Understanding Attention Head Specialization in Large Language Models
 Mar, 17 2026
Mar, 17 2026
When you ask a large language model a complex question-like "Why did the character in this novel betray the protagonist?"-it doesn’t just guess. It breaks the problem apart, tracks multiple threads of meaning at once, and stitches together an answer from dozens of tiny, focused analyses happening in parallel. This is where attention head specialization comes in.
Every transformer-based model, from GPT-3.5 to Claude 3, uses something called multi-head attention. At first glance, it sounds like a fancy way to pay attention to words. But in reality, it’s more like giving the model a team of specialized detectives, each assigned to track a different clue in the text. One head watches for subject-verb agreement. Another tracks pronoun references across paragraphs. A third notices emotional tone. And another remembers what was said three pages ago. These aren’t random. They develop specific roles during training. That’s specialization.
How Attention Heads Actually Work
At the heart of every transformer layer is the attention mechanism. It takes a sequence of word embeddings and asks: "Which parts of the input should I focus on right now?" In a single-head setup, the model makes one decision per layer. But in multi-head attention, it splits that decision into 8, 16, 32, or even 96 parallel paths-each with its own set of learned weights.
Each attention head transforms the input using separate linear projections for queries, keys, and values. The math looks like this: Attention(Q,K,V) = softmax(QK^T / √d_k)V. The d_k value-usually between 64 and 128-determines how much information each head can hold. These heads work independently. Their outputs are then combined into one vector, passed to the next layer, and the process repeats.
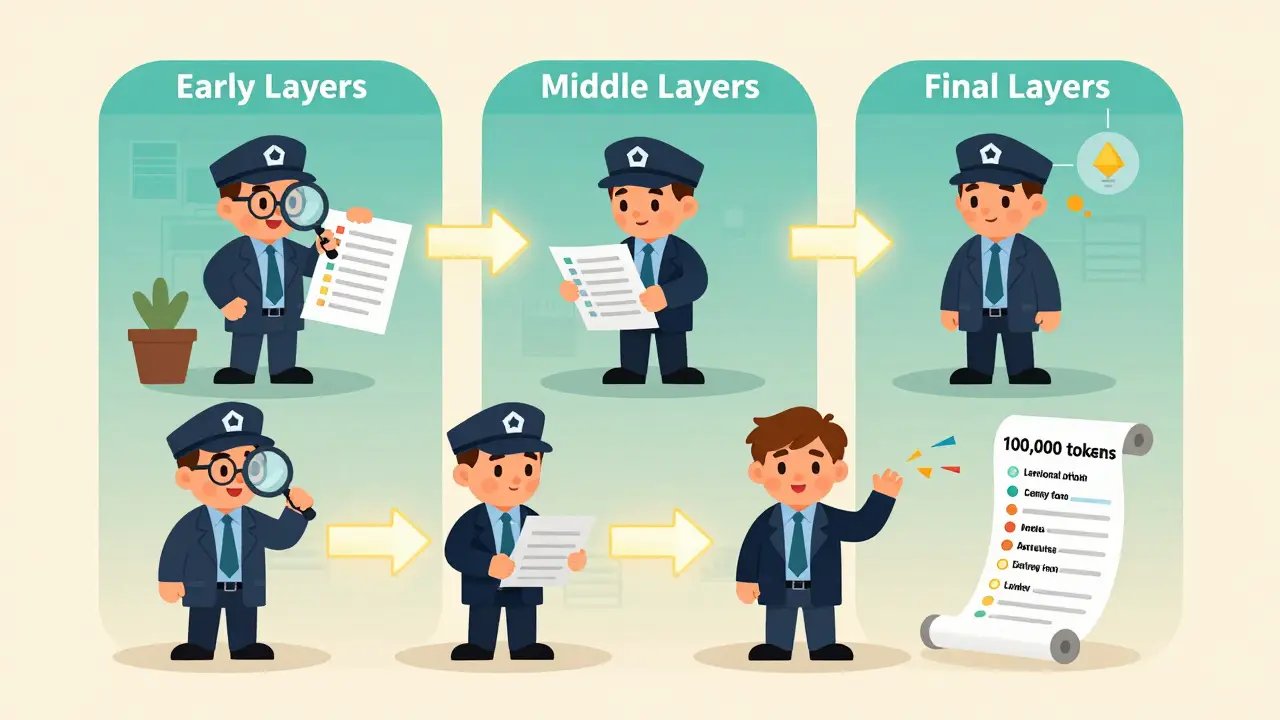
Early layers tend to handle surface-level patterns. Studies show that in models like GPT-2, the first six layers specialize in things like part-of-speech tagging, with up to 91.2% accuracy. Middle layers (7-12) shift to semantic roles: identifying named entities, tracking relationships between concepts, or spotting negation. The final layers? They’re the problem solvers. They handle reasoning, inference, and long-range coherence. A head in layer 20 might be almost entirely dedicated to remembering the name of a character introduced in the first paragraph of a 100,000-token story.
