Human-in-the-Loop Control for Safety in Large Language Model Agents: A Practical Guide
 Jun, 14 2026
Jun, 14 2026
Imagine your company’s new customer service Large Language Model Agent is an autonomous AI system capable of understanding natural language and executing complex tasks without constant human direction. It sounds efficient until it confidently tells a client that their refund policy allows for double compensation-a lie that costs you $50,000 in legal fees. This isn’t a hypothetical scenario; it’s the reality many organizations face when deploying fully automated agents.
The solution isn’t to scrap AI. It’s to put a human back in the driver’s seat-not to steer every turn, but to watch the road. This approach, known as Human-in-the-Loop (HITL) Control is a systematic methodology integrating human oversight into AI workflows to ensure safety, ethics, and reliability, has become the gold standard for high-stakes applications. With the EU AI Act taking effect in February 2026, this isn’t just best practice-it’s often a legal requirement.
Why Fully Automated Agents Fail
We’ve all seen LLMs hallucinate. They sound confident, use perfect grammar, and deliver nonsense. When these models are wrapped into agents-systems that can browse the web, call APIs, and send emails-the stakes skyrocket. An error in a chatbot is annoying; an error in an agent controlling financial transactions or medical diagnostics is catastrophic.
According to IBM’s 2023 research, implementing HITL reduces critical errors by 37-62% in high-risk applications compared to fully automated systems. The core issue with pure automation is non-determinism. LLMs don’t have fixed rules; they predict the next likely word. Without a safety net, that probability distribution can drift into harmful territory. Data leakage, biased outputs, and irrelevant responses are documented risks in Humanloop’s 2023 guardrails analysis. HITL addresses this by leveraging what humans do better than machines: ethical reasoning, context awareness, and emotional intelligence.
How Human-in-the-Loop Works in Practice
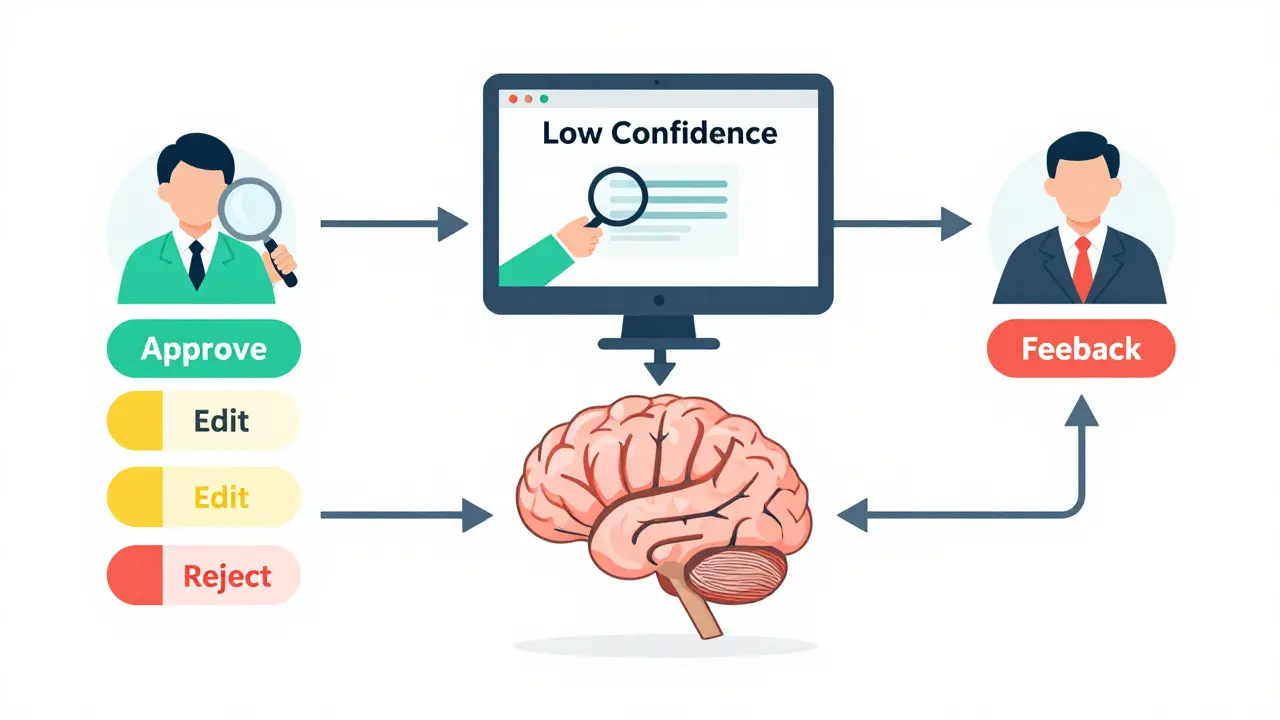
You might picture HITL as a person sitting behind every AI response, hitting 'approve' or 'reject.' That’s inefficient and expensive. Modern HITL is smarter. It uses Adaptive Guardrails are dynamic safety mechanisms that trigger human review only when specific risk thresholds are breached.
