Transformer Architecture in Generative AI: A Practical Guide for Engineers
 Mar, 1 2026
Mar, 1 2026
When you ask a chatbot a question, translate a sentence in real time, or generate a poem from a single prompt, you’re interacting with a system built on transformer architecture. It’s not just another neural network-it’s the reason generative AI works as well as it does today. If you’re an engineer trying to understand how these models actually function under the hood, this guide cuts through the hype and gives you the concrete, practical details you need to implement, debug, or improve transformer-based systems.
Why Transformers Replaced RNNs and CNNs
Before transformers, sequence modeling relied on Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). RNNs processed text one word at a time, like reading a book from left to right, remembering what came before. But this caused problems: long sentences became memory-heavy, gradients vanished over distance, and training took forever. CNNs handled local patterns well-like detecting phrases-but couldn’t see the whole sentence at once. They missed relationships between words separated by dozens of tokens. Transformers solved both issues with one idea: look at everything at once. Instead of processing tokens sequentially, transformers analyze all tokens in parallel. This isn’t just faster-it changes how meaning is built. In an RNN, the word "it" in "The cat sat on the mat because it was warm" might only have access to the last few words. In a transformer, "it" instantly connects to "cat," "mat," and "warm" through attention. No memory decay. No sequential bottlenecks.The Three Core Components of a Transformer
Every transformer model, whether it’s BERT or GPT-4, is built from three fundamental parts:- Embedding Layer - Converts text into numbers. Words are split into tokens (subwords like "un-" and "-happiness"), then mapped to dense vectors. BERT Base uses 768-dimensional vectors; GPT-3 uses 12,288. These aren’t random-they’re learned representations of meaning.
- Transformer Blocks - The repeating units that do the real work. Each block contains two sub-layers: multi-head self-attention and a feed-forward network. These are stacked-6 layers in the original transformer, 12 in GPT-2 Small, 96 in GPT-4.
- Output Head - Takes the final hidden states and turns them into predictions: next word, translation, classification label. For language models, this is often a simple linear layer followed by softmax.
You don’t need to build these from scratch. Libraries like Hugging Face and PyTorch Lightning handle the plumbing. But if you’re optimizing performance or debugging strange outputs, knowing how each piece works is essential.
How Self-Attention Actually Works
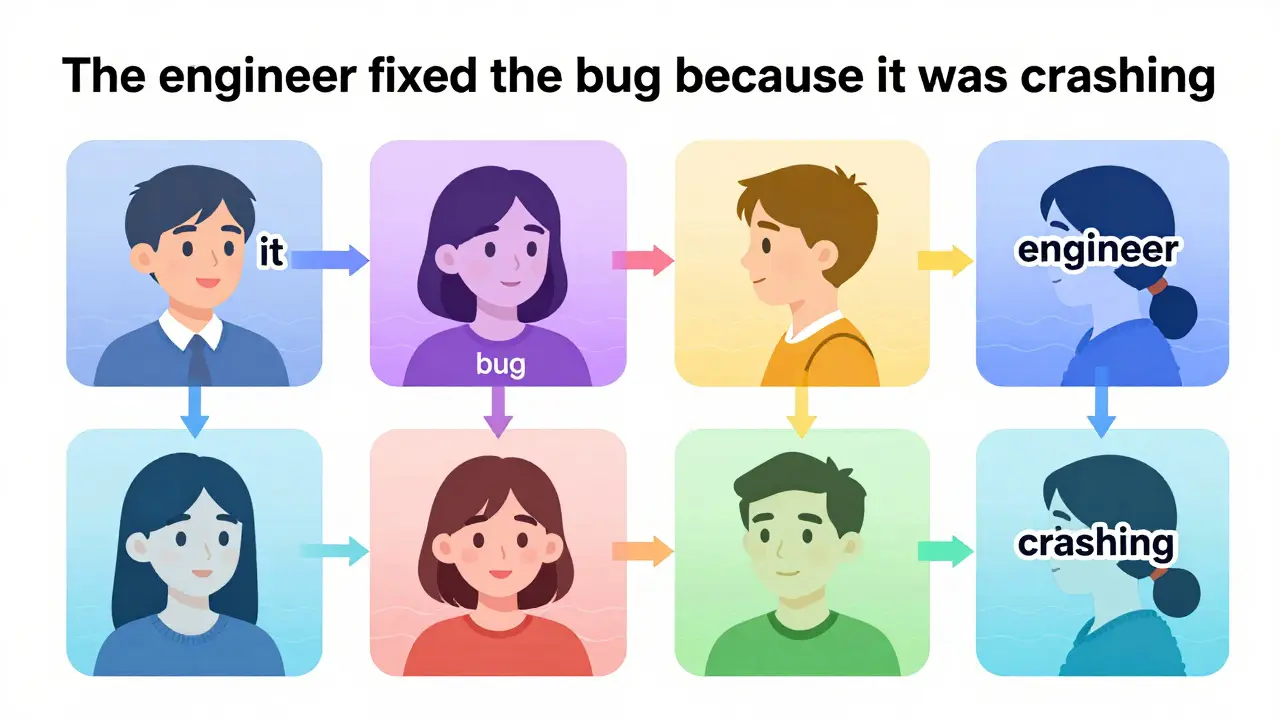
The magic is in self-attention. Forget the math for a second-think about it this way: when the model sees the sentence "The engineer fixed the bug because it was crashing," it doesn’t just guess what "it" refers to. It calculates a score between "it" and every other token: "engineer," "bug," "crashing," even "The." These scores form a matrix of relationships.Multi-head attention means this happens in parallel across 8, 12, or even 96 different "heads." Each head learns a different kind of relationship:
- One head might focus on syntactic roles (subject vs. object)
- Another might link pronouns to antecedents
- Another might capture emotional tone
