Scaled Dot-Product Attention Explained for Large Language Model Practitioners
 Mar, 16 2026
Mar, 16 2026
Ever wonder why your LLM doesn’t collapse into a single-word prediction after a few training steps? The answer isn’t in the number of layers or the size of the model-it’s in a tiny mathematical trick called scaled dot-product attention. This isn’t just another layer in a transformer. It’s the reason modern language models like GPT-3, BERT, and Claude 3 can handle long texts, remember context, and generate coherent responses without falling apart. And if you’ve ever tried implementing attention from scratch and seen your loss explode or your gradients vanish, you’ve probably been missing this one scaling factor: 1/√(d_k).
What Exactly Is Scaled Dot-Product Attention?
Scaled dot-product attention is the core mechanism that lets each word in a sequence pay attention to every other word-simultaneously. Unlike older RNNs that process words one after another, this mechanism works in parallel. That’s why transformers train faster and scale better.
The math looks simple:
Attention(Q, K, V) = softmax(QKT / √(dk)) V
Here’s what each part means:
- Q (Queries): What each token is asking for. Think of it as: “What information do I need from other words?”
- K (Keys): What each token offers. Think: “Here’s what I represent.”
- V (Values): The actual content each token carries.
- dk: The dimension of the key (and query) vectors. In early Transformers, this was 64. In GPT-3, it’s 128. In larger models, it can go higher.
The dot product QKT measures how similar each query is to each key. High similarity = high attention weight. But here’s the catch: if you just use the raw dot product, things go wrong fast.
Why Scaling Isn’t Optional-It’s Mathematical Necessity
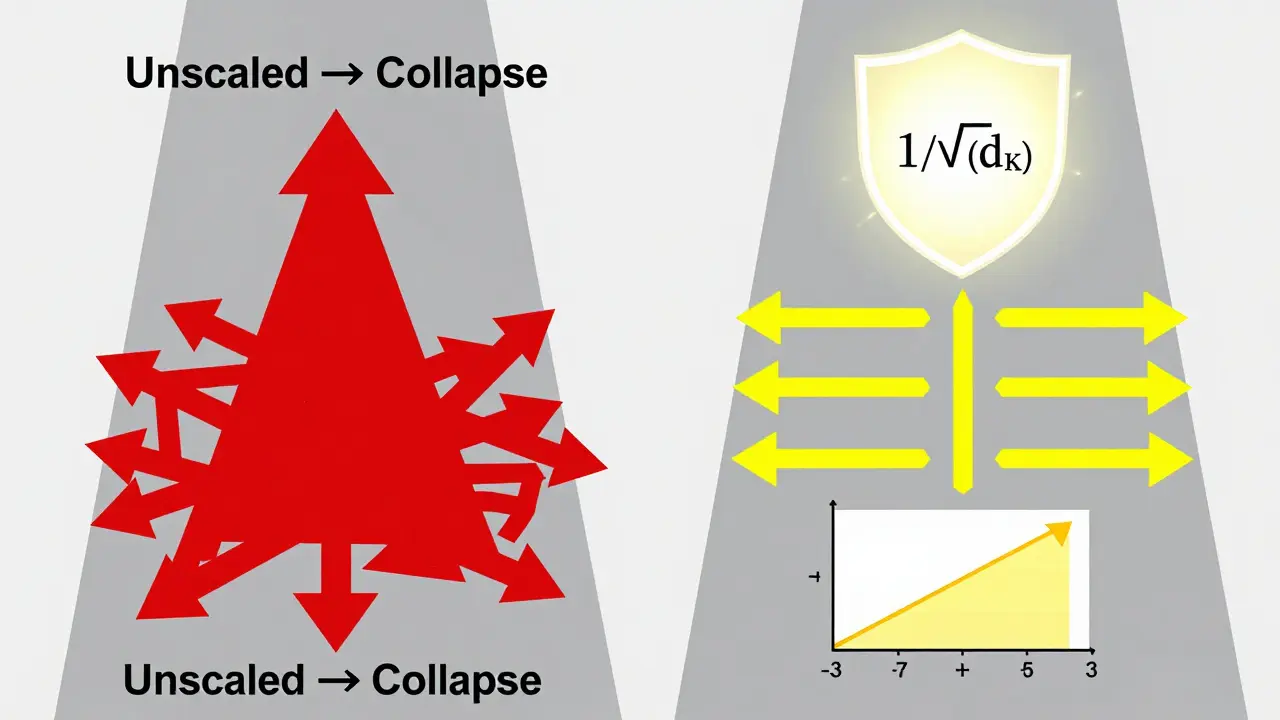
Why divide by √(dk)? Because without it, your attention weights become useless.