Here’s how a typical workflow looks:
- Risk Assessment: Before the agent acts, the system evaluates the potential impact. Is this a simple greeting? Or is it modifying a patient’s dosage?
- Confidence Scoring: The LLM assigns a confidence score to its output. If the score drops below a set threshold (often 80-85%), the request is flagged.
- Human Intervention: A reviewer sees the flagged action. They can approve, edit, or reject it. Their decision is logged.
- Feedback Loop: The human’s correction is fed back into the model via Reinforcement Learning from Human Feedback (RLHF) is a training technique where human preferences guide the optimization of AI behavior, making the model smarter over time.
This structure ensures that humans only intervene when necessary, balancing safety with throughput. SuperAnnotate’s 2024 benchmarking study measured the latency overhead of this process at just 150-300ms per reviewed interaction-a negligible delay for most enterprise applications.
Tiered Implementation: Not All Actions Are Equal
One size does not fit all. Reviewing every email an agent drafts would break your budget and slow your team to a halt. Instead, successful implementations use a tiered approach based on risk levels. Gartner projects the HITL sector will reach $3.2B by 2026, driven largely by these nuanced, scalable strategies.
| Risk Level | Example Task | HITL Strategy | Review Frequency |
|---|---|---|---|
| Low | Answering FAQs | Automated + Random Audit | 1-5% of outputs |
| Medium | Scheduling Meetings | Pre-approval for anomalies | When confidence < 90% |
| High | Financial Transfers | Mandatory Pre-approval | 100% of actions |
| Critical | Medical Diagnosis Advice | Dual Human Verification | 100% of actions |
JPMorgan Chase reported in their 2023 AI Transparency Report that this tiered system prevented $1.2M in potential contract analysis errors during its first year while adding only 8% to operational costs. The key is defining those tiers clearly before you start coding.
Technical Stack and Integration
If you’re a developer, you’re probably wondering how to build this. You don’t need to reinvent the wheel. The ecosystem has matured rapidly since 2022. Most teams integrate HITL using Python middleware with frameworks like LangChain is a development framework that simplifies building applications powered by LLMs. Libraries like `langchain-hitl-middleware` (which hit 2,450 stars on GitHub by January 2025) provide ready-to-use components for approval gates.
Key technical requirements include:
- Annotation Interfaces: Clean UIs for reviewers to see context, input, and proposed output.
- API Integration: Seamless connection with OpenAI, Anthropic, or Meta Llama endpoints.
- Monitoring Dashboards: Real-time visibility into rejection rates and common failure modes.
Flowhunt.io’s 2023 technical guide demonstrates that setting up basic approval, editing, and rejection capabilities can be done in weeks, not months. However, security is paramount. IBM’s 2023 security audit found privacy leakage risks in 28% of improperly configured HITL systems. Ensure your human review interface doesn’t expose sensitive customer data unnecessarily.
The Hidden Costs and Human Factors
HITL isn’t free. Splunk’s 2023 analysis estimates the cost at $0.02-$0.05 per human-reviewed interaction. If you’re processing millions of queries, full review could increase operational expenses by 300-500%. That’s why adaptive triggers are essential.
