Retrieval-Augmented Generation (RAG) Guide: Build Accurate LLM Apps
 Jun, 12 2026
Jun, 12 2026
You’ve built a chatbot powered by a Large Language Model (LLM) that sounds incredibly smart. It writes emails, summarizes reports, and answers questions with confidence. But then it happens: the model hallucinates. It invents a company policy that doesn’t exist or cites a regulation from 2019 as current law. You’re stuck. Retraining the model is too expensive and slow. Fine-tuning feels like overkill for data that changes weekly. This is where Retrieval-Augmented Generation (RAG) comes in.
RAG isn’t just a buzzword; it’s the architectural standard for making AI trustworthy. By connecting your LLM to your own private data sources, you give it access to real-time facts without touching the model’s core weights. In this guide, we’ll walk through exactly how RAG works, why it beats fine-tuning for most business cases, and how to build an end-to-end pipeline that actually delivers accurate results.
What Is Retrieval-Augmented Generation?
At its core, Retrieval-Augmented Generation (RAG) is a technique that allows Large Language Models to retrieve external information before generating a response. Think of it like giving a student permission to open their textbooks during an exam. Instead of relying solely on what they memorized (the pre-trained weights), they look up specific facts (your documents) and use their reasoning skills (the LLM) to answer the question correctly.
Without RAG, an LLM is limited to its training cutoff date. If you ask it about a product launch last month, it won’t know. With RAG, the system fetches that product page, feeds it into the prompt, and generates an answer based on fresh data. According to industry data from IBM, this approach reduced incorrect responses in customer support scenarios by 40% while cutting the need for expensive model retraining.
The magic lies in the separation of concerns. The LLM handles language understanding and generation. Your retrieval system handles fact-finding. This keeps the model lightweight and ensures every answer can be traced back to a source document.
How RAG Works: The End-to-End Pipeline
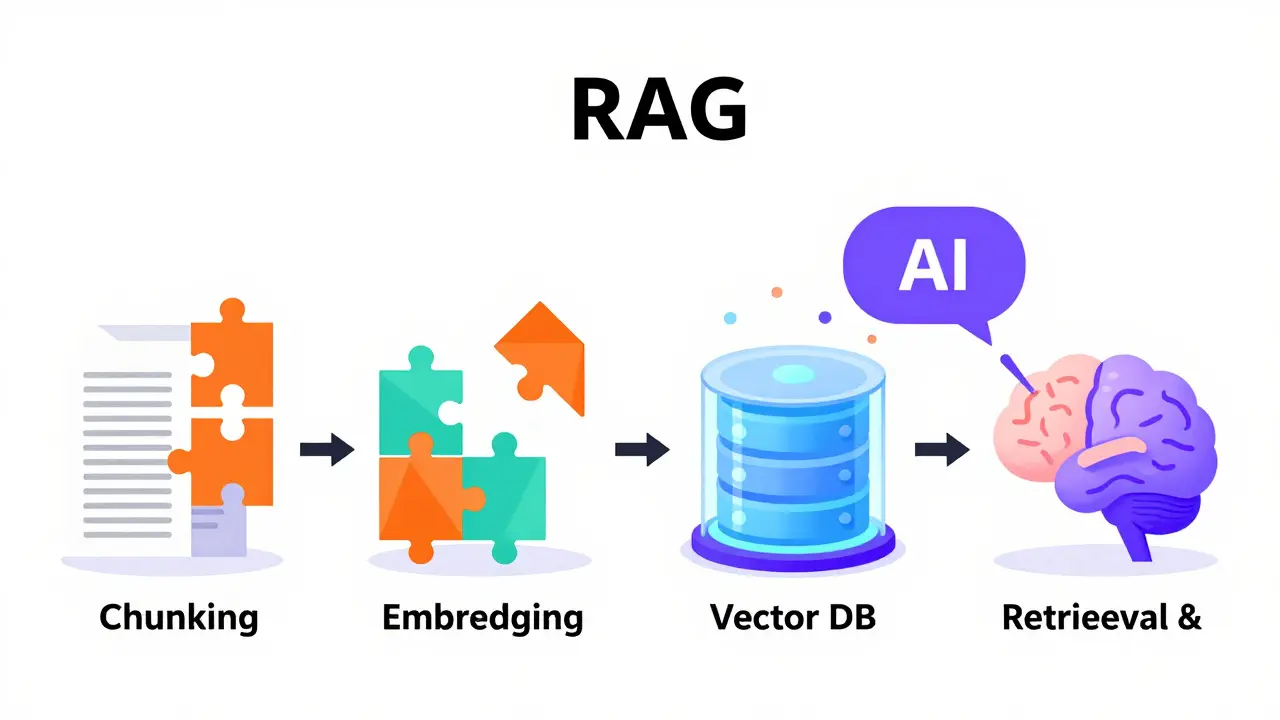
Building a RAG system involves four distinct stages. Understanding these steps is crucial because failure usually happens in the preparation phase, not the generation phase.
- Data Ingestion and Chunking: You start with raw documents-PDFs, Word files, web pages. These are broken down into smaller pieces called chunks. If you chunk too large, the context window gets noisy. Too small, and you lose meaning. A common starting point is 512 tokens with a 50-token overlap, but semantic chunking (splitting at natural sentence boundaries) often yields better results.