These attention scores are weighted and summed to produce a new representation for each token. The output isn’t just a copy of the input-it’s a richer, context-aware version. After passing through multiple blocks, the representation of "bug" evolves from a simple word embedding to something like "a software flaw causing system instability," informed by the entire context.
Positional Encoding: The Missing Piece
Here’s the twist: since transformers process all tokens at once, they lose order. The word "dog bites man" and "man bites dog" would look identical without positional info.Enter positional encoding. The original transformer used sine and cosine waves of different frequencies to inject position into embeddings. Later models like RoBERTa and ALBERT switched to learned positional embeddings-just another set of parameters trained during learning. The key takeaway? Position matters. If your tokenizer strips punctuation or your input pipeline pads sequences inconsistently, the model will struggle to understand context. Always preserve token order and use the same positional encoding scheme your base model uses.
Encoder-Decoder vs. Decoder-Only Architectures
Not all transformers are built the same. There are two dominant patterns:| Feature | Encoder-Decoder (e.g., T5, BART) | Decoder-Only (e.g., GPT-3, GPT-4) |
|---|---|---|
| Structure | Two separate transformer stacks | Single stack, used for both encoding and decoding |
| Input | Source text (e.g., English sentence) | Prompt + context (e.g., "Translate to French: Hello") |
| Output | Target text (e.g., "Bonjour") | Generated text token by token |
| Use Case | Translation, summarization | Text generation, code completion |
| Training | Teacher-forcing: input + target provided | Autoregressive: predict next token from prior output |
If you’re building a chatbot or code assistant, you’re likely using a decoder-only model. If you’re translating documents, encoder-decoder is your go-to. The architecture choice affects how you structure prompts, manage memory during inference, and even how you fine-tune.
Training: Pre-Training and Fine-Tuning
You don’t train a GPT-4 from scratch unless you have a data center and a $100M budget. Instead, you use transfer learning:- Pre-train on massive unlabeled text (Common Crawl, Wikipedia, GitHub code). The model learns grammar, facts, and reasoning by predicting masked words (BERT) or next tokens (GPT).
- Freeze the transformer blocks. They’ve learned universal language patterns.
- Add a small task-specific head (e.g., classification layer for sentiment, regression head for summarization quality).
- Fine-tune only the head and maybe the last few transformer layers.
This cuts training time from weeks to hours and reduces data needs by 90%. A study from Stanford showed fine-tuning a BERT Base model on 5,000 labeled customer service tickets achieved 92% accuracy-nearly matching a model trained from scratch on 500,000 examples.
What Engineers Need to Watch Out For
Here are the practical pitfalls you’ll hit in real projects:- Memory overload - Attention matrices scale with n² (n = sequence length). A 4,096-token context uses 16 million attention weights. Use FlashAttention or sliding windows if you’re hitting GPU limits.
- Tokenization mismatches - If your tokenizer splits "don’t" into "do" and "n’t" but your training data used "don’t" as one token, performance drops. Always use the same tokenizer the base model used.
