Sparse Mixture-of-Experts (MoE) in Generative AI: The Key to Efficient Scaling
 May, 31 2026
May, 31 2026
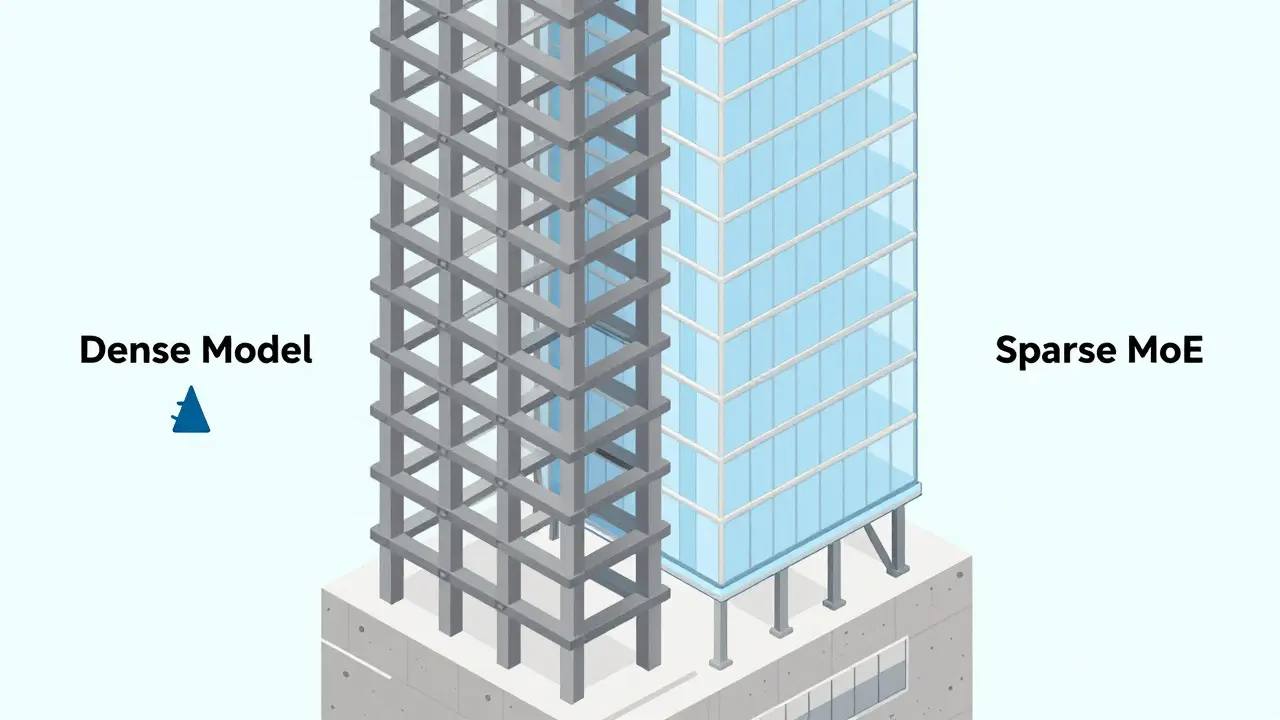
Imagine building a skyscraper. You could build it entirely out of steel, making every floor identical and robust but incredibly expensive. Or, you could use a smart framework where different materials are used only where needed-concrete for the foundation, glass for the facade, steel for the support beams. In the world of Generative AI, which is the technology enabling machines to create new content like text, images, and code based on learned patterns, we’ve been stuck with the 'all-steel' approach for too long. This is known as dense modeling. Now, the industry is shifting toward a smarter, more efficient architecture called Sparse Mixture-of-Experts (MoE), which is a machine learning architecture that divides a model into specialized subnetworks, activating only a subset for each input to reduce computational cost while maintaining high performance.
