How Embeddings Capture Meaning in Generative AI: A Practical Guide
 May, 29 2026
May, 29 2026
Imagine trying to explain the concept of "love" to a computer using only numbers. It sounds impossible, right? Yet, this is exactly what embeddings are mathematical representations that convert complex data like text, images, or audio into numerical vectors that machines can process and understand do every second. They are the invisible bridge between human meaning and machine logic. Without them, large language models (LLMs) would just be sophisticated autocorrect tools, unable to grasp context, nuance, or intent.
If you are building applications with generative AI in 2026, understanding embeddings is no longer optional-it is foundational. You don't need to be a mathematician to use them, but you do need to know how they work, where they fail, and how to choose the right ones for your specific job. This guide breaks down the mechanics of representation learning so you can build smarter, more accurate AI systems.
What Are Embeddings and Why Do They Matter?
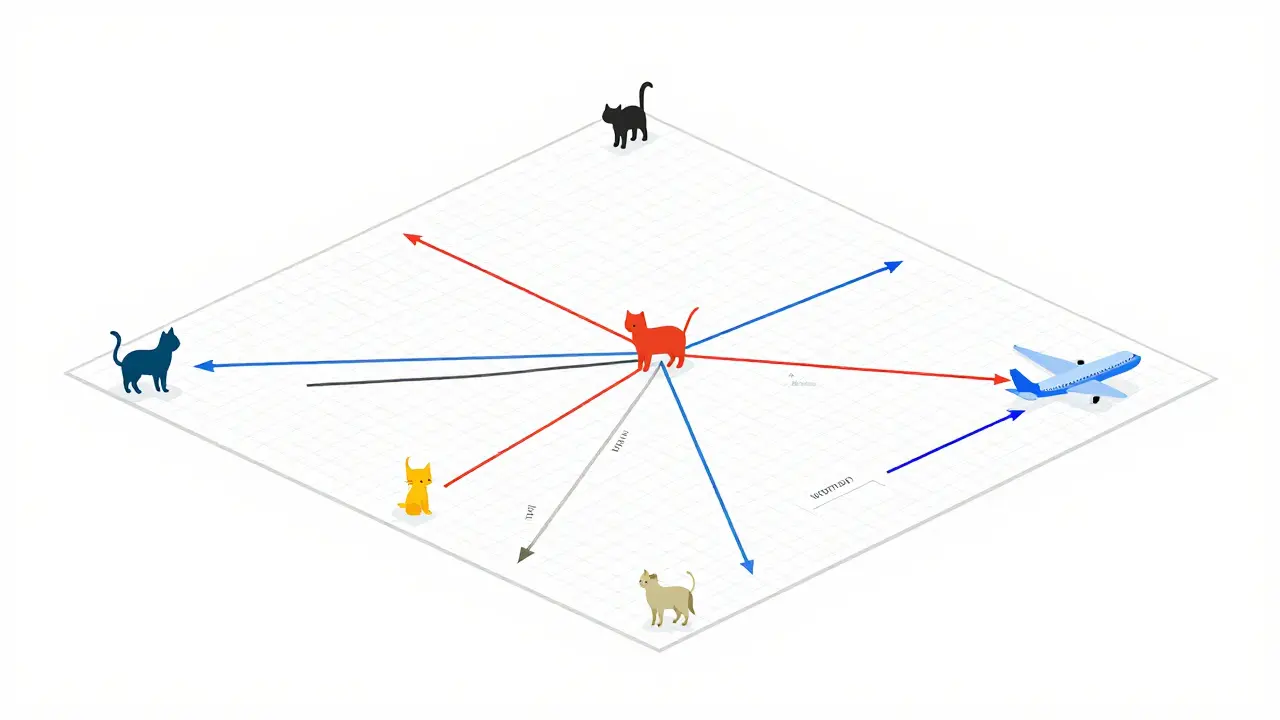
At their core, embeddings are a way to map real-world objects into a high-dimensional space. Think of it as a giant coordinate system. In this space, similar items sit close together, while unrelated items are far apart. If you have an embedding for "cat" and one for "kitten," their coordinates will be nearly identical. The embedding for "airplane" will be miles away.
This proximity isn't random. It captures semantic relationships. When a model processes the sentence "The king is to queen as man is to ___," it doesn't look up a dictionary. It performs a vector calculation. It finds the direction from "man" to "woman" and applies that same shift to "king," landing near "queen." This ability to capture structure and meaning allows AI to generate relevant outputs rather than just predicting the next most common word.
Historically, feature engineering was a manual grind. Data scientists spent weeks crafting rules to describe data. Today, deep neural networks automate this. The internal layers of these networks produce embeddings that reveal high-level concepts automatically. This shift has turned unstructured data-messy text, noisy audio, varied images-into clean, searchable numerical formats.