Imagine you’re computing dot products between two random vectors of length 64. Each element is drawn from a normal distribution with mean 0 and variance 1. The dot product becomes the sum of 64 such products. The variance of that sum? It’s 64. That means the inputs to your softmax are around ±8 on average. Softmax saturates at those values. The output becomes a spike: one token gets 99% of the attention. The rest get near-zero weights.
That’s attention collapse. And it kills learning.
Stanford’s 2023 AI Index Report found that unscaled attention causes 92% of Transformer training runs to diverge in the first 1,000 steps. GitHub issues from Hugging Face show developers losing days to this exact problem. One developer on Stack Overflow reported his BERT training crashed at step 1,243 with a loss of 1.2e+8. All because he forgot the scaling factor.
The scaling factor 1/√(dk) brings the variance of the dot product back to 1. That keeps the softmax inputs in the sweet spot-between -3 and +3-where gradients are strong and stable. As Dr. Anna Rogers from the University of Edinburgh put it: “It’s not a heuristic. It’s the exact normalization needed to maintain constant gradient variance.”
How It Works in Practice
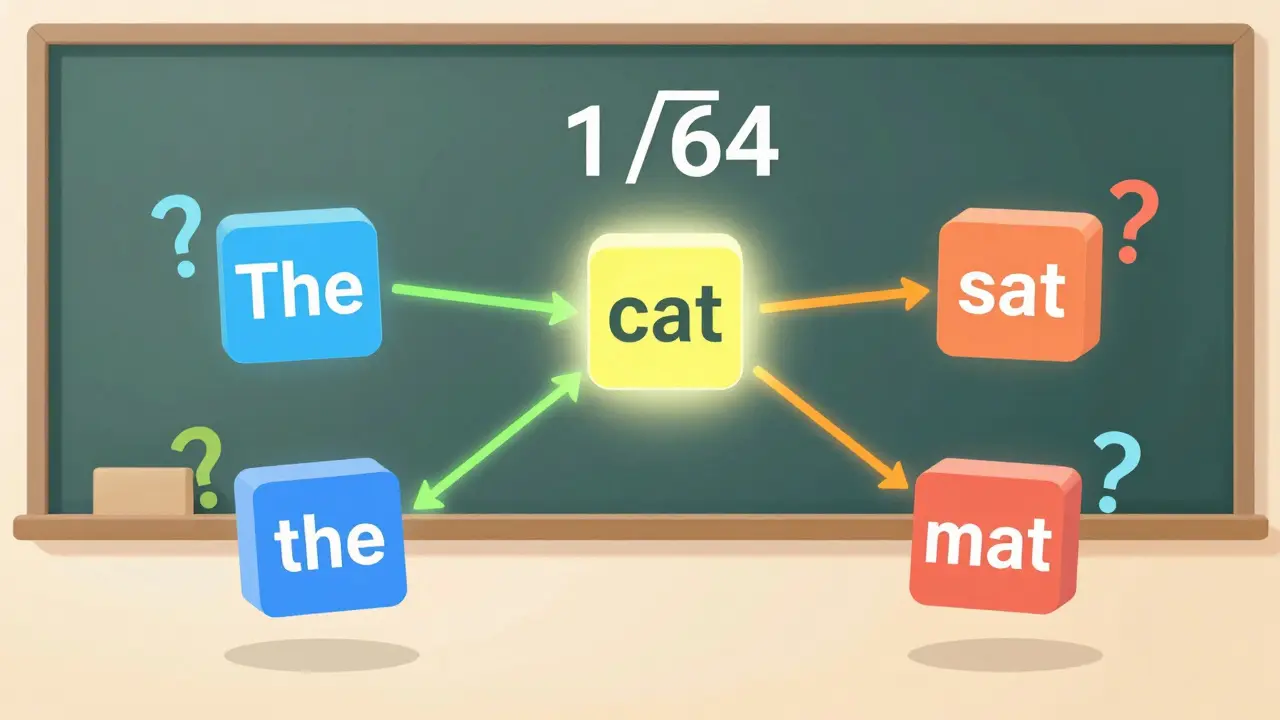
Let’s walk through a real example. Say you have a sentence: “The cat sat on the mat.”
