
Fine-Tuned Models for Niche Stacks: When Specialization Beats General LLMs
Discover when fine-tuned models outperform general LLMs in niche stacks. Learn about QLoRA efficiency, accuracy benchmarks, and risks of over-specialization.
Discover when fine-tuned models outperform general LLMs in niche stacks. Learn about QLoRA efficiency, accuracy benchmarks, and risks of over-specialization.
Explore how Reinforcement Learning from Prompts automates LLM optimization. Learn about PRewrite, PRL frameworks, resource costs, and when to deploy iterative prompt refinement strategies.

Explore the end-to-end AI content lifecycle, from creation to archive. Learn how to use Generative AI for scalable, compliant, and evergreen content strategies.
Explore how to orchestrate thousands of GPUs for LLM training, overcoming communication bottlenecks with hybrid parallelism strategies and modern hardware like NVIDIA H200.
Learn how to identify and stop Model Denial-of-Service attacks targeting LLM APIs in 2026. Understand attack vectors like input crafting and safeguard exploitation, plus essential prevention strategies.
Learn how prompt chaining breaks complex tasks into reliable steps to reduce AI hallucinations and improve accuracy in enterprise workflows.

Understand the legal obligations for making generative AI compliant. Explore how WCAG, ADA, and assistive technology requirements apply to AI output and testing strategies.

Learn how to choose the right embedding dimensionality for your RAG system. We cover the trade-offs between accuracy and cost, common model dimensions, and optimization techniques like quantization and MRL.
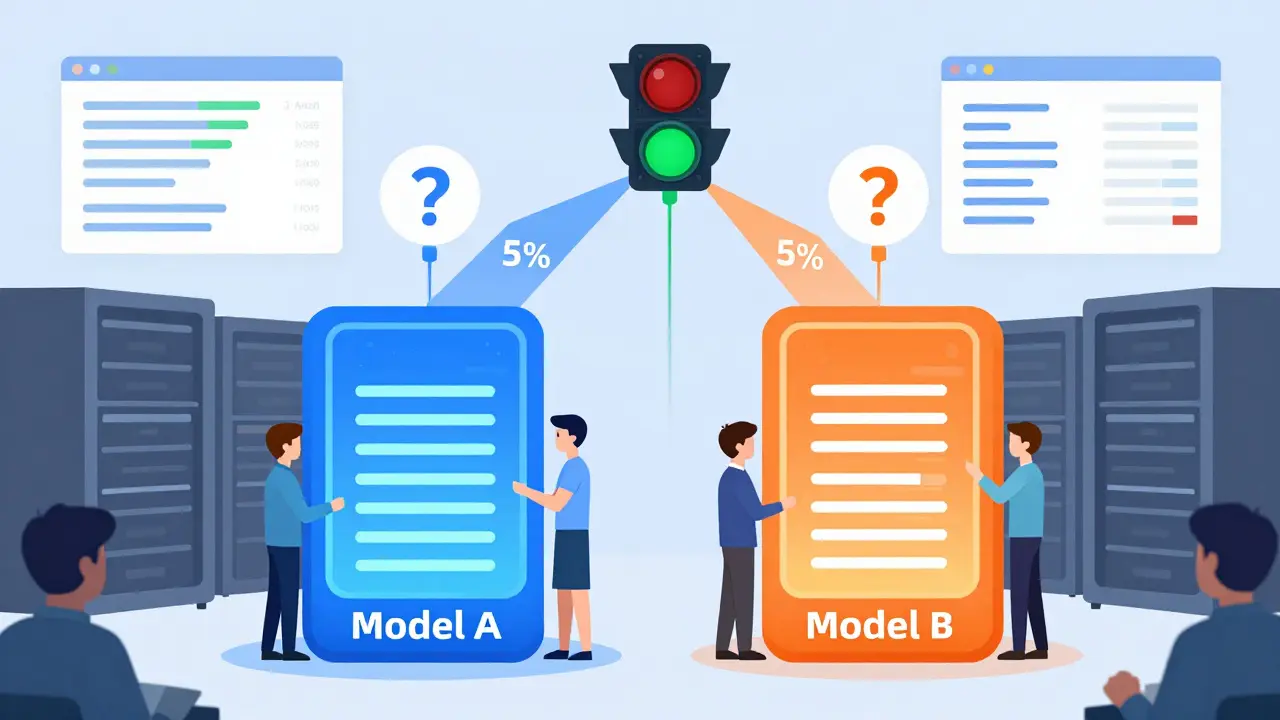
Traffic shaping and A/B testing for LLM releases are essential for safely deploying AI models in production. Learn how controlled traffic rollout, semantic routing, and real-time metrics prevent deployment failures and ensure model quality.

Open-source generative AI models like LLaMA 3 and Stable Diffusion are powering innovation worldwide, but licensing, hardware, and governance challenges remain. Learn how community-driven AI is reshaping access, performance, and trust.

Robustness and generalization tests ensure large language models perform reliably under real-world conditions, not just on clean benchmarks. Learn how adversarial attacks, out-of-distribution data, and calibration impact LLM reliability.

Chain-of-Thought prompting improves AI coding by forcing models to explain their reasoning step by step before generating code. This reduces errors, cuts debugging time, and builds trust - but only when used for complex logic. Learn how to apply it effectively.