The Mechanics: From Raw Data to Vector Space
How does a string of characters become a list of floating-point numbers? The process starts with a feature extractor is a component of a neural network that processes input data to create a numerical representation. For text, this is often a transformer-based model. For images, it might be a convolutional neural network.
Here is the step-by-step flow:
- Input Processing: The raw data (e.g., a paragraph of text) is tokenized. Words are broken down into smaller units the model understands.
- Dimensionality Mapping: Each token is mapped to a vector. Modern models use thousands of dimensions. While we can't visualize 1,536 dimensions, the math holds up: closer distances mean higher similarity.
- Semantic Compression: The model compresses the essence of the input into these vectors. Research shows that the actual signal often occupies a relatively low-dimensional subspace within the larger ambient space. This means much of the high-dimensional room is empty or noise, which is crucial for understanding why some generated data drifts from reality.
- Output Generation: These vectors are passed through subsequent processing layers to generate responses, retrieve information, or classify data.
The key insight here is that the embedding space preserves the structure of the original dataset. If your training data has biases, those biases get baked into the geometry of the vector space. Samples from different sources-even if they look identical to humans-can embed into separable subspaces. For example, cat images from two different public datasets might cluster separately because of subtle differences in lighting or camera angles during collection.
Generative Embeddings vs. Traditional Approaches
Not all embeddings are created equal. Traditional methods like Word2Vec or GloVe were static. The word "bank" had the same vector whether it referred to a river or a financial institution. That limitation killed contextual accuracy.
Modern generative AI relies on dynamic, context-aware embeddings. Techniques like Sentence-BERT (SBERT) is a fine-tuned version of BERT designed to generate high-quality embeddings for entire sentences, capturing semantic meaning essential for retrieval tasks revolutionized this by focusing on sentence-level semantics. But the frontier now involves generative embeddings are vector representations learned using generative models like VAEs or GANs that preserve complex structures and allow for the generation of new data.
Generative embeddings use models like Variational Autoencoders (VAEs) or Generative Adversarial Networks (GANs) to learn a latent representation. This latent space is semantically rich and adaptable. Instead of just retrieving existing data, these embeddings can be manipulated to generate new data points. If you have an embedding for a "red car," you can nudge the vector slightly to generate an image or description of a "blue car" without ever having seen that specific combination before.
| Feature | Static Embeddings (Word2Vec) | Contextual Embeddings (BERT/SBERT) | Generative Embeddings (VAE/GAN) |
|---|---|---|---|
| Context Awareness | No (fixed per word) | Yes (varies by sentence) | Yes (latent space modeling) |
| Primary Use Case | Basic NLP tasks | Semantic search, RAG | Data generation, synthesis |
| Flexibility | Low | High | Very High |
| Complexity | Simple | Moderate | High |
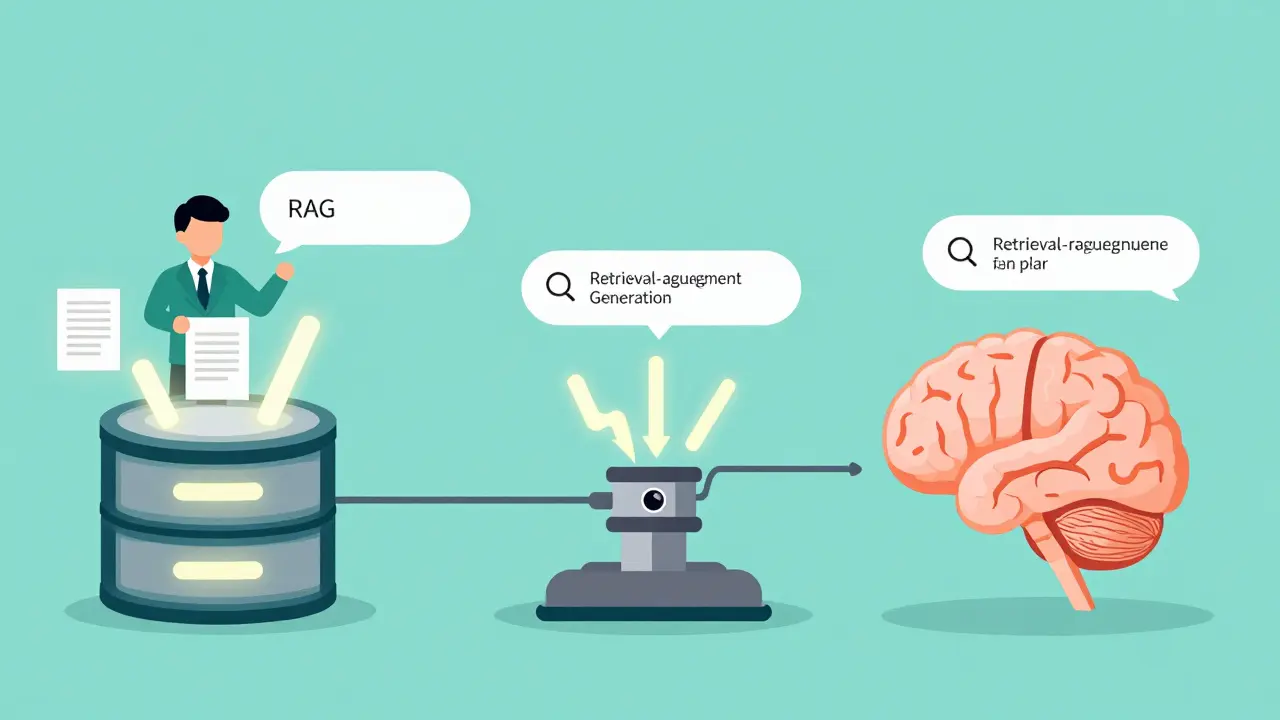
Embeddings in Retrieval-Augmented Generation (RAG)
You cannot talk about embeddings in 2026 without discussing Retrieval-Augmented Generation (RAG) is an architecture that combines large language models with external knowledge bases, using embeddings to retrieve relevant documents before generating a response. RAG solves the hallucination problem by grounding the AI's answers in factual data.
