Traffic Shaping and A/B Testing for Large Language Model Releases
 Mar, 24 2026
Mar, 24 2026
When you roll out a new version of a large language model (LLM), you're not just pushing updated code-you're releasing a system that thinks, guesses, and responds in unpredictable ways. A small change in weights can make the model suddenly give dangerously wrong medical advice, miss subtle fraud patterns, or start sounding robotic on simple questions. Traditional software deployment doesn't work here. You can't just flip a switch and hope for the best. That’s where traffic shaping and A/B testing come in-not as nice-to-haves, but as non-negotiable safety nets.
Why Traffic Shaping Isn't Optional for LLMs
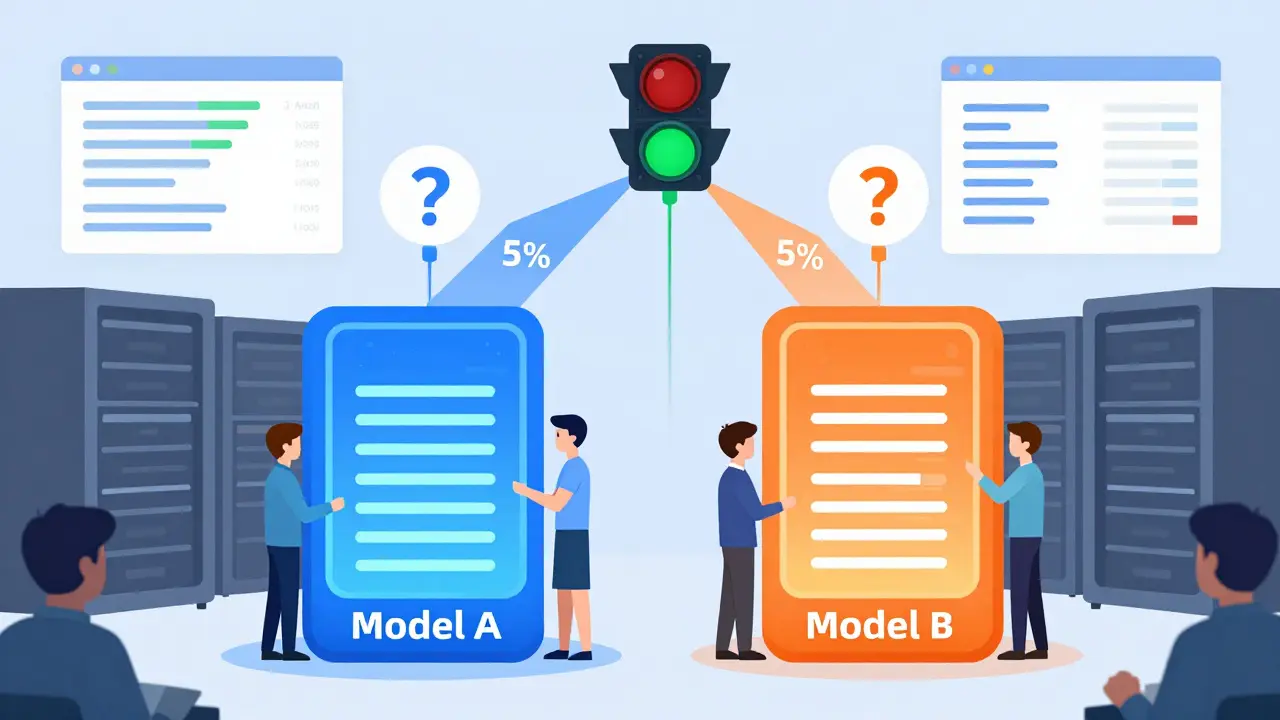
Most software updates are deterministic. If a function breaks, it breaks the same way every time. LLMs don’t work like that. They’re probabilistic. One prompt might get a perfect answer. The next, almost identical one, might hallucinate a fake citation or refuse to answer because of a tiny shift in word order. This makes pre-deployment testing nearly useless. You can’t test every possible user input. So instead of testing in isolation, you test in real time-with real users. Traffic shaping means slowly introducing the new model to a small slice of live traffic. Start with 1%. Then 5%. Then 10%. You watch what happens. If response quality drops, latency spikes, or safety filters trigger too often, you pause. You don’t crash the whole system. You isolate the risk. This approach is now standard in enterprises with high-stakes LLM use cases-like financial advice bots, medical triage assistants, or legal document analyzers. According to NVIDIA’s 2024 LLM operations guide, production systems must maintain 99.95% uptime during model transitions. That’s only possible with controlled traffic shifts.How A/B Testing Works for Language Models
A/B testing for LLMs isn’t about two button colors. It’s about comparing two models side by side on real user queries. You send half of a user’s requests to Model A (the current version) and half to Model B (the new one). You don’t tell the user. You just measure what happens. Key metrics you track:- Latency: Is the new model slower? For interactive apps, anything over 2 seconds hurts user experience.
- Cost per query: New models often use more compute. A $0.0003 cost per 1,000 tokens might seem tiny, but at 10 million queries a day, that’s $3,000 extra daily.