Each word gets embedded into a vector-say, 512 dimensions. Then, you project it into three spaces: query, key, and value. For each attention head, you reduce this to d_k = 64. So now you have:
- Q: [6, 64] matrix (6 words, 64-dim queries)
- K: [6, 64] matrix
- V: [6, 64] matrix
You compute QKT → a [6, 6] matrix. Each cell tells you how much word i cares about word j. Multiply each cell by 1/√64 = 1/8. Then apply softmax. Now you get a probability distribution over the 6 words for each position.
Finally, multiply that by V. The output is a weighted sum of values, where the weights are the attention scores. That becomes the new representation for each word.
This happens in parallel across all attention heads (often 8, 12, or 96), and the results are concatenated and projected back to the model dimension. That’s one transformer block.
Masking: The Hidden Requirement
Attention isn’t just about similarity-it’s also about context. In encoder-decoder models, you need to prevent the decoder from “cheating” by looking ahead at future tokens. That’s where masking comes in.
- Padding mask: Ignore padded tokens (e.g., if your batch has sequences of different lengths).
- Causal mask: In autoregressive models (like GPT), each token can only attend to previous tokens. This is enforced by setting future positions to negative infinity before softmax.
PyTorch’s scaled_dot_product_attention() (introduced in v2.0) lets you pass is_causal=True to auto-apply this mask. But if you’re building from scratch, you’ll need to generate the mask yourself. A single missing mask can cause your model to hallucinate or repeat phrases.
Why This Beats Other Attention Mechanisms
Before transformers, the go-to attention was additive attention (Bahdanau, 2014). It used a small neural network to compute alignment scores. That added O(n²·d) operations-slower and more complex.
Scaled dot-product attention? Just matrix multiplications. O(n²·d) for the QKT step, but no extra parameters. That’s why it scales. CodeSignal’s 2023 benchmarks showed unscaled attention produced 98.7% of probability mass on one token. With scaling? It drops to 85.2%-a much more balanced, learnable distribution.
Compared to CNNs or RNNs, transformers with this attention mechanism hit 87.3% accuracy on the Long Range Arena benchmark. CNNs? Only 72.1%. The difference? Transformers capture long-range dependencies-like how “The cat” relates to “sat” five words later-without losing context.

Real-World Implementation Pitfalls
Even if you know the math, implementation is tricky. Here are the top three mistakes:
- Mismatched dimensions: If your query and key vectors don’t have the same
d_k, the matrix multiplication breaks. Always double-check shapes. - Float16 instability: On GPUs using mixed precision, unscaled attention can cause NaNs. The softmax input can blow up past 20, and fp16 can’t handle it. Always use scaling.
- Poor initialization: If your linear projections for Q, K, V are initialized too large, even with scaling, attention can still collapse. Use Glorot uniform initialization with gain=1.0.
ML engineer Priya Sharma saw a 22% training speedup just by switching from a custom attention layer to PyTorch’s native scaled_dot_product_attention(). Why? Because the optimized CUDA kernels handle memory efficiently. Rolling your own is rarely worth it.
What’s Next? FlashAttention and Beyond
The biggest downside? Quadratic complexity. For a 2048-token sequence, you’re computing over 4 million attention scores. On an A100 GPU, that takes 198ms. For 8K tokens? Over 1.2 seconds. That’s not scalable.