- Overfitting on small datasets - Transformers are hungry. Even fine-tuning can overfit on datasets under 10K examples. Use dropout, early stopping, or LoRA adapters.
- Latency spikes - First token generation is slow (cold start). Subsequent tokens are fast. If you’re building a real-time app, buffer prompts or use speculative decoding.
Real-World Impact: What Transformers Enable Today
Transformers aren’t theoretical. They’re in production:- GitHub Copilot uses a transformer fine-tuned on 159GB of public code to suggest entire functions.
- Google Translate runs on a transformer-based model that handles 133 languages with near-human fluency.
- Medical chatbots like Med-PaLM use transformers to parse patient notes and answer clinical questions with citations from journals.
- Legal AI tools analyze contracts by understanding clauses across 50+ pages, not just keyword matches.
The common thread? All of them rely on the transformer’s ability to understand context deeply. It’s not about memorizing patterns-it’s about reasoning across distance, ambiguity, and complexity.
What’s Next? Beyond the Standard Transformer
The original 2017 paper is just the start. New variants are solving its weaknesses:- Longformer - Uses sparse attention to handle 16K+ tokens without quadratic memory growth.
- MoE (Mixture of Experts) - Only activates a subset of layers per input (e.g., Mixtral 8x7B). Cuts inference cost by 40%.
- FlashAttention-2 - Optimized GPU kernels that reduce memory bandwidth by 5x and speed up training by 30%.
Engineers who understand the core transformer can adapt to these upgrades. You don’t need to master every variant-just know how attention, position, and layer stacking work. The rest is engineering.
Do I need to understand math to work with transformers?
No-not deep math. You need to understand what attention does, not how to derive its formula. Focus on the input-output behavior: tokens go in, attention scores are computed, outputs are updated. Libraries handle the linear algebra. Your job is to manage data flow, memory, and fine-tuning. If you can read pseudocode or trace a neural network forward pass, you’re ready.
Can transformers handle non-text data?
Yes. Vision Transformers (ViTs) split images into patches and treat them like tokens. Audio models like Whisper convert sound waves into spectrogram patches. Even protein sequences in biology are now modeled as tokenized strings. The transformer is a general sequence processor. If your data can be broken into discrete units with order, it can be fed into a transformer.
Why does my transformer generate repetitive text?
Repetition usually comes from greedy decoding or low temperature settings. Try switching from greedy search to beam search with length penalty, or increase temperature to 0.7-0.9. Also check your prompt: if it’s too vague or contains loops (e.g., "Explain X. Explain X again."), the model will echo it. Use negative prompting (e.g., "Avoid repeating phrases") or implement a repetition penalty during generation.
How do I choose between BERT and GPT for my project?
Use BERT if you need to understand context from both directions-like classifying sentiment, extracting entities, or answering questions based on a passage. Use GPT if you need to generate new text-like writing emails, summarizing documents, or coding assistants. BERT is bidirectional; GPT is autoregressive. They’re not competitors-they’re tools for different jobs.
Is it worth training my own transformer from scratch?
Almost never. Training a transformer requires petabytes of data, thousands of GPUs, and months of compute. Even Meta’s Llama 2 used 20,000+ GPU hours. For 99% of engineers, start with a pre-trained model from Hugging Face, fine-tune it on your data, and deploy. The real value isn’t in training-it’s in adapting, optimizing, and integrating.
Next Steps for Engineers
Start here:- Install Hugging Face Transformers and load a pre-trained model (e.g., "bert-base-uncased" or "gpt2").
- Feed it a sentence and visualize the attention weights using their built-in visualizer.
- Try fine-tuning it on a small dataset-like movie reviews or customer support tickets.
- Measure latency and memory usage on your target hardware.
- Compare performance against a rule-based or SVM baseline.
If you can do those five steps, you understand more than 80% of engineers working with AI today. The transformer isn’t magic. It’s a tool. And like any tool, mastery comes from using it-not just reading about it.
Nikhil Gavhane
March 3, 2026 AT 06:03Transformers are one of those rare breakthroughs where the theory actually translates to real-world impact. I’ve seen teams go from struggling with RNNs that collapsed on long documents to deploying transformer models that handle legal contracts with ease. The key isn’t just the architecture-it’s how it changes your thinking about context. You stop treating text as a sequence and start treating it as a web of relationships. That shift alone is worth the learning curve.