This isn't just a minor tweak; it’s a fundamental shift in how we scale artificial intelligence. As of May 2026, MoE has moved from experimental research to the backbone of leading commercial models. It allows us to train models with hundreds of billions of parameters without burning through infinite energy or requiring supercomputers for every inference request. If you’re involved in AI development, deployment, or strategy, understanding MoE is no longer optional-it’s essential.
How Sparse Mixture-of-Experts Works
To understand why MoE is such a big deal, you need to look at what happens inside a standard transformer model. In a dense model, every single parameter is activated for every single token (word or piece of data) you process. If you have a 70-billion-parameter model, all 70 billion weights are working hard for every word you type. That’s computationally heavy.
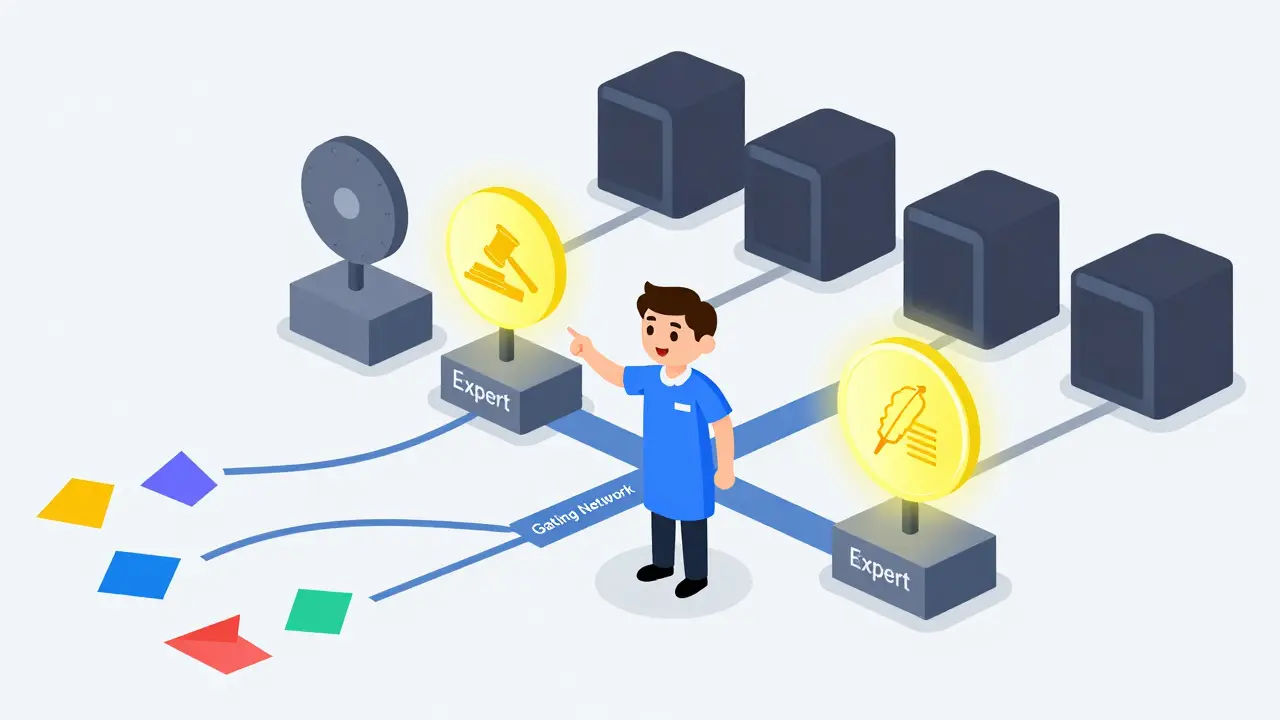
Mixture-of-Experts changes this by splitting the feed-forward network layers into multiple smaller networks, called 'experts.' Think of these experts as specialists in a hospital. One expert might be great at medical terminology, another at legal jargon, and another at creative writing. When you send a prompt to the model, a Gating Network, which is a neural network component that determines which expert subnetworks should process a specific input token acts like a triage nurse. It looks at your input and decides, "This sentence needs the legal expert and the general language expert." Only those two experts wake up and do the work. The other six experts stay asleep, saving massive amounts of compute power.
