How Human Feedback Loops Fix RAG Relevance Over Time
 Jun, 27 2026
Jun, 27 2026
Your Retrieval-Augmented Generation (RAG) system looked perfect in testing. But three months into production, users are complaining. The answers feel stale. The retrieved documents miss the mark. You’re not alone. According to Label Studio’s 2024 analysis, roughly 67% of RAG failures stem from poor retrieval quality that static systems just can’t fix on their own.
The problem isn’t your vector database or your LLM choice. It’s that traditional RAG is a one-way street: it retrieves data once and never learns from what actually helped (or hurt) the user experience. To stop this degradation, you need Human Feedback Loops (mechanisms that incorporate user interactions and structured human review to continuously optimize retrieval quality). These loops turn your RAG pipeline from a static archive into a living, self-improving system.
Why Static RAG Fails in Production
When you first deploy a RAG system, you rely on semantic similarity. Your embedding model matches user queries to document chunks based on mathematical distance in vector space. This works well for exact matches but falls apart when context matters. A query about "interest rates" might retrieve general economic theory instead of last week’s central bank announcement because the semantic weight of "theory" is higher than the temporal urgency of "news."
Without feedback, this error repeats forever. Every time a user asks about interest rates, they get the same generic answer. Over time, trust erodes. Users stop using the tool, or worse, they make decisions based on outdated information. Research from the Pistis-RAG framework (Crossing Minds, July 2024) shows that standard RAG systems without feedback mechanisms lag significantly behind those with human-in-the-loop adjustments, particularly in dynamic knowledge domains like finance or healthcare where facts change weekly.
How Human Feedback Loops Work
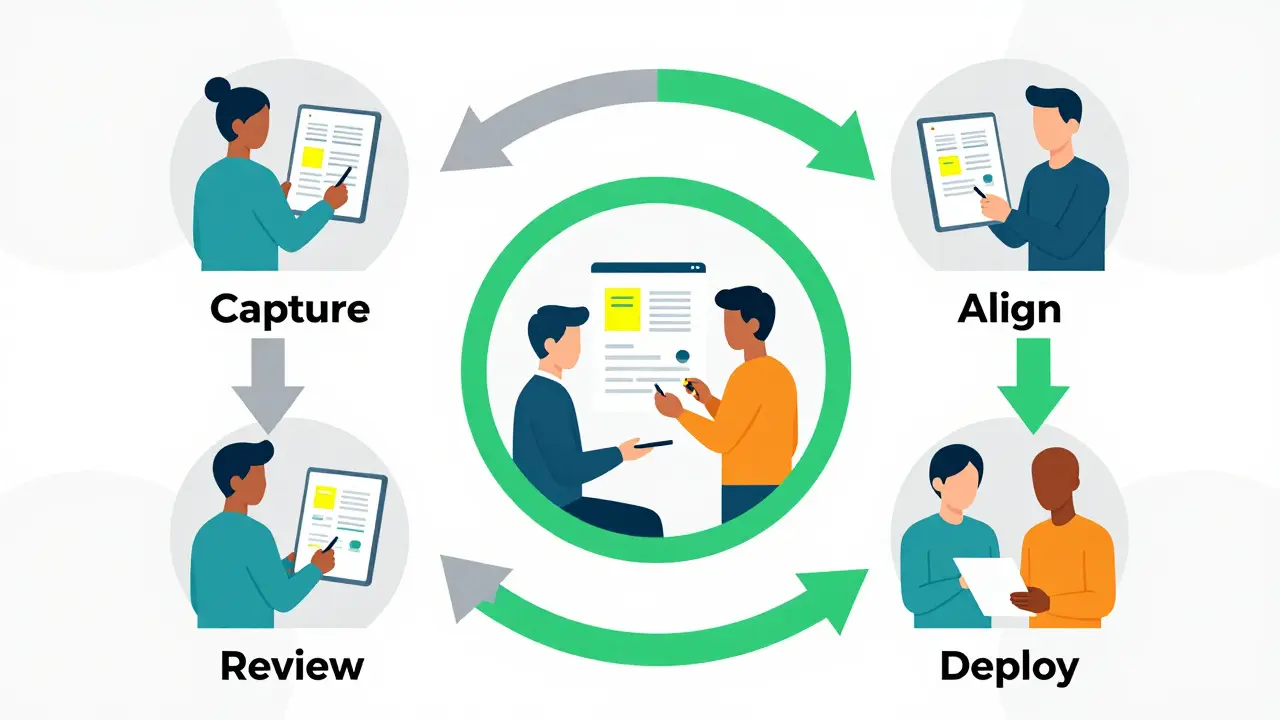
A human feedback loop doesn’t just mean asking users "Was this helpful?" That binary thumbs-up/down is too vague. Effective loops capture specific signals about why an answer succeeded or failed. Here is the typical workflow:
- Capture: When a user interacts with the RAG system, log the query, the generated response, the retrieved source documents, and any explicit user actions (clicks, edits, corrections).