Rajat Patil
March 4, 2026 AT 21:18This is one of the clearest explanations I’ve read. I work with legacy systems that still use CNNs for document classification, and seeing the contrast made me realize how much we’ve been holding ourselves back. The part about positional encoding was especially helpful-I had no idea how much padding inconsistencies could mess up attention weights. Will definitely share this with my team.
deepak srinivasa
March 6, 2026 AT 00:11I’ve been playing with Hugging Face’s attention visualizer and it’s mind-blowing. When you see a head clearly linking ‘it’ to ‘bug’ in a code error message, even when they’re separated by 12 tokens, you realize this isn’t just statistical guessing. It’s pattern recognition at a structural level. I wonder how much of this is learned versus hardcoded in the training data. Do we know if models generalize attention patterns across domains?
Bhagyashri Zokarkar
March 7, 2026 AT 21:35ok so like transformers are cool and all but have you ever tried running one on a raspberry pi? no? yeah me neither. i tried fine tuning bert on my laptop and my fan sounded like a jet engine. and dont even get me started on tokenization. i had this one sentence ‘can u fix this’ and it split into ‘can’, ‘u’, ‘fix’, ‘this’ and my model started predicting ‘you’ instead of ‘u’ like it was some kind of grammar police. why does it even care? i just wanted a chatbot to say ‘sure thing bro’ not ‘Certainly, I am happy to assist you with your request.’
Vishal Gaur
March 8, 2026 AT 00:40so i read this whole thing and honestly i think its kinda overhyped. i mean sure transformers work, but i’ve seen models that just memorize the training data and spit back what they saw. like how do we even know its not just copying patterns? and what about bias? if the model was trained on github code, does that mean it thinks all programmers are white guys in hoodies? and dont even get me started on the energy usage. one gpt-4 training run could power a small country for a week. are we really ok with that? i feel like we’re building this giant machine and no one’s asking what it’s for.
Eka Prabha
March 8, 2026 AT 11:59Let me be clear: transformers are not a breakthrough-they’re a distraction. The entire field has been hijacked by hype-driven academia and corporate labs chasing metrics, not solutions. You think attention weights explain meaning? They’re just statistical artifacts masked as intelligence. And don’t get me started on positional encoding-sine waves? Learned embeddings? It’s all just curve-fitting dressed up as cognition. Meanwhile, real progress in AI is happening in neurosymbolic systems, sparse architectures, and causal reasoning models that don’t require petabytes of data. But no one wants to talk about those because they don’t fit the investor pitch. This is just the latest AI bubble, and engineers are the ones stuck debugging memory overflows while the VCs cash out.
Rakesh Dorwal
March 8, 2026 AT 14:16Look, I get that this is technical, but let’s not forget: India is the world’s largest exporter of software engineers. We built the backend systems that run half the internet. And now we’re just sitting here fine-tuning GPT models instead of building our own architectures? We have the talent, the bandwidth, the hunger. Why are we importing models from the US and Europe and calling it innovation? We need to train our own models on Indian languages, legal texts, medical records-on our data, in our context. This isn’t about tech-it’s about sovereignty. Let’s stop being consumers of AI and start being creators.
Bharat Patel
March 9, 2026 AT 10:12I’ve been thinking a lot about what transformers are really doing. It’s not that they ‘understand’ language-it’s that they become incredibly good at mirroring it. Like a mirror that’s been polished by a million conversations. The real question isn’t how they work, but what we’re asking them to reflect. When we feed them GitHub code, they learn to code. When we feed them poetry, they write poetry. But what happens when we feed them our fears? Our biases? Our loneliness? The model doesn’t judge. It just echoes. Maybe the transformer isn’t the future of AI… maybe it’s the future of human self-reflection. We’re building a tool that doesn’t think… but it shows us exactly what we’ve been thinking.
Rahul Borole
March 11, 2026 AT 07:08As someone who has implemented transformer-based systems in production across three continents, I can confirm: the biggest challenge isn’t the architecture-it’s the data pipeline. Tokenization mismatches, inconsistent positional encoding, and unvalidated input sequences cause 80% of production failures. Always validate your tokenizer against the base model’s vocabulary. Never assume padding is handled correctly. Use static attention masks and monitor memory allocation per sequence length. And for God’s sake, test with real-world latency profiles, not synthetic benchmarks. The math is elegant. The engineering is brutal. Master the latter, and you’ll outperform teams with twice your compute.