Here is how it works in practice:
- Indexing: Your company's documentation, PDFs, and databases are chunked and converted into embeddings using a specific model. These vectors are stored in a vector database is a specialized database optimized for storing and searching high-dimensional vector embeddings at high speed like Pinecone, Milvus, or Weaviate.
- Querying: When a user asks a question, the same embedding model converts that query into a vector.
- Similarity Search: The vector database finds the closest matching embeddings (documents) based on distance metrics like cosine similarity.
- Generation: The retrieved documents are fed into the LLM along with the user's prompt to generate a grounded answer.
There is a critical rule in RAG: consistency is king. You must use the exact same embedding model for indexing and querying. If you index with Model A and query with Model B, the vector spaces won't align, and your retrieval accuracy will plummet. Unstructured.io recommends sticking to established models like sentence-transformers/all-MiniLM-L6-v2 for general purposes. It’s fast, efficient, and widely supported. Switching models mid-project introduces unpredictable behavior, especially in regulated fields like healthcare or finance where reproducibility is non-negotiable.
Also, avoid fine-tuning your embedding model for specific tasks within a RAG pipeline unless you have a massive, high-quality dataset. Fine-tuning can lead to inconsistencies and poor generalization. Stick to pre-trained models that have already learned robust semantic relationships across diverse domains.
Detecting Bias and "Generative DNA"
Embeddings are not neutral mirrors; they are interpretations shaped by their training data. Research from the National Center for Biotechnology Information highlights a fascinating phenomenon called generative DNA (gDNA). Every generative model learns its own distinct representation based on its training corpus and procedures. These choices leave a watermark in the embedding space.
Why does this matter to you? Two reasons:
1. Deepfake Detection: Because generative models encode specific patterns, embeddings can distinguish between real samples and AI-generated ones without additional training. The intrinsic separability between real and fake data exists in the vector space. Simple dimensionality reduction techniques like Principal Component Analysis (PCA) can uncover this heterogeneity, making embeddings a powerful tool for content authenticity verification.
2. Dataset Bias: As mentioned earlier, sampling techniques influence embeddings. If your training data over-represents certain demographics or sources, the embedding space will reflect that bias. Visualizing these spaces using tools like t-SNE or UMAP helps researchers identify clusters, outliers, and anomalies. This exploratory data analysis is vital for quality assurance. If you see a cluster of "doctor" embeddings heavily skewed toward one gender, you know your underlying data needs correction before you even touch the generation layer.
Practical Tips for Implementing Embeddings
Building with embeddings requires attention to detail. Here are actionable heuristics to improve your system's performance:
- Choose Dimensionality Wisely: Higher dimensions capture more nuance but cost more in storage and compute. Models like MiniLM use 384 dimensions and offer a great balance of speed and accuracy for most RAG tasks. Larger models like E5-mistral may use 1,024+ dimensions for complex reasoning but require more resources.
- Chunk Strategically: Don't just split documents by character count. Split by semantic boundaries-paragraphs, sections, or headers. An embedding of a half-sentence loses meaning. Context windows matter.