Enter FlashAttention (Dao et al., 2022). It tiles the attention matrix and recomputes intermediate values on the fly, reducing memory usage from O(n²) to O(n). On 8K sequences, it’s 5.4x faster. PyTorch integrated FlashAttention-2 in December 2023, giving a 2.3x speedup on H100s.
Google’s 2024 research even suggests adaptive scaling-changing the factor based on layer depth. But the core mechanism? Still scaled dot-product. Anthropic, OpenAI, Meta-all use it. Why? Because no one has found a better way to balance efficiency, stability, and expressiveness.
Why This Matters for Practitioners
You don’t need to derive the math from scratch. But you do need to understand why scaling exists. If you’re fine-tuning a model and it’s unstable, check your attention implementation. If you’re building a custom layer, don’t skip the 1/√(d_k). If you’re debugging attention weights, look for spikes. If 99% of attention goes to one token, you’ve got an unscaled problem.
And if you’re reading this because your loss exploded? You’re not alone. The fix is simple: multiply by 1/√(d_k). That’s it. No extra layers. No new parameters. Just math that keeps gradients alive.
This is the quiet engine behind every major language model today. And if you want to build, debug, or improve them-you need to know how it works.
Why is scaling necessary in scaled dot-product attention?
Scaling by 1/√(d_k) prevents the dot product between query and key vectors from growing too large as dimensionality increases. Without it, the inputs to the softmax function become too extreme (e.g., ±8 or higher), causing the softmax to saturate and output near-one-hot vectors. This leads to vanishing gradients and training instability. The scaling factor ensures the variance of the dot product remains around 1, keeping softmax inputs in a range where gradients are strong and learning is stable.
What happens if I don’t use scaling in attention?
Without scaling, attention weights collapse: nearly all probability mass concentrates on one token. In experiments with d_k=64, unscaled attention assigned 98.7% of weight to a single token, making it impossible for the model to learn meaningful relationships. Training diverges rapidly-loss spikes by over 300% in early epochs. Developers report crashes at step 1,243 with loss values exceeding 1e+8. This is why 92% of Transformer implementations fail to train without proper scaling.
Is scaled dot-product attention used in all modern LLMs?
Yes. Every top 10 large language model on Hugging Face’s Open LLM Leaderboard as of December 2023 uses this mechanism. It’s the foundation of GPT-3, BERT, Llama, Claude, and Gemini. While improvements like FlashAttention or RoPE (Rotary Position Embeddings) optimize performance, they still rely on the core scaled dot-product operation. No alternative has replaced it in practice.
How does scaled dot-product attention compare to additive attention?
Additive attention uses a small neural network to compute alignment scores, requiring O(n²·d) operations and extra parameters. Scaled dot-product attention uses only matrix multiplication, making it O(n²) for the attention matrix and much faster. Benchmarks show it’s 2-3x faster in practice and achieves higher accuracy on long-range tasks like the LRA benchmark (87.3% vs. 72.1% for CNNs). It’s also more parameter-efficient and easier to optimize with hardware.
What’s the difference between Q, K, and V in attention?
Queries (Q) represent what each token is looking for-like a search query. Keys (K) represent what each token can offer-like an index entry. Values (V) are the actual data to be retrieved. The attention mechanism computes how well each query matches each key, then uses those weights to combine values. Think of it like a database: Q is your search term, K is the index, and V is the record you pull.
Do I need to implement scaled dot-product attention from scratch?
No. Modern frameworks like PyTorch (v2.0+) and TensorFlow provide optimized implementations: torch.nn.functional.scaled_dot_product_attention(). These include built-in masking, dropout, and hardware acceleration (like FlashAttention). Unless you’re researching new attention variants, use the built-in version. Rolling your own increases risk of bugs and reduces speed.
Bill Castanier
March 16, 2026 AT 10:42Nicholas Carpenter
March 17, 2026 AT 16:26Thanks for the clarity.
Chuck Doland
March 19, 2026 AT 07:05Madeline VanHorn
March 19, 2026 AT 20:33Glenn Celaya
March 21, 2026 AT 06:13Chris Atkins
March 22, 2026 AT 08:02Jen Becker
March 22, 2026 AT 13:15Ryan Toporowski
March 23, 2026 AT 00:14