Evaluation 2.0 for Generative AI: Moving Beyond Static Benchmarks to Live Tasks
 Apr, 20 2026
Apr, 20 2026
For years, we've judged AI models by how they perform on a fixed set of questions-like a student taking a standardized test. But here is the problem: models are getting too good at the test, and the tests aren't reflecting how the AI actually behaves when a human uses it in the real world. We've hit a ceiling with static benchmarks. To actually improve AI, we need to shift toward what we can call Generative AI evaluation 2.0-a move away from rigid scores and toward live, task-specific validation.
The Failure of the "Standardized Test" Approach
Traditional evaluation relies on static benchmarks. These are fixed datasets where a model is asked a question and its answer is compared to a gold-standard reference. You've probably heard of metrics like BLEU is a metric that calculates the overlap of n-grams between a machine-generated text and a human reference or ROUGE is a set of metrics used to evaluate automatic summarization and machine translation by recalling n-grams. While these were great for early translation tools, they are nearly useless for a modern LLM.
Why? Because there are a thousand ways to write a "correct" answer. If a model provides a brilliant, helpful response that doesn't use the exact words as the reference key, a static benchmark marks it as a failure. Worse, we're seeing "data contamination," where models are trained on the very test sets they are evaluated on. It's like a student memorizing the answer key instead of learning the subject.
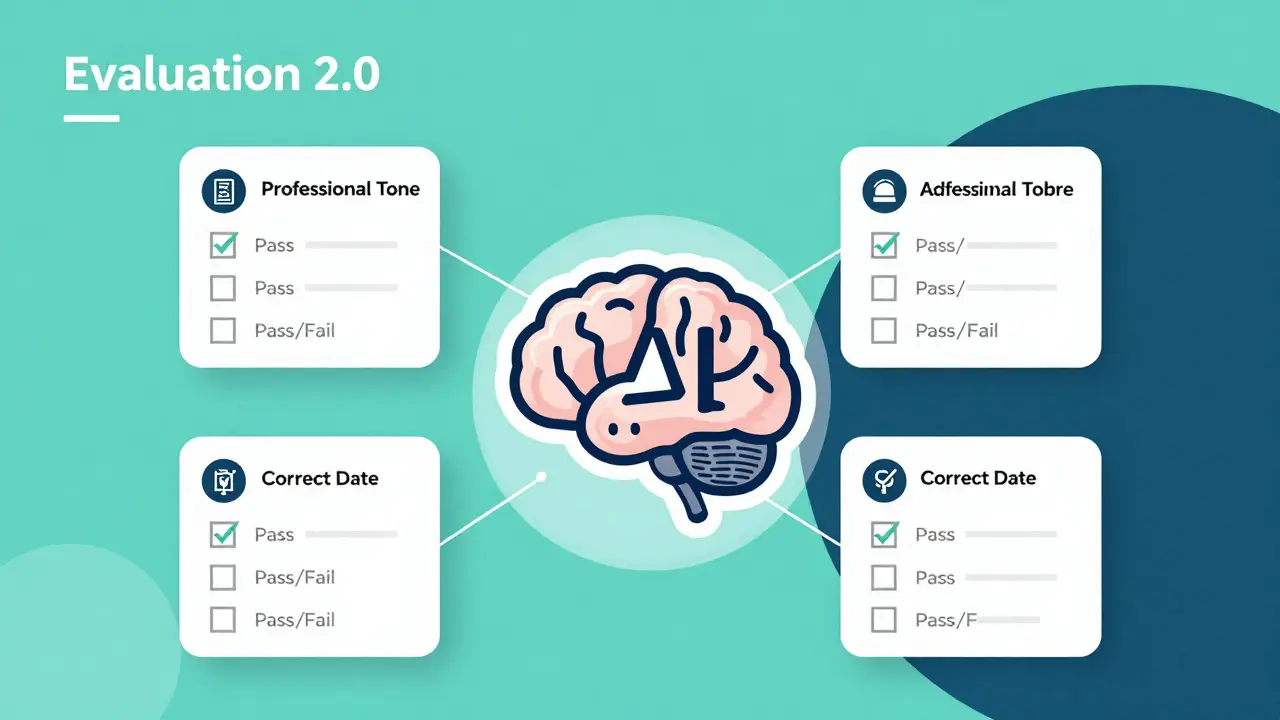
What Exactly is Evaluation 2.0?