- Review: A subset of these interactions goes to human reviewers. They don’t just rate the final answer; they evaluate the relevance of the retrieved chunks. Did the system pull the right evidence?
- Align: Use this labeled data to fine-tune your ranking model. This is often called "feedback alignment." The model learns that certain semantic patterns correlate with higher human satisfaction.
- Deploy: Update the retrieval weights in real-time or via nightly batches. The next similar query gets better results immediately.
The key innovation here is List-Wide Feedback Alignment (a method that processes user feedback across entire lists of retrieved documents rather than assessing individual documents in isolation). Instead of judging each document chunk separately, the system learns how the order and combination of multiple sources affect the final output. This mirrors how humans actually read-we synthesize information from several paragraphs, not just one sentence.
The Pistis-RAG Framework: A Case Study
To understand the impact, look at the Pistis-RAG (an open-source framework developed by Crossing Minds for optimizing RAG systems through human feedback) framework. In their July 2024 study, researchers trained their model on over 15,000 human-labeled query-response pairs from datasets like MMLU and C-EVAL.
| Metric | Standard RAG | Pistis-RAG (with Feedback) | Improvement |
|---|---|---|---|
| MMLU Accuracy (English) | 57.36% | 63.42% | +6.06% |
| C-EVAL Accuracy (Chinese) | 61.13% | 68.21% | +7.08% |
| Convergence Speed vs. RLHF | N/A | 18.3% faster | Faster Optimization |
This isn’t just a lab experiment. Dr. Jane Chen, Director of AI Research at Crossing Minds, noted in March 2025 that treating RAG as a dynamic optimization process fundamentally changes reliability. By closing the gap between pre-trained knowledge and real-world application needs, these systems adapt to new jargon, emerging trends, and shifting user intent.
Implementation Challenges and Pitfalls
If it sounds great, why isn’t everyone doing it? Because it’s hard. Braintrust’s 2025 industry survey found that implementing feedback loops requires about 35% more engineering resources upfront. You aren’t just building a chatbot; you’re building a data pipeline for continuous learning.
Here are the biggest hurdles you will face:
- Feedback Fatigue: If you ask every user to review every answer, they will quit. Google Cloud recommends using "opinionated tiger teams"-small groups of power users who provide high-quality, structured feedback. This reduces noise and keeps the signal strong.
- Bias Amplification: Dr. Emily Zhang from Stanford warned in June 2025 that implicit feedback can amplify existing biases. If your primary users are senior engineers, the system might learn to favor technical jargon over plain language, alienating junior staff. You need diverse reviewer personas to prevent this drift.
- Latency Constraints: Real-time adaptation must happen fast. Google Cloud’s 2025 guide specifies under 200ms latency for feedback processing to maintain user experience. Slow updates mean the system feels broken until the next batch job runs.
- Complexity in Setup: Only 32% of organizations successfully implement the necessary infrastructure, according to Forrester’s October 2025 report. Many teams struggle with aligning automated metrics (like contextual precision) with human judgment.
A GitHub issue on the Pistis-RAG repository highlighted a critical risk: improper feedback weighting. One team saw retrieval quality drop by 18.2% after launching their loop because they gave too much weight to recent, noisy feedback signals. Always start with conservative update rates and monitor performance closely.
Tools and Infrastructure for 2026
You don’t have to build everything from scratch. Several tools now support human-in-the-loop workflows out of the box. As of late 2025, the market leaders include:
- Label Studio: Popular for its flexible annotation interface. Their November 2025 update introduced automated feedback categorization, reducing human review time by 38%.