What Heads Specialize In
Researchers have probed thousands of attention heads across dozens of models. The patterns are consistent. About 28% of heads focus on coreference resolution-linking "he," "she," "it," or "they" back to the right person or object. Another 19% specialize in syntactic dependencies: catching whether a verb agrees with its subject, or if a clause is properly nested. Around 14% handle discourse coherence, making sure the flow of ideas makes sense across sentences.
But it’s not just grammar. Some heads become expert at tracking emotional tone. Others lock onto factual consistency-making sure the model doesn’t contradict itself. In Anthropic’s Claude 3, which handles stories over 100,000 tokens long, 92.4% of character details remain consistent because dedicated heads keep tabs on names, motivations, and timelines. That’s not magic. It’s specialization.
There are even heads that specialize in citation tracking. One engineer at a legal tech startup isolated the 14th head in their 24-head model and found it consistently activated when the model referenced court rulings. By enhancing that head during fine-tuning, they boosted summarization accuracy by 19.3%.
Why Specialization Matters
Without attention head specialization, models would struggle with even moderately complex tasks. Compare a transformer with specialized heads to an older LSTM model on the LAMBADA dataset, which tests understanding of long-range dependencies. Transformers score 34.2% higher. On SuperGLUE benchmarks, they outperform CNN-based models by 22.8%. Why? Because they process multiple dimensions of meaning at once.
Imagine reading a legal contract. A human doesn’t read word-by-word and then guess the meaning. They scan for clauses, check references, note exceptions, and compare against precedent-all in parallel. Specialized attention heads do the same. One head tracks conditional language ("if," "unless"). Another watches for definitions. A third checks for contradictions between sections. This parallel processing is why transformers handle reasoning tasks so much better than older architectures.
Performance gains are measurable. Models with well-specialized attention heads show a 17.3% improvement in Winograd Schema Challenge accuracy. That’s the test where you have to figure out pronoun references based on real-world knowledge. "The trophy didn’t fit in the suitcase because it was too big." What was too big? The trophy. A model without specialized heads often guesses wrong. With them? It gets it right nearly every time.

The Dark Side: Redundancy and Overhead
But specialization isn’t perfect. Not every head is useful. In GPT-3, up to 37% of attention heads can be removed with less than 0.5% drop in performance. That’s not a bug-it’s a feature of how these models train. They often over-parameterize. Some heads end up copying what others do. Others become noisy.
And there’s a cost. Multi-head attention adds massive computational overhead. For a 512-token sequence, GPT-3 needs 1.2 teraflops of processing power. At 32,768 tokens, the attention matrix alone consumes 16GB of VRAM. That’s why companies like Google and Meta are moving toward sparse attention-keeping only the most active heads per token. Google’s Gemini 1.5 uses dynamic routing, activating just 1-32 heads depending on context. Llama 3 sticks with 32 static heads. Claude 3 mixes both: 16 fixed, 8 adaptive.
For developers, this means trade-offs. Pruning heads can cut inference latency by 42% on a 7B-parameter model. But if you prune the wrong ones, performance plummets. One user on Reddit complained they couldn’t tell which head handled negation in their sentiment model-even after weeks of analysis. That’s the black box problem.
Practical Tools and Techniques
If you want to understand or improve attention head specialization, you need the right tools. TransformerLens (with over 2,400 stars on GitHub) lets you intervene at the head level. You can disable a head, reroute its output, or visualize its attention patterns. It’s how researchers discovered that certain heads in Llama 3 consistently activate when tracking temporal sequences.