The magic lies in the sparsity. In a typical setup like Mistral AI’s Mixtral 8x7B, there are eight experts, but only two are activated per token. This means the model has 46.7 billion total parameters, but only about 12.9 billion are active during any given calculation. You get the knowledge depth of a huge model with the speed and cost of a medium-sized one.
The Core Components of MoE Architecture
Building an MoE model involves three critical parts working in harmony:
- Expert Networks: These are usually standard feed-forward neural networks. They mirror the structure of traditional transformers but operate independently.
- The Gating Mechanism: This is the traffic director. Modern implementations use 'noisy top-k gating,' a technique introduced in the seminal 2017 paper by Shazeer et al. It adds a small amount of random noise to the probability scores before selecting the top-k experts (usually k=1 or k=2). This randomness helps prevent the model from always picking the same few experts, ensuring a balanced workload.
- Combination Function: Once the selected experts process the input, their outputs are weighted and merged back together to form the final output for that token.
A key challenge here is 'expert collapse,' where the gate starts favoring one or two experts exclusively, leaving others useless. To fix this, developers use load balancing loss-a mathematical penalty that forces the model to distribute tokens evenly across all experts over time. Without this, your 'specialists' would become redundant, and you’d lose the efficiency benefits.
| Feature | Dense Transformer (e.g., Llama2-70B) | Sparse MoE (e.g., Mixtral 8x7B) |
|---|---|---|
| Total Parameters | 70 Billion | 46.7 Billion |
| Active Parameters per Token | 70 Billion | ~12.9 Billion |
| Inference Speed | Slower (high compute load) | Faster (comparable to 13B dense model) |
| Training Complexity | Standard | High (requires load balancing) |
| Hardware Efficiency | Good for GPUs | Challenging (memory bandwidth bound) |
Why MoE Is Winning the Scaling Race
The primary driver for MoE adoption is simple economics. Training large language models (LLMs) has become prohibitively expensive. Doubling the size of a dense model roughly doubles the compute cost. With MoE, you can increase the total parameter count significantly-adding more experts-without proportionally increasing the inference cost. This is known as conditional computation.
Consider the real-world impact. Mistral’s Mixtral 8x7B achieves benchmark scores similar to Meta’s Llama2-70B, a model nearly five times larger in active parameters. Yet, Mixtral uses only about 28% of the computational resources during inference. For enterprises deploying AI, this translates directly to lower cloud bills and faster response times. According to IDC’s Q4 2024 analysis, MoE now represents 42% of all enterprise LLM deployments exceeding 10 billion parameters. Financial services firms, in particular, love it because dedicated experts can handle specialized transaction patterns with high accuracy, leading to a 68% adoption rate in fraud detection systems.
Moreover, MoE enables multimodal capabilities more efficiently. Google’s LIMoE (Large-scale Multimodal Mixture-of-Experts), announced in March 2023, processes both images and text using a single sparse architecture. It achieved 88.9% accuracy on ImageNet while using only 25% additional computation compared to single-modality models. This versatility makes MoE ideal for the next generation of AI assistants that need to see, hear, and speak simultaneously.
Challenges and Pitfalls of Implementation
Despite its advantages, MoE isn’t a silver bullet. Implementing it comes with significant hurdles that many teams underestimate.
Training Instability: During the early phases of training, the gating network can be erratic. Tokens might flood into one expert, causing gradient explosions or vanishing gradients. Developers often report spending 2-3 extra weeks just tuning the gating parameters (like temperature τ and noise scale) to stabilize training. A common issue is routing instability, which accounts for 32% of open issues in major MoE frameworks like Hugging Face Transformers and NVIDIA NeMo.