- Confident AI: Focuses on evaluation metrics. They specify that contextual precision should exceed 0.85 for optimal feedback integration. Their case studies show a 42% reduction in false positive errors compared to metric-only approaches.
- Braintrust: Offers robust tracking and comparison features for LLM applications, helping teams visualize how feedback impacts accuracy over time.
- Vertex AI (Google Cloud): Integrated real-time feedback mechanisms in December 2025, cutting processing latency to under 150ms.
For most teams, starting with Label Studio or Confident AI provides the best balance of ease-of-use and control. Stack Overflow’s 2025 developer survey showed that 78% of successful implementations used vector database operations combined with these evaluation frameworks.

Regulatory Drivers: Why Compliance Pushes Adoption
Beyond accuracy, regulation is forcing companies to adopt human oversight. The EU’s 2025 AI Act mandates documented human oversight mechanisms for high-risk RAG applications in finance and healthcare. Deloitte’s November 2025 compliance analysis estimates this requirement accelerated adoption in regulated sectors by 34%.
In healthcare, for example, a Confident AI case study from October 2025 documented a client achieving a 31.4% reduction in clinically inaccurate responses after implementing structured human review. Medical reviewers spent an average of 47 seconds per response, providing feedback that improved subsequent queries. This isn’t just about better UX; it’s about patient safety and legal liability.
Future Outlook: What’s Next for RAG Feedback?
The technology is moving fast. Gartner predicts that 75% of enterprise RAG systems will incorporate human feedback loops by 2027, up from 28% in late 2025. We are seeing a shift from manual review to semi-automated assistance.
Look out for these developments in 2026:
- Multimodal Feedback: Crossing Minds plans to release Pistis-RAG 2.0 in Q2 2026, supporting feedback on images and audio, not just text.
- Context-Aware Weighting: Confident AI is launching algorithms that automatically adjust the importance of feedback based on user expertise and query complexity.
- Standardized Protocols: The RAGBench consortium aims to publish standardized evaluation protocols for feedback loops in March 2026, making it easier to compare tools objectively.
The goal is clear: move from reactive fixes to proactive improvement. Your RAG system should get smarter every day, not dumber. By integrating human feedback loops, you ensure that your AI stays relevant, accurate, and trusted by the people who rely on it.
What is the difference between RLHF and Human Feedback Loops for RAG?
Reinforcement Learning with Human Feedback (RLHF) is typically used to align the base Large Language Model (LLM) itself, teaching it general behavior and tone. Human Feedback Loops for RAG specifically target the retrieval component. They teach the system which documents are most relevant for specific queries. While RLHF adjusts the generator, RAG feedback loops adjust the retriever. Studies show RAG-specific loops converge 18.3% faster than full RLHF approaches because the scope is narrower and more focused on factual grounding.
How much does it cost to implement a human feedback loop?
The cost varies, but expect a 35% increase in initial engineering resources for setup, according to Braintrust's 2025 survey. Ongoing costs depend on your review strategy. Using a small "tiger team" of internal experts is cheaper than crowdsourcing but requires careful management to avoid bias. Tools like Label Studio and Confident AI reduce development time, but you still need to budget for reviewer time and infrastructure maintenance.
Can I use automated metrics instead of human feedback?
Automated metrics like Ragas or DeepEval are useful for baseline monitoring, but they lack nuance. Label Studio’s 2024 case studies found that human feedback reduces false positive error identification by 42% compared to metric-only approaches. Automated metrics can tell you if a response is coherent, but only humans can judge if it’s truly helpful or contextually appropriate. Best practice is to use automated metrics for filtering and human review for training.
Is human feedback required by law?
In certain sectors, yes. The EU’s 2025 AI Act requires documented human oversight for high-risk applications in finance and healthcare. While not all industries have such strict laws, regulatory pressure is increasing globally. Implementing feedback loops now positions your company for future compliance and demonstrates due diligence in managing AI risks.
How do I prevent bias in my feedback loop?
Bias occurs when your feedback comes from a narrow group of users. Stanford’s Dr. Emily Zhang warns that this can amplify existing prejudices. To mitigate this, use diverse reviewer personas. Include both technical and non-technical users, and ensure your review team represents different demographics and expertise levels. Regularly audit your feedback data for skew, and adjust your sampling strategy to include underrepresented user segments.