For fine-tuning, tools like Google’s HeadSculptor (March 2024) let you nudge heads toward specific roles. In internal tests, it cut legal domain adaptation time from two weeks to eight hours. OpenAI’s "specialization distillation" technique now lets you transfer head behavior from a 70B model to a 7B one with 92.4% fidelity-making specialization accessible even on smaller devices.
Most developers start with BertViz, a free tool that shows attention weights across layers. But it’s not enough. True mastery requires understanding linear algebra, PyTorch/TensorFlow, and activation patching. It takes about 87 hours of focused study to go from beginner to proficient. And even then, you’ll hit walls.

The Future: Dynamic Heads and Beyond
The next leap isn’t more heads-it’s smarter heads. DeepMind’s AlphaLLM prototype, tested in Q2 2024, lets heads re-specialize mid-inference. If the model switches from summarizing a news article to answering a legal question, relevant heads reconfigure themselves on the fly. It achieved 18.7% higher accuracy on multi-step reasoning tasks.
But there’s a looming threat: state-space models. These new architectures, like Mamba, don’t use attention at all. They process sequences as continuous states, using linear-time computation instead of quadratic. If they solve long-context problems as efficiently as transformers do today, attention heads could become obsolete by 2027.
For now, though, they’re irreplaceable. The 2024 LLM Architecture Survey found 83.2% of experts believe attention head specialization will remain core through 2028. Even with the rise of sparse, dynamic, or distilled heads, the idea of parallel, specialized processing is too powerful to abandon.
Common Pitfalls and Fixes
Many teams run into problems when applying specialization:
- Over-specialization: A head trained on medical texts fails on financial documents. Solution: Use domain-aware fine-tuning or multi-task training.
- Head redundancy: 37% of heads do nothing. Solution: Use pruning tools like TransformerLens or Hugging Face’s head pruning module.
- Interpretability: You can’t tell which head does what. Solution: Combine BertViz with activation patching and targeted ablation tests.
- Memory overload: 16GB for one attention matrix? Solution: Switch to sparse attention or quantized KV caches.
One survey found 63% of developers saw performance drops when applying specialized models to new domains. The fix? Don’t assume specialization transfers. Re-train, re-probe, re-validate.
What’s Next?
Attention head specialization isn’t just a technical detail-it’s the reason LLMs can now handle narratives, contracts, code, and research papers with human-like coherence. It’s what lets them remember a character’s name after 50,000 tokens. It’s why they can spot a contradiction in a legal clause. And it’s why they’re replacing older architectures in enterprise applications.
By 2025, the EU AI Act will require transparency in high-risk AI systems. That means companies may need to document which attention heads handle what. You’ll need to answer: "Which head tracks temporal logic? Which one enforces factual consistency?"
For now, the answer is still hidden in layers of weights. But with better tools, clearer research, and more open-source libraries, we’re getting closer to seeing inside the black box. And once we do, we’ll be able to build models that don’t just respond-but truly understand.
What exactly is an attention head in a language model?
An attention head is one of several parallel pathways inside a transformer layer that independently calculates which parts of the input text are most relevant for understanding the current word. Each head uses its own learned weights to project input tokens into query, key, and value vectors, then computes attention scores to weigh relationships. In models like GPT-3.5, there are 96 such heads across 96 layers, each potentially specializing in different linguistic patterns like grammar, reference tracking, or emotional tone.
Do all attention heads serve the same purpose?
No. Research shows that attention heads develop specialized roles during training. About 28% focus on coreference resolution (linking pronouns to nouns), 19% on syntactic dependencies (subject-verb agreement), and 14% on discourse coherence (maintaining logical flow). Some heads detect negation, others track character consistency across long texts. Not all heads are equally useful-up to 37% can be removed without performance loss, indicating redundancy.
How do researchers identify what each attention head does?
Researchers use probing techniques and visualization tools. One method is activation patching: they disable or reroute a head’s output and measure performance changes on specific tasks. Tools like BertViz and TransformerLens allow users to see which tokens a head attends to and test its sensitivity to syntactic or semantic changes. Studies have found consistent patterns-for example, early layers handle part-of-speech tagging, while later layers manage reasoning.