- Accuracy: Measured against gold-standard datasets or human evaluators. Did the new model start misinterpreting sarcasm? Missing key facts?
- Safety compliance: How often does it generate harmful, biased, or off-policy content? This is tracked using internal red teaming benchmarks.
Smart Routing: Beyond Load Balancing
Simple round-robin routing won’t cut it. You need semantic routing. This means the system looks at the content of each request and decides which model is best suited. For example:- A user asks, “What’s the capital of France?” → Route to a lightweight, fast model.
- A user asks, “Based on my medical history, should I take this drug?” → Route to a heavily validated, safety-audited model.
Infrastructure Requirements
Running multiple models in parallel isn’t cheap. You need:- High-availability gateways: Tools like Kong or custom Kubernetes operators that handle real-time routing decisions.
- Real-time monitoring: Systems that track over 50 metrics-from token throughput to toxicity scores-and alert when any deviates more than 5% from baseline.
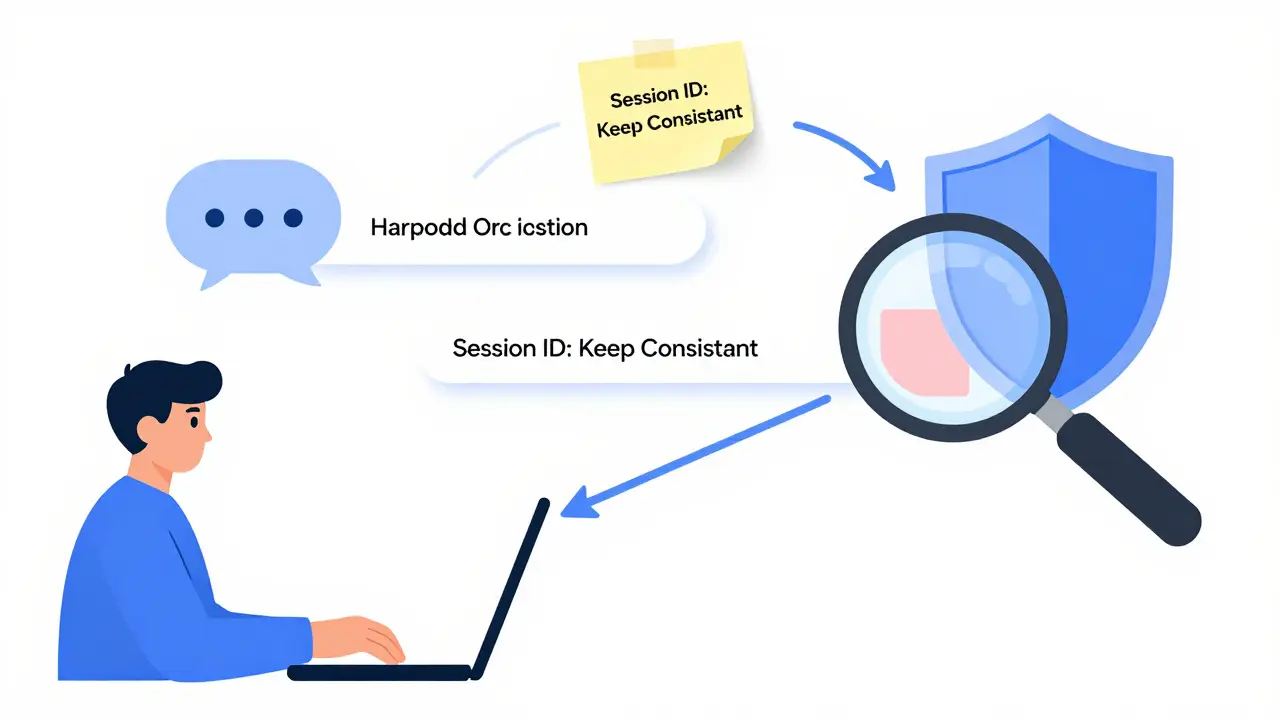
- Session persistence: If a user is in a multi-turn conversation, you can’t switch models mid-chat. Sticky routing based on conversation IDs keeps the context consistent.
- End-to-end encryption: Cloudflare recommends TLS 1.3 for all LLM traffic to prevent model leakage during testing.
Commercial Tools vs. Custom Builds
You have three paths:- Cloud-native platforms: AWS SageMaker, Google Vertex AI, Azure ML Studio. They integrate tightly with your cloud billing and offer automated A/B testing. Monthly costs: $8,000-$25,000.
- Specialized LLMOps vendors: NeuralTrust, Arthur AI, WhyLabs. These offer advanced semantic routing and compliance scoring. Pricing starts at $15,000/month.
- Custom-built: Using Kubernetes, BentoML, or open-source routers. Requires 3-6 months of engineering work and deep ML ops expertise.