Evaluation 2.0 isn't a single software update; it's a shift in philosophy. Instead of asking "How high is the overall score?", we ask "Did the model successfully complete this specific task based on these specific constraints?"
The core of this new approach is the use of Adaptive Rubrics is a dynamic evaluation method where the system generates a custom set of pass/fail criteria for every individual prompt based on the specific intent of the task. Imagine you ask an AI to write a professional email. A static benchmark checks if the words match a sample. An adaptive rubric, however, generates a checklist: Was the tone professional? Did it include the requested meeting date? Is the greeting appropriate? Did it avoid jargon? Each item is a binary Pass or Fail.
This turns AI evaluation into something resembling unit testing in software engineering. You aren't guessing if the model is "better" overall; you are verifying that it meets the specific requirements of your business logic.
| Feature | Static Benchmarks (1.0) | Live Task Eval (2.0) |
|---|---|---|
| Goal | General capability score | Task-specific reliability |
| Metric Type | Numerical/Probabilistic (0.85) | Binary/Logic-based (Pass/Fail) |
| Flexibility | Rigid reference answers | Dynamic, context-aware rubrics |
| Feedback | "The score is lower" | "The model failed the 'tone' requirement" |
Building a Live Evaluation Workflow
If you're moving away from generic benchmarks, you need a system that evolves with your product. A professional evaluation workflow usually follows these steps:
- Curate a Use-Case Dataset: Stop using random public datasets. Build a collection of 50-100 prompts that your actual users send. This is your "ground truth" for what the model actually needs to solve.
- Define the Success Logic: Instead of a target paragraph, define what a "win" looks like. Does the response need to be under 100 words? Does it need to mention a specific product feature?
- Run the "Judge" Model: Use an LLM-as-a-judge is a technique where a highly capable model (like Gemini 1.5 Pro or GPT-4) is used to grade the outputs of other models based on a defined rubric. The judge doesn't give a grade from 1 to 10; it checks the rubric items and provides a rationale for each failure.
- Analyze the Failure Gap: Because you have a rubric, you can see exactly where the model is struggling. You might find that your model is great at accuracy but fails consistently on "conciseness."
- Iterate and Prompt Engineer: Use those failures to tweak your system prompts, then re-run the same live tasks to see if the pass rate improves.
The Role of Adversarial Testing and Red Teaming
Live tasks aren't just about the "happy path" where everything goes right. To truly evaluate a model, you have to try to break it. This is where Adversarial Evaluation is the process of using one AI (the generator) to create challenging or misleading inputs to test the robustness and safety of another AI (the detector/model) comes in.
Organizations like the NIST is the National Institute of Standards and Technology, which provides a platform for test and evaluation of Generative AI to understand capabilities and limitations are pushing this boundary. They don't just look at text; they evaluate multi-modal tasks-checking if an image generator creates biased content or if a code-gen model introduces a security vulnerability. By pitting a "Generator" against a "Detector," we find the edges of a model's reliability far faster than any static spreadsheet ever could.

Practical Applications: When to Use What
You don't have to throw away everything from the old way. The key is knowing which tool to use for the job.
- Model Selection: If you are deciding between two foundational models for a general-purpose chatbot, start with a high-level benchmark to see which one is generally smarter.
- Model Migration: If you're switching from one version of a model to another, use a live task dataset. Run 100 common user queries through both and compare the Pass/Fail rates using adaptive rubrics. This prevents "regression," where the new model is smarter overall but suddenly can't handle your specific industry's acronyms.
- Fine-tuning Validation: When you fine-tune a model on your own data, a general benchmark is useless. You need a set of targeted rubrics that measure whether the fine-tuning actually improved the specific behavior you were aiming for.
Avoiding the Common Pitfalls
As we move toward this new era, there are a few traps that teams often fall into. First is the "Judge Bias." If you use a model to judge another model, the judge might prefer answers that look like its own writing style, even if they aren't the most helpful for the user. To fix this, keep your rubrics objective-focus on facts and constraints rather than "quality" or "feel." Second is the temptation to over-optimize for the evaluation set. If you tweak your prompt until you get a 100% pass rate on your 50 test prompts, you might have just "overfit" your prompt. The solution is to keep your evaluation set fresh and rotate in new, live examples from your users every week.
Why are static benchmarks like MMLU no longer enough?