Hardware Mismatch: Current GPUs are optimized for dense matrix multiplications. Sparse activation patterns don’t align perfectly with tensor cores, leading to underutilization. Dr. Tim Dettmers from the University of Washington warned in late 2023 that increased memory bandwidth requirements can negate computational savings on older hardware. You need high-bandwidth memory (HBM) GPUs like the NVIDIA A100 or H100 to truly benefit from MoE. On consumer hardware, like an RTX 4090, running Mixtral 8x7B requires aggressive quantization (e.g., 4-bit) to achieve usable speeds (~18 tokens/second).
Load Balancing Overhead: Maintaining equal usage across experts requires constant monitoring and adjustment. If not managed correctly, you end up with 'zombie experts' that never get activated, wasting memory. Emerging solutions include expert merging strategies, where frequently used experts are periodically combined to update less-used ones, but this adds complexity to the training pipeline.
Future Trends: Where MoE Is Heading in 2026 and Beyond
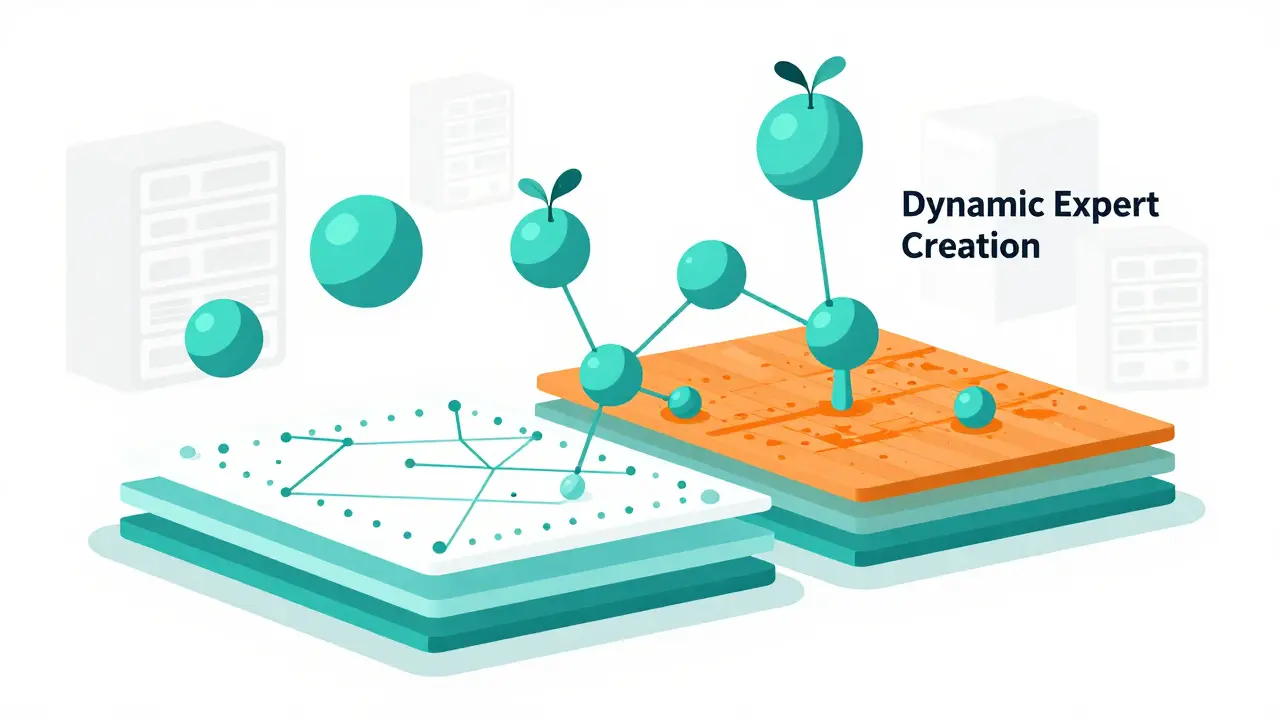
As we move through 2026, MoE is evolving rapidly. The static 'fixed set of experts' model is giving way to more dynamic approaches. Google’s Pathways MoE, announced in March 2025, introduces dynamic expert creation during training, allowing the model to grow its specialization capacity organically rather than being limited by initial design.
