Statistical NLP vs Neural NLP: Why Large Language Models Rewrote the Playbook
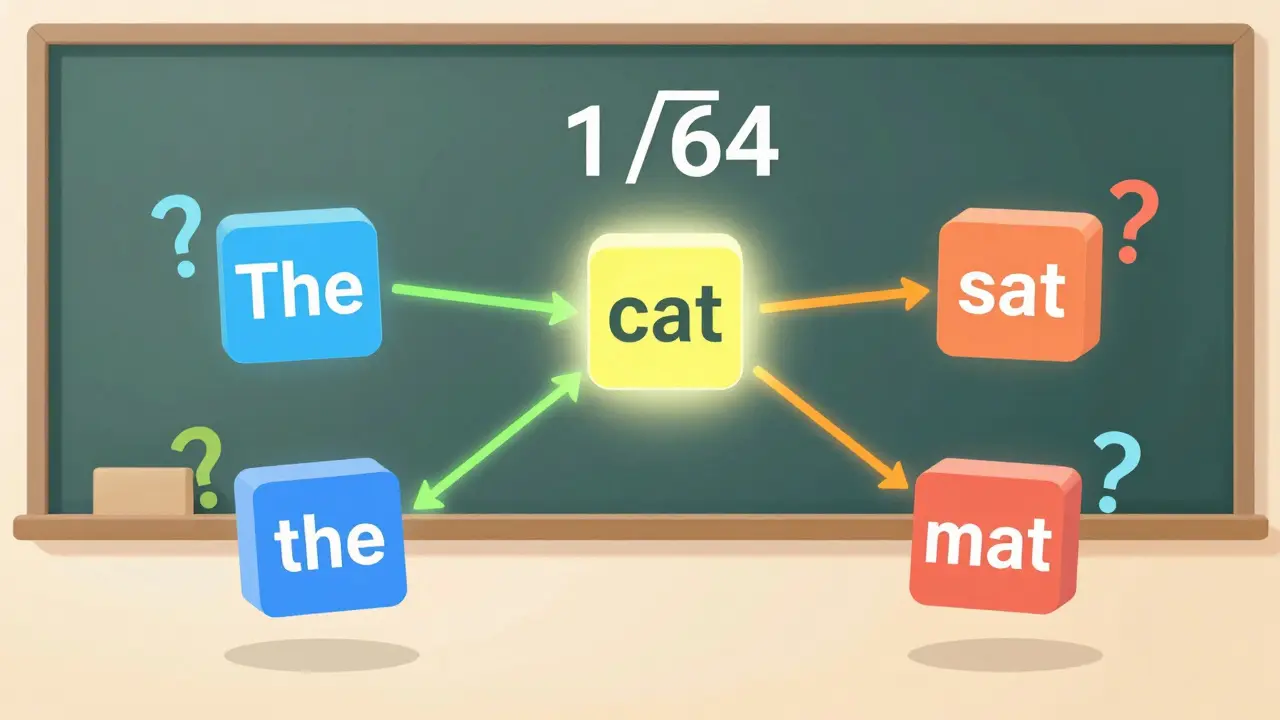
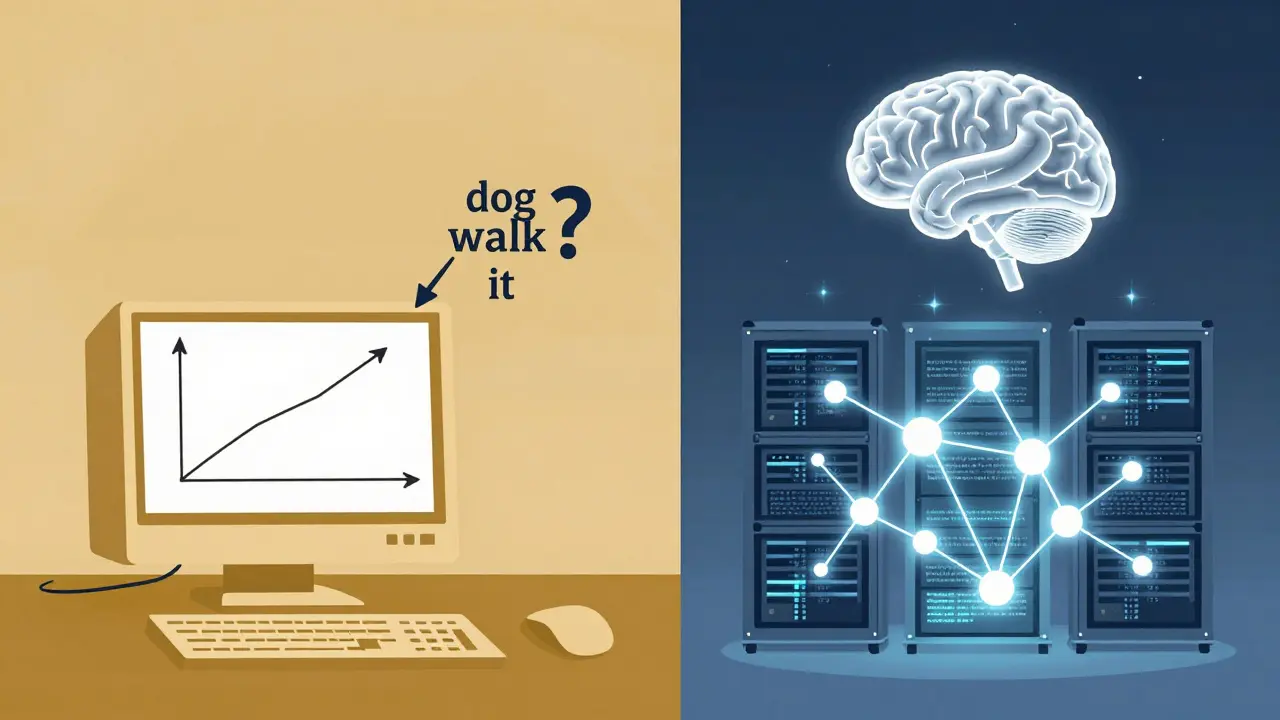
Statistical NLP relied on counting word patterns, while neural NLP and large language models learned context from massive data. LLMs now dominate, but statistical methods still power critical systems where explainability matters.