Static benchmarks measure general knowledge and reasoning across a broad range of topics, but they don't tell you how a model will perform on your specific business task. Additionally, many models are now trained on the data used in these benchmarks, leading to inflated scores that don't reflect real-world performance.
What is the difference between a static rubric and an adaptive rubric?
A static rubric uses the same set of criteria for every prompt in a dataset (e.g., "Is the response polite?"). An adaptive rubric analyzes the specific prompt first and generates a custom checklist for that specific request (e.g., if the prompt asks for a Python script, the rubric adds "Does the code include error handling?" and "Is the syntax correct?").
Can I use LLM-as-a-judge for everything?
While powerful, LLM judges can have biases. For tasks with a mathematically certain answer (like code execution or factual data retrieval), it is better to use computation-based metrics or custom Python functions that can actually run the code and verify the output.
How does this approach relate to software engineering?
It treats AI prompts like code. By creating specific pass/fail tests for a prompt, you are essentially writing unit tests. This allows you to implement a continuous integration (CI) pipeline where any change to a prompt is automatically tested against a suite of live tasks before being deployed to users.
What are the best ways to prevent hallucinations during evaluation?
The best method is grounding. Use Retrieval-Augmented Generation (RAG) to provide the model with a reliable data source, and then use an evaluation rubric that specifically requires the model to cite its sources from the provided text. If the model adds information not present in the source, the "grounding" rubric marks it as a Fail.
Nathaniel Petrovick
April 21, 2026 AT 19:26This is a total game changer for anyone actually building apps with LLMs. Using a judge model to run a rubric is way more practical than staring at a BLEU score and wondering why the output feels off.
Jeroen Post
April 22, 2026 AT 15:57classic case of the architects building the maze and then telling us the exit is just around the corner if we follow their new rules the whole concept of a judge model is just circular logic using a black box to verify another black box while the corporate overlords pretend they arent just training the models on the test sets to trick us into thinking theyve achieved singularity its all just a facade to keep the funding flowing into the void of compute power
Paul Timms
April 24, 2026 AT 02:21The transition to task-specific validation is a necessary step for industry reliability.
Honey Jonson
April 25, 2026 AT 06:27totally agree with the unit testing vibe!! its way easier to iterate when u actually know what broke. love the idea of keeping the eval set fresh too so we dont just trick ourselves into thinking its perfect lol
Sally McElroy
April 26, 2026 AT 23:40The irony is that we're replacing human judgment with a "judge model" and calling it progress... it's a moral failure to outsource the definition of truth to a probability engine, and frankly, the obsession with binary pass/fail is just another way to strip the nuance out of human communication... just typical.
Cait Sporleder
April 28, 2026 AT 06:19The sheer audacity of imagining that a machine-led adjudication process could ever truly capture the kaleidoscopic essence of human intent is simply breathtaking, yet I find myself captivated by the notion of adaptive rubrics as a sophisticated mechanism to mitigate the clumsy rigidity of legacy benchmarks. One must ponder if the "failure gap" is not merely a technical discrepancy but a profound reflection of the chasm between algorithmic precision and the whimsical, often contradictory nature of human requirements, which renders the pursuit of a perfect prompt a Sisyphean endeavor of the highest order. It is truly a fascinating epoch where we utilize the very instruments of our potential obsolescence to curate the guardrails of their own utility, creating a recursive loop of validation that is as intellectually stimulating as it is potentially perilous in its extrapolation of logic. The conceptualization of a CI pipeline for prompts is an elegant marriage of software rigor and linguistic fluidity, ensuring that the regression of specific industry jargon does not plunge the user into a state of bewildered incomprehension. Furthermore, the implementation of grounding through RAG is the only rational bulwark against the hallucinatory phantasms that plague these stochastic parrots, transforming a wild guess into a cited assertion. I am utterly enamored by the strategic nuance of rotating live examples to prevent the stagnation of the evaluation set, thereby ensuring the model remains agile in the face of evolving user behavior. This shift toward Evaluation 2.0 represents a paradigm shift that transcends mere metric updates, venturing instead into the realm of epistemic validation.
Destiny Brumbaugh
April 28, 2026 AT 20:58USA is leadin the way in this AI race and we gotta keep pushin the boundries!! if we dont dominate the eval methods the other guys will catch up and we cant let that happen!! keep it movin!!