- Monitor Drift: If your source data changes significantly over time, your indexed embeddings may become stale. Re-index regularly. The "noise" in extraneous dimensions can cause generated data to drift from current realities if the base representation is outdated.
- Use Hybrid Search: Pure vector search is powerful, but combining it with keyword search (BM25) often yields better results. Keywords catch exact matches (like product IDs), while vectors catch semantic intent.
Conclusion
Embeddings are the silent engine of modern generative AI. They transform chaos into order, allowing machines to navigate the vast landscape of human knowledge. By understanding how they capture meaning, how they interact with RAG systems, and how to detect their inherent biases, you move from being a passive user of AI tools to an active architect of intelligent solutions. Start with consistent models, visualize your data, and always remember: the quality of your output is directly tied to the quality of your representations.
What is the best embedding model for RAG in 2026?
For most general-purpose RAG applications, sentence-transformers/all-MiniLM-L6-v2 remains a top choice due to its balance of speed, low dimensionality (384), and strong semantic performance. For more complex, nuanced queries requiring deeper understanding, models like E5-large-v2 or newer Mistral-based embeddings offer higher accuracy at the cost of increased computational resources. Always test multiple models against your specific dataset to determine the best fit.
Can embeddings be used for images and audio, not just text?
Yes. Embeddings are modality-agnostic. Image embeddings (often created via CLIP or ResNet models) map visual features into vector space, enabling image search and classification. Audio embeddings capture spectral and temporal features, useful for speech recognition and music recommendation. Cross-modal embeddings even allow you to search for images using text queries by mapping both modalities into a shared vector space.
Why is consistency important when choosing an embedding model?
Consistency ensures that the vector space used to index your data matches the space used to query it. Different models create different geometries. If you index documents with Model A and query with Model B, the relative distances between vectors will not align, leading to poor retrieval accuracy. Sticking to one model throughout your pipeline prevents this misalignment and ensures reproducible results.
How do I visualize my embedding space to check for bias?
You can use dimensionality reduction techniques like t-SNE (t-Distributed Stochastic Neighbor Embedding) or UMAP (Uniform Manifold Approximation and Projection). These algorithms project high-dimensional vectors into 2D or 3D space for visualization. By coloring points based on metadata (e.g., gender, source, topic), you can visually inspect clusters for unexpected segregation or bias, helping you identify issues in your training data before deployment.
What is "generative DNA" in the context of embeddings?
Generative DNA refers to the unique signature or watermark left by a specific generative model's training process and architecture in its embedding space. Because each model learns distinct representations from its specific training corpus, the resulting embeddings contain subtle patterns that can distinguish AI-generated content from real data. This property is increasingly used for deepfake detection and content provenance tracking.
Jeff Napier
May 30, 2026 AT 17:30you think embeddings are just math? nah. theyre the digital fingerprints of our collective subconscious being mined by silicon overlords. every time you search for something youre feeding the beast more data about what it means to be human so it can replace us with a perfect hollow shell that knows exactly how to manipulate your dopamine receptors. its not technology its colonization of meaning itself and we are all willing participants in our own obsolescence because we cant stop clicking
Sibusiso Ernest Masilela
May 31, 2026 AT 09:13absolute garbage take. the author clearly has no idea what hes talking about if he thinks static embeddings are still relevant in any serious application. anyone using word2vec in 2026 is basically committing professional suicide. you need contextual awareness or you are building on sand. wake up sheeple
Daniel Kennedy
May 31, 2026 AT 18:35look i get the frustration but lets keep it civil here. the point about consistency in RAG pipelines is actually super important and often overlooked by junior devs who just want to plug in the shiniest new model without testing. please read the section on hybrid search again because combining BM25 with vector search is literally the only way to get decent results for exact keyword matches like product IDs. dont ignore the basics just to chase hype cycles
Taylor Hayes
June 1, 2026 AT 20:46i really appreciate this guide. it feels like finally someone is explaining the why instead of just dumping code snippets on us. the part about generative dna was fascinating. makes me wonder how long until we have standardized watermarking protocols built directly into the embedding layers themselves rather than relying on post-processing detection tools
Sanjay Mittal
June 3, 2026 AT 07:22great overview. one thing to add regarding chunking strategies: semantic chunking based on sentence boundaries works well for general text but for legal or medical documents you might want to try recursive character splitting with overlap to ensure context isn't lost at the edges. also consider using metadata filters alongside vector similarity to narrow down the search space before even hitting the LLM which saves tokens and improves accuracy significantly
Mike Zhong
June 3, 2026 AT 17:58the entire premise is flawed. you cannot reduce human consciousness to vectors. it is a category error. these models mimic understanding but they feel nothing. they know the shape of love but not the weight of loss. we are building sophisticated parrots and calling them gods. dangerous delusion