Three key trends are shaping the future:
- Hybrid Architectures: About 37% of new MoE implementations now combine sparse MoE layers with dense layers. This balances the efficiency of sparsity with the stability and simplicity of dense processing for certain tasks.
- Cross-Layer Expert Sharing: Instead of having unique experts for every transformer layer, some architectures reuse the same expert networks across multiple layers. This reduces the total parameter count by 15-22% while maintaining performance.
- Hardware-Aware Routing: New routing algorithms consider real-time GPU memory availability when selecting experts. This optimizes inference latency in distributed systems, preventing bottlenecks when certain experts are heavily loaded on specific nodes.
Industry analysts predict that by 2027, 90% of commercially deployed LLMs with more than 50 billion parameters will incorporate MoE techniques. However, caution is advised. Stanford HAI researchers note that computational savings diminish as models scale beyond 1 trillion parameters due to communication overhead between experts. This suggests a ceiling to pure MoE scaling, potentially requiring hybrid or novel architectural innovations for the exascale era.
Practical Advice for Adopting MoE
If you’re considering switching to or building with MoE, here’s what you need to know:
- Start with Pre-trained Models: Don’t train from scratch unless necessary. Use models like Mixtral 8x7B or Mistral Large as a base. Fine-tuning is far less complex than pre-training.
- Monitor Load Balance: Set up dashboards to track expert utilization rates. If one expert handles >30% of tokens, adjust your load balancing loss coefficient immediately.
- Invest in Memory Bandwidth: Ensure your infrastructure has high-speed interconnects (NVLink) and ample HBM. CPU-GPU transfer bottlenecks will kill your performance gains.
- Use Quantization Wisely: For inference, 4-bit or 8-bit quantization works well with MoE, allowing deployment on cheaper hardware without significant accuracy drops.
The shift to sparse Mixture-of-Experts is not just a technical upgrade; it’s a strategic necessity for sustainable AI growth. By leveraging specialization and conditional computation, organizations can access the power of trillion-parameter models without the astronomical costs of dense architectures. The question is no longer whether to adopt MoE, but how quickly you can integrate it into your workflow.
What is the main difference between dense and sparse MoE models?
In dense models, all parameters are activated for every input token, leading to high computational costs. In sparse MoE models, only a small subset of 'expert' subnetworks is activated per token, significantly reducing compute and memory usage while maintaining high total parameter counts for better knowledge retention.
Is Mixtral 8x7B a good example of MoE?
Yes, Mixtral 8x7B is one of the most successful open-source MoE models. It contains 46.7 billion total parameters but activates only ~12.9 billion per token, offering performance comparable to much larger dense models like Llama2-70B at a fraction of the inference cost.
What are the hardware requirements for running MoE models?
MoE models benefit from high memory bandwidth GPUs like NVIDIA A100 or H100 for training. For inference, they can run on consumer hardware like RTX 4090s if quantized (e.g., 4-bit), though performance may be slower than on enterprise-grade hardware due to memory bandwidth constraints.
What is 'expert collapse' in MoE training?
Expert collapse occurs when the gating network consistently routes inputs to only a few experts, leaving others unused. This reduces model capacity and efficiency. It is mitigated using load balancing loss functions that penalize uneven expert utilization during training.
Will MoE replace dense models entirely?
Not entirely. While MoE dominates large-scale models (>30B parameters), dense models remain simpler to train and optimize for smaller scales. Hybrid architectures combining both are becoming popular to balance efficiency and stability. However, for enterprise-scale LLMs, MoE is becoming the standard.