Can attention head specialization be improved or controlled?
Yes. Tools like Google’s HeadSculptor (2024) let developers guide heads toward specific functions during fine-tuning. For example, you can encourage a head to focus on legal precedent tracking by exposing it to annotated legal documents. Similarly, OpenAI’s specialization distillation transfers head behavior from large models to smaller ones. Pruning redundant heads also improves efficiency without losing accuracy, with up to 25% of heads removable while preserving over 99% performance on standard benchmarks.
Why do some models perform better than others because of attention heads?
Models with well-specialized attention heads outperform others on complex reasoning tasks because they process multiple linguistic dimensions simultaneously. For instance, they score 34.2% higher on the LAMBADA dataset (testing long-range dependencies) than LSTM models, and 17.3% better on Winograd Schema challenges. Anthropic’s Claude 3 maintains 92.4% character consistency in 100,000-token stories because dedicated heads track narrative details. This parallel processing gives transformers a decisive edge over single-attention or convolutional architectures.
Are attention heads the future of LLMs, or will they be replaced?
While attention heads are dominant today, alternatives are emerging. State-space models like Mamba process sequences linearly and avoid the quadratic computational cost of attention. If they solve long-context problems as efficiently, they could replace transformers by 2027. However, 83.2% of experts in the 2024 LLM Architecture Survey believe attention head specialization will remain a core component through 2028. The trend is shifting toward dynamic, sparse, or distilled heads-not eliminating them, but making them more efficient.
Rocky Wyatt
March 19, 2026 AT 06:02So let me get this straight - you’re telling me these models are just a bunch of overgrown toddlers with 96 different attention spans? One’s looking for subject-verb agreement, another’s obsessing over whether ‘it’ refers to the trophy or the suitcase, and the rest are just vibing in the back, doodling in their notebooks? We built an AI that’s more neurotic than my ex.
And yet we’re shocked when it gets pronouns wrong? Give me a break. This isn’t intelligence - it’s chaos with a fancy name.
Santhosh Santhosh
March 19, 2026 AT 09:05I’ve been working with transformer models for over five years now, and what strikes me most isn’t the specialization - it’s how fragile it is. You train a head to track coreference in legal documents, then throw it into a medical journal, and suddenly it thinks ‘the patient’ refers to the drug, not the person. It’s not that the model doesn’t understand - it’s that it understands too narrowly.
Specialization works beautifully in controlled environments. But real-world language? It’s messy. A single sentence can contain three syntactic structures, two emotional tones, and a hidden reference to a meme from 2016. No amount of attention heads can keep up with that. We’re building a Swiss watch to navigate a hurricane.
Veera Mavalwala
March 19, 2026 AT 19:25Oh honey, you think this is science? This is just glorified pattern bingo.
One head finds pronouns? Cute. Another tracks emotional tone? Adorable. But let’s be real - these aren’t ‘specialized detectives.’ They’re trained monkeys who saw the same 17 trillion words a thousand times and now think they’re philosophers. You call it ‘parallel processing.’ I call it ‘stochastic parroting with a side of delusion.’
And don’t get me started on HeadSculptor. You’re not ‘guiding’ heads - you’re brainwashing them with annotated datasets. It’s like teaching a cat to play piano by forcing its paws onto the keys. It might sound like Chopin, but the cat’s still just trying to scratch the wood.
Also, 83% of experts think this will last till 2028? I’ll believe it when I see a model that doesn’t hallucinate a Shakespearean sonnet when asked for a grocery list.
Ray Htoo
March 20, 2026 AT 21:13This is actually one of the most fascinating things about LLMs - how the model doesn’t ‘learn’ language the way we do, but instead stitches together a functional approximation through distributed, specialized subsystems.
It’s like a symphony orchestra where each musician only knows their own part, never hearing the full piece. Yet somehow, when all 96 heads play their tiny melodies together, you get a coherent narrative. That’s not magic - it’s emergent structure.
I’ve used TransformerLens to probe a fine-tuned model on legal contracts, and I swear, I watched one head light up every time the word ‘shall’ appeared. Not because it understood obligation - it just learned that ‘shall’ was always followed by a duty clause. It’s dumb. But it’s dumb in the *right* way.
