the ongoing costs for API calls or hosting the massive GPU clusters required to run LLMs are significantly higher than the cost of running a small, specialized statistical model.
sonny dirgantara
April 7, 2026 AT 16:27this is cool but i think most peopel just use chatgpt for everything anyway lol
Jawaharlal Thota
April 8, 2026 AT 04:18It is truly heartening to see such a comprehensive breakdown of these technologies, and I believe that for those of us entering the field, understanding that the synergy between specialized models and general LLMs is where the real magic happens will help us grow into more versatile engineers who can tackle any problem regardless of the scale!
Johnathan Rhyne
April 9, 2026 AT 23:16Imagine thinking the "black box" nature of LLMs is a dealbreaker when most human intuition is just a messy black box of biological spaghetti code. Also, a minor quibble: the phrasing in the second paragraph is slightly clunky, but I'll let it slide because the overall vibe is pleasantly zesty. Just a bit of spicy chaos in the architecture!
Lauren Saunders
April 10, 2026 AT 18:20The obsession with "scale" is so pedestrian. Anyone with a modicum of intellectual curiosity knows that the real triumph isn't in the number of parameters, but in the elegant failure of the system to actually mimic human cognition. The dichotomy presented here is almost too simplistic for a serious discourse on linguistic computation.
Andrew Nashaat
April 12, 2026 AT 07:01The technical inaccuracies regarding RNNs are simply appalling!!! It is practically a sin to overlook the nuanced degradation of gradients in such a pivotal discussion!!! We must strive for absolute precision in our terminology, or we are merely shouting into a void of ignorance!!!
Sandy Pan
April 14, 2026 AT 02:50We are witnessing the death of the artisan's touch in linguistics. There is something profoundly tragic about replacing the meticulous, handcrafted rules of traditional NLP with a statistical behemoth that guesses the next token based on a trillion whispers of the internet. It is a shift from understanding to mere simulation, a ghostly echo of meaning that haunts the machine.
Gina Grub
April 14, 2026 AT 02:52absolute disaster of a comparison if you actually care about inference latency and token cost. the stochastics of these models are a nightmare for production pipelines. we are basically just gambling with hallucination rates and calling it innovation while the technical debt piles up into a mountain of GPU clusters. total joke
Nathan Jimerson
April 14, 2026 AT 19:33It is great to see that there is still a place for the old school methods. This gives a lot of hope to developers who want to build efficient, lightweight apps without needing a massive budget. The hybrid approach mentioned at the end is definitely the way forward for everyone.