- Embedding Creation: Each text chunk is converted into a vector-a long list of numbers representing its meaning. This is done using an embedding model like OpenAI’s
text-embedding-ada-002. These vectors turn text into math that computers can compare quickly. - Vector Storage: These vectors are stored in a specialized Vector Database such as Pinecone, Weaviate, or Milvus. Unlike traditional SQL databases that match exact keywords, vector databases find similar meanings. If you search for “car accident,” it will also retrieve documents discussing “vehicle collision.”
- Retrieval and Augmentation: When a user asks a question, the query is also turned into a vector. The database finds the top-k most similar chunks (usually 3-5). These chunks are appended to the original prompt along with instructions like “Answer only using the provided context.” The LLM then generates the final response.
RAG vs. Fine-Tuning: Which Should You Choose?
This is the most common debate in enterprise AI. Here is the simple rule: Use RAG for knowledge-intensive tasks and fine-tuning for style or behavior adjustments.
| Feature | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
|---|---|---|
| Data Freshness | Real-time updates via database refresh | Stale until next training cycle |
| Cost | Lower ($$$ for infrastructure) | High ($$$$ for compute/training) |
| Hallucination Control | High (answers grounded in sources) | Low (model still guesses if unsure) |
| Latency | Higher (+200-400ms for retrieval) | Lower (direct inference) |
| Transparency | Cites specific source documents | No source citation possible |
Fine-tuning teaches the model *how* to speak (tone, format, jargon). RAG teaches the model *what* to say (facts, policies, data). For most businesses needing accurate, auditable answers, RAG is the clear winner. Gartner reports that 82% of organizations implementing LLMs for knowledge work choose RAG as their primary strategy.
Key Components of a Robust RAG System
To move beyond a basic prototype, you need to optimize three critical components:
- The Embedding Model: This is the bridge between text and vector space. Generic models work okay, but domain-specific embeddings perform better. If you’re in healthcare, use a model trained on medical literature. The choice here dictates retrieval accuracy more than anything else.
- The Vector Database: Speed matters. As your dataset grows to millions of documents, naive similarity searches become slow. Modern vector databases use Approximate Nearest Neighbor (ANN) algorithms to return results in milliseconds. Look for features like hybrid search (combining keyword BM25 scores with vector similarity) to catch exact matches that semantic search might miss.
- The Orchestrator: Frameworks like LangChain or LlamaIndex handle the plumbing. They manage the flow from query to retrieval to prompting. Using a framework saves weeks of development time by providing pre-built connectors for various data sources and LLM providers.
Common Pitfalls and How to Avoid Them
Even experienced teams stumble on RAG implementation. Here are the biggest traps:
Chunking Fragmentation: If you slice a document arbitrarily, you might cut a sentence in half or separate a header from its content. This leads to confused retrievals. Solution: Use semantic chunking libraries that respect paragraph breaks and headings. Aim for chunks that contain complete thoughts.
Irrelevant Retrieval: Sometimes the database returns documents that are semantically close but factually wrong for the specific question. Solution: Implement a relevance scoring threshold. If the top retrieved documents score below a certain similarity metric, instruct the LLM to say “I don’t have enough information” rather than guessing.
Context Window Overflow: Retrieving too many chunks can exceed the LLM’s context limit or dilute the signal with noise. Solution: Start with top-3 or top-5 chunks. Use reranking models to sort retrieved documents by relevance before sending them to the LLM. This adds a small step but significantly boosts answer quality.
Future Trends: Where RAG Is Heading
RAG is evolving rapidly. We are moving past simple retrieval into more sophisticated patterns. Hybrid Search combines vector similarity with traditional keyword matching to ensure high precision. Multi-Hop RAG allows the system to make multiple retrieval steps, answering complex questions that require synthesizing information from several different documents.
Additionally, Self-Correcting RAG systems are emerging. These pipelines include a verification step where the LLM critiques its own answer against the retrieved sources before outputting the final result. This reduces hallucinations further and builds user trust. As the EU AI Act and other regulations demand transparency, RAG’s ability to cite sources makes it not just a technical choice, but a compliance necessity.
Is RAG better than fine-tuning for my business?
If your goal is to provide accurate, up-to-date answers based on internal documents, yes. RAG is cheaper, faster to update, and provides source citations. Fine-tuning is better suited for changing the model's tone, style, or teaching it specific formats.
What is the best vector database for RAG?
Popular choices include Pinecone (managed service, easy setup), Weaviate (open-source, flexible), and Milvus (scalable for large datasets). The best choice depends on your team's DevOps capacity and scale requirements.
How do I reduce hallucinations in RAG?
Ensure high-quality retrieval by optimizing chunking strategies and using reranking models. Also, explicitly instruct the LLM in the prompt to answer only using the provided context and to state if the information is missing.
Can RAG work with non-text data?
Yes. Multimodal RAG can process images, audio, and video by converting them into embeddings alongside text. This allows users to ask questions about charts, diagrams, or recorded meetings.
What is the typical latency overhead of RAG?
RAG typically adds 200-400 milliseconds to response time due to the retrieval and embedding steps. For most conversational applications, this delay is imperceptible to users, but it may matter for high-frequency trading or real-time gaming bots.