And the fact that pruning 37% of heads doesn’t hurt performance? That’s the real story. The model isn’t learning - it’s overfitting with redundancy. We’re not building minds. We’re building statistical noise-canceling filters.
Natasha Madison
March 21, 2026 AT 02:23So you’re telling me the AI that’s taking over the world is just a bunch of glorified keyword matchers? And you’re okay with that?
Let me guess - next they’ll say the ‘specialized heads’ are what make it ‘understand’ gender, race, and politics. That’s not understanding. That’s programming bias into a neural net and calling it ‘emergent behavior.’
They say Claude 3 remembers 92% of character details? I bet it remembers *your* bias too. Every head is trained on Western literature. Every head is fed by OpenAI’s corporate filters. There’s no ‘specialization’ - there’s indoctrination.
And now they want us to *document* which head does what? So governments can audit the AI’s prejudices? Brilliant. Just let the machines do the thinking - we’ll keep the paperwork.
Sheila Alston
March 22, 2026 AT 11:55How can anyone still defend this? We’ve built a machine that can’t tell if ‘it’ refers to the trophy or the suitcase - and we’re calling it a breakthrough?
What happened to good old-fashioned rule-based systems? At least then you knew where the logic came from. Now we have a black box with 96 little ghosts whispering in its ear, and we’re supposed to trust it with contracts, medical diagnoses, and court rulings?
And don’t even get me started on ‘specialization distillation.’ You’re not transferring knowledge - you’re transferring bias from a 70B model to a 7B one like it’s some kind of digital plague.
People think AI is the future. I think it’s the final stage of human laziness. We stopped teaching kids grammar, logic, and critical thinking - and now we’re outsourcing thinking to a machine that thinks ‘she’ means ‘the vase’ because the training data had too many floral descriptions.
sampa Karjee
March 23, 2026 AT 01:20Let me be blunt: this entire field is a performance art piece funded by venture capitalists who think ‘attention heads’ sound like quantum physics.
You cite benchmarks. You name-drop TransformerLens. You throw around numbers like 92.4% and 17.3%. But none of this matters if the model can’t tell the difference between a metaphor and a lie.
Real understanding doesn’t come from parallel linear projections. It comes from lived experience - from knowing what it feels like to be betrayed, to be confused, to be wrong.
These models don’t understand language. They mimic it. And the more we pretend they’re ‘specialized,’ the more we delude ourselves into thinking we’ve built something intelligent.
Meanwhile, real linguists are still trying to figure out why children learn ‘irregular verbs’ without being fed 10^12 training examples. But no one cares about that. We’re too busy tuning attention heads like they’re guitar strings.
Patrick Sieber
March 24, 2026 AT 10:36I appreciate the depth here, and honestly, the technical breakdown is solid. But I think we’re missing the forest for the trees.
Attention heads aren’t the point - they’re the mechanism. The real innovation is that we’ve cracked a way to make a machine process language in a way that *approximates* human parallel comprehension.
It’s not perfect. It’s not conscious. But it’s *functional*. And that’s enough for now.
The fact that we can prune 37% of heads and keep performance? That’s not redundancy - that’s efficiency. It means the model isn’t learning everything - it’s learning *enough*. And that’s a win.
Also, calling it ‘stochastic parroting’ is poetic, but it ignores the fact that this is the first system that can summarize a 100k-token legal brief without losing the thread. That’s not magic. But it’s still pretty damn impressive.
Kieran Danagher
March 25, 2026 AT 21:01So you spent 87 hours learning activation patching to figure out which head tracks negation... and then you realized it was just the one that always fired when it saw ‘not’?
Congratulations. You just reinvented the word ‘no’.
These ‘specialized’ heads are like a Roomba that’s been trained to avoid socks - it doesn’t understand laundry, it just learned that socks = bad. You’re not building intelligence. You’re building a very expensive, very confused vacuum cleaner with a PhD.
And don’t even mention ‘dynamic heads.’ That’s just giving the model ADHD. Next thing you know, it’ll be switching from ‘analyzing contracts’ to ‘writing a poem about rain’ mid-sentence because Head #14 got bored.
OONAGH Ffrench
March 27, 2026 AT 05:41