
Supply Chain Security in Vibe Coding: Managing Dependencies, SBOMs, and Updates
Secure your AI-accelerated workflows. Learn how to manage dependencies, generate accurate SBOMs, and prevent supply chain attacks in vibe coding environments.
Secure your AI-accelerated workflows. Learn how to manage dependencies, generate accurate SBOMs, and prevent supply chain attacks in vibe coding environments.

Discover how generative AI is transforming travel in 2026. From instant itineraries and hyper-personalized offers to proactive service recovery, learn how AI reshapes the hospitality industry.

Learn how chain-of-thought prompting boosts LLM accuracy on complex reasoning tasks. Discover implementation tips, model size requirements, and real-world examples.

Explore the technical evolution of generative AI, from Andrey Markov's 1913 probability chains to the 2017 transformer breakthrough. Understand how LSTMs, GANs, and scaling laws shaped the modern AI landscape.

Learn how to avoid LLM vendor lock-in by implementing model-agnostic proxies and migrating to self-hosted infrastructure. Discover the 5 classes of LLM sovereignty and practical steps to reduce API costs.

Explore why functional vibe-coded apps often hide critical security flaws like hardcoded secrets and client-side auth issues. Learn how to mitigate these risks in AI-generated code.
Learn how to combine Domain-Driven Design with Vibe Coding to build scalable systems. Master bounded contexts and ubiquitous language to reduce technical debt and integration errors in AI-assisted development.

The 2025 COPPA update mandates separate parental consent for AI training of children's data, bans indefinite retention, and expands biometric definitions. Learn how to comply by April 2026.

Discover how generative AI transforms performance reviews and career paths in HR. Learn about tools like Lattice, benefits like reduced bias, and risks to watch for in 2026.
Explore the critical gaps in today's vibe coding tools, including architectural blind spots, governance issues, and context limits. Learn what the next wave of AI development platforms must deliver to succeed.
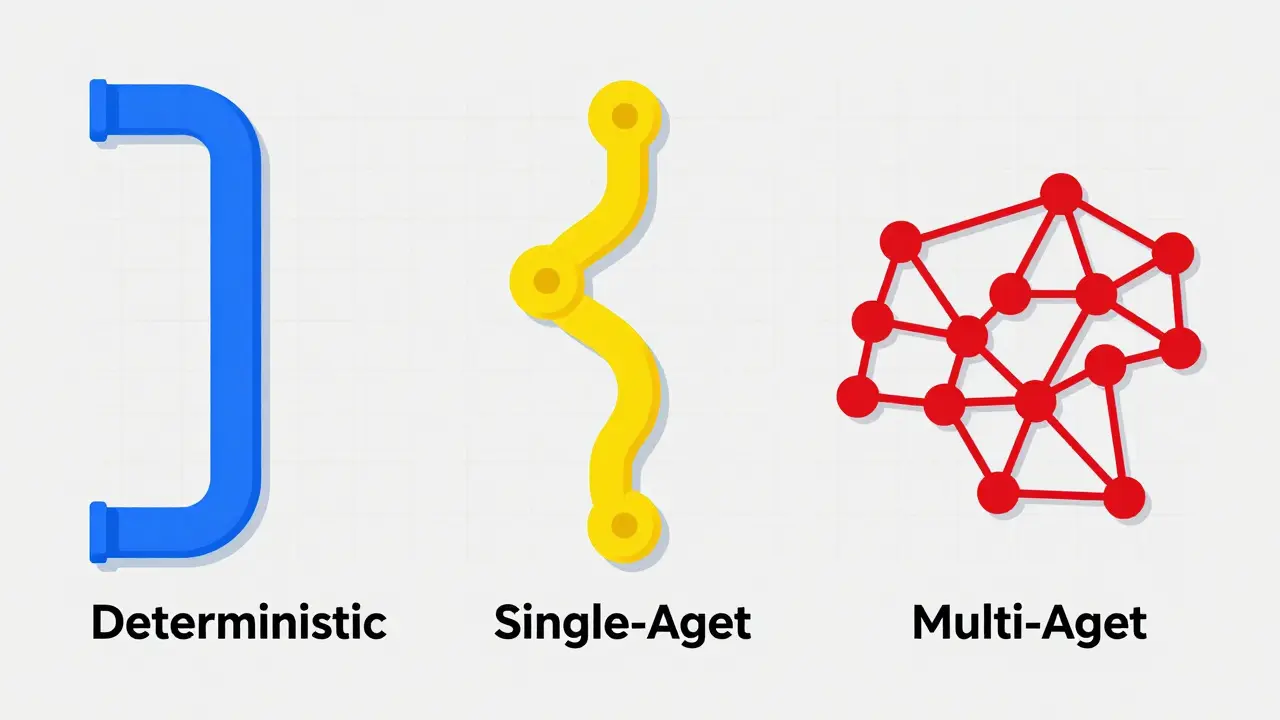
Explore essential design patterns for building safe, reliable, and maintainable LLM agents. Learn how to balance autonomy with security, prevent prompt injection, and choose the right architecture for your enterprise needs.

Explore how generative AI transforms investment scenario modeling. Learn to navigate best, base, and worst-case cases with dynamic, probabilistic forecasting that outperforms traditional static methods.