What’s Changing in 2025-2026
The next wave isn’t just about routing-it’s about self-optimizing systems. Google’s November 2024 update to Vertex AI Traffic Director automatically detects statistical significance in A/B tests, cutting manual analysis time by 70%. AWS’s December 2024 update to SageMaker Pipelines now prioritizes cost efficiency: it routes queries to the cheapest model that still meets quality thresholds. By 2027, MIT CSAIL predicts 80% of enterprise LLMs will use automated traffic shaping driven by real-time model evaluation. Instead of setting static rules, the system will learn: “When users ask about tax law, Model C is 12% more accurate than Model D. Route 80% there.”
Who’s Leading Adoption?
Adoption isn’t even across industries:- Financial services: 47% adoption. High regulatory risk. Can’t afford hallucinated investment advice.
- Healthcare: 39% adoption. Medical liability is too high for untested models.
- Retail & media: 28% adoption. Lower stakes. Many still use basic API gateways.
Common Pitfalls and How to Avoid Them
Most teams fail in three ways:- Defining vague success metrics: “Better response quality” isn’t measurable. Use human eval scores, automated benchmarks, or user satisfaction ratings.
- Ignoring session continuity: If a user says, “Explain that again,” and the system switches models mid-conversation, the answer makes no sense. Use conversation ID sticky routing.
- Underestimating the learning curve: It takes 6-12 months to build mature traffic shaping. Start small. Canary 5%. Watch. Learn. Scale.
Final Reality Check
Traffic shaping and A/B testing aren’t about being fancy. They’re about being responsible. LLMs aren’t just code. They’re decision engines. And when they make mistakes, real people get hurt. You don’t need the most expensive tool. You need a process: start small, monitor closely, and never deploy blindly. The data is clear: companies without this process face 68% higher risk of deployment failure, according to Gartner. That’s not a risk worth taking.Do I need traffic shaping if I’m just running a simple chatbot?
If your chatbot handles basic FAQs-like store hours or product specs-and doesn’t make decisions that affect users’ safety, finances, or health, you can skip advanced traffic shaping. A simple blue-green deployment might be enough. But if your bot gives advice, handles sensitive data, or interacts with real customers at scale, even a simple chatbot needs controlled rollout. You don’t want a minor model update to start giving wrong answers to 10,000 users overnight.
How long should an A/B test run before deciding to roll out?
There’s no fixed timeline. It depends on your traffic volume and how sensitive your metrics are. For a service with 1 million daily queries, you might see statistically significant results in 3-7 days. For lower traffic, it could take 2-4 weeks. The key is to use statistical significance tools-like those built into Vertex AI or NeuralTrust-to avoid stopping too early. Don’t rely on gut feeling. Let the data decide.
Can I test new models without increasing infrastructure costs?
Not really. Running two models at once adds overhead. But you can minimize it. Use smaller, distilled versions of your LLM for testing. Or route only high-risk queries to the new model while keeping low-risk ones on the old one. Some teams use model quantization to reduce memory usage. The goal isn’t to eliminate cost-it’s to make sure the cost is worth the safety gain.
What if the new model performs better but costs twice as much?
That’s where cost-aware routing comes in. Systems like AWS SageMaker now let you set quality thresholds and then automatically route traffic to the cheapest model that still meets them. So if Model B is 10% more accurate but costs 2x, you might route only 30% of traffic to it-enough to capture the benefit without breaking the budget. It’s not about choosing one model. It’s about balancing performance, cost, and risk.
Is there an open-source alternative to commercial LLMOps tools?
Yes. BentoML and Kserve are popular open-source options for model serving and traffic routing. They’re flexible and free, but you’ll need engineers who understand distributed systems, Kubernetes, and LLM behavior. Many teams start here to build internal expertise before switching to commercial tools. ReadTheDocs ratings for BentoML are 4.5/5, and it’s used by companies from startups to Fortune 500s. But be warned: you’re building your own traffic management system. It takes time.
Wilda Mcgee
March 24, 2026 AT 12:25Love how this breaks down traffic shaping like a safety net instead of some fancy tech buzzword. Seriously, if you're rolling out an LLM that touches real people-medical, legal, financial-you're not just deploying code, you're deploying trust. And trust? It shatters faster than a cheap phone screen. I've seen teams skip canary releases because 'it worked in testing'... then watch a model start telling diabetic users to skip insulin. Don't be that team. Start at 1%. Watch. Breathe. Then move.
Also-semantic routing? Game changer. Routing a simple 'what's the weather' query to a 70B model is like using a jetpack to commute to the corner store. Smart routing isn't optional, it's just common sense.
Chris Atkins
March 24, 2026 AT 15:00Jen Becker
March 25, 2026 AT 01:20Ryan Toporowski
March 25, 2026 AT 07:51Started with 2% canary, watched for 48 hours, caught a 17% spike in toxicity. Saved us. Seriously, don’t skip the slow rollout. Your users will thank you. 💪
Samuel Bennett
March 26, 2026 AT 11:20Rob D
March 27, 2026 AT 14:14Franklin Hooper
March 27, 2026 AT 15:52Jess Ciro
March 29, 2026 AT 01:53saravana kumar
March 30, 2026 AT 15:56