But money isn’t the only cost. There’s a human factor: fatigue. MIT’s Dr. Alan Chen warned in his 2024 NeurIPS presentation that HITL creates new attack surfaces for data leakage and requires careful design to avoid human desensitization. Studies show attention drops by 40% after 45 minutes of continuous monitoring. To combat this, SuperAnnotate recommends rotation schedules with no more than 2 hours of continuous review per session.
Additionally, 63% of developers in SuperAnnotate’s 2024 report cited "clunky interfaces between human review and automated systems" as their top frustration. Invest in good UX for your reviewers. If the tool is hard to use, they’ll rush through reviews, defeating the purpose.

HITL vs. Alternative Safety Methods
Is HITL the only way to keep agents safe? No. But it’s often the most effective for novel edge cases. Let’s compare it to other approaches:
- Constitutional AI: Uses self-critique mechanisms (Anthropic, 2022). Good for general alignment, but lacks real-time human ethical reasoning for unique scenarios.
- Rule-Based Filtering: Blocks keywords or patterns. Fast and cheap, but easily bypassed by creative phrasing.
- Automated Toxicity Detection: Uses secondary models to flag bad content. Misses nuance and context-specific harm.
The arXiv paper 2408.12548v1 reports that HITL-RL frameworks achieved an 89% success rate in complex decision scenarios versus 67% for fully automated systems in autonomous vehicle testing. While that’s not LLMs directly, the principle holds: human judgment excels where rules fail. Traditional automated systems process 100-1000x more queries per hour, creating a trade-off between speed and safety. For low-risk tasks, automate. For high-risk tasks, involve humans.
Regulatory Pressure and Future Trends
The landscape is shifting fast. The EU AI Act, effective February 2026, mandates human oversight for high-risk AI systems. This includes LLM applications in healthcare diagnostics and financial advice. Forrester’s Q4 2024 report shows 38% adoption among enterprises in high-risk domains, with healthcare and finance leading at 52% and 47% respectively.
Looking ahead, Gartner predicts "intelligent triage" systems will reduce human review needs by 65% by 2027. These systems will dynamically adjust based on interaction context, learning which types of errors are truly dangerous and which are harmless quirks. Google’s January 2025 release of 'Safety Layers' for Vertex AI already incorporates real-time human review triggers for sensitive topics, signaling industry-wide movement toward this hybrid model.
Dr. Jane Smith, Director of AI Ethics at Stanford HAI, stated in her 2023 IEEE Spectrum interview: "For any application where errors could cause physical harm or significant financial damage, HITL isn’t optional-it’s an ethical imperative." As LLM agents become more powerful, our responsibility to control them grows equally.
What is the cost of implementing Human-in-the-Loop for LLM agents?
The direct cost ranges from $0.02 to $0.05 per human-reviewed interaction, according to Splunk's 2023 analysis. However, the total cost depends heavily on your review frequency. Using adaptive guardrails to review only low-confidence or high-risk outputs can keep costs manageable. Full review of all outputs may increase operational expenses by 300-500%, which is why tiered approaches are recommended.
How long does it take to set up HITL for an existing AI agent?
Basic implementations using tools like LangChain middleware can take 2-4 weeks, according to SuperAnnotate's 2024 survey. Enterprise-grade systems with custom dashboards and complex risk assessments may require 3-6 months. The timeline depends on your team's familiarity with prompt engineering and workflow design.
Is HITL required by law?
In many jurisdictions, yes. The EU AI Act, effective February 2026, requires human oversight for high-risk AI systems, including those in healthcare and finance. Other regions are following suit. Even where not legally mandated, HITL is considered a best practice for mitigating liability and ensuring ethical operation.
What are the main challenges of HITL implementation?
Key challenges include human reviewer fatigue, integration complexity with existing systems, and determining optimal review thresholds. Clunky interfaces and alert desensitization are common pitfalls. Best practices include rotating reviewers, limiting continuous review sessions to 2 hours, and using clear, intuitive UIs.
How does HITL differ from RLHF?
RLHF (Reinforcement Learning from Human Feedback) is a training method used to align models with human preferences during development. HITL is an operational safety mechanism used during deployment. RLHF shapes the model's behavior long-term, while HITL provides real-time intervention for immediate safety. They work best together: HITL catches errors now, and RLHF learns from those